Clear Sky Science · nl
Onderzoek naar identificatiemethode en toepassing van onveilig gedrag van kolenmijnpersoneel
Waarom het observeren van mijnwerkers met camera’s levens kan redden
Diep onder de grond werken kolenwerkers in krappe, donkere tunnels waar een enkele misstap een ernstig ongeluk kan veroorzaken. Deze studie laat zien hoe slimmer computer vision videostreams uit mijnen in real time kan scannen, risicovol gedrag kan herkennen — zoals het niet dragen van een helm of het betreden van gevarenzones — en zo kan helpen incidenten te voorkomen. Door korrelig ondergronds beeldmateriaal om te zetten in heldere signalen voor veiligheidsteams, wijst het onderzoek op een toekomst waarin technologie constant werknemers ver onder de oppervlakte bewaakt.
Drie soorten risicovolle keuzes ondergronds
De auteurs beginnen met de vraag hoe “onveilig gedrag” er in een kolenmijn concreet uitziet. Ze verdelen de meest voorkomende problemen in drie gemakkelijk te begrijpen typen. Object-typen betreffen apparatuur en uitrusting, zoals het niet dragen van een helm of gereedschap dat rondslingert en struikelen veroorzaakt. Actie-typen gaan over wat mensen doen, waaronder uitglijden, klimmen over hekken of op transportbanden rijden in plaats van de gangpaden te gebruiken. Gebieds-typen richten zich op waar mensen naartoe gaan, bijvoorbeeld het betreden van gemarkeerde gevarenzones of het verlaten van toegewezen posten zonder toestemming. Dit eenvoudige raamwerk helpt dagelijkse gewoonten te koppelen aan reële veiligheidsrisico’s.

Een realistisch beeld van het leven in een mijn opbouwen
Om een computer gevaar te leren herkennen, moest het team eerst een grote en gevarieerde set beelden samenstellen. Ze verzamelden echte surveillancemateriaal uit werkende mijnen en speelden aanvullende scènes na in een laboratoriumomgeving om ondergrondse omstandigheden te simuleren. Uit deze bronnen bouwden ze een dataset van 31.000 beelden die items, handelingen en gevaarlijke gebieden besloeg. Ze breidden deze uit met technieken zoals spiegelen van afbeeldingen en het aanpassen van helderheid om verschillende cameraposities en lichtomstandigheden te imiteren. Omdat ondergrondse camera’s vaak last hebben van stof, trillingen en weinig licht, gebruikten de onderzoekers ook een deep-learningmethode genaamd DnCNN om ruis uit de beelden te verwijderen, waardoor helmen, lichamen en apparatuurcontouren makkelijker door algoritmen te herkennen zijn.
Machines leren onveilig gedrag te zien
Bovenop deze opgeschoonde en verrijkte dataset ontwierpen de auteurs een systeem voor herkenning van onveilig gedrag op basis van een opgewaardeerde versie van het YOLOv11-objectdetectiemodel. Een onderdeel van het systeem richt zich op het detecteren van mensen en apparatuur, inclusief of een mijnwerker een helm draagt of bij een bepaalde machine staat. Een ander onderdeel, genoemd YOLOv11-Pose, volgt sleutelpunten van het lichaam — zoals schouders, knieën en handen — en gebruikt hun posities over tijd om handelingen af te leiden zoals lopen, bukken of vallen. Door deze twee gezichtspunten te combineren, kan het systeem niet alleen zien wie en wat aanwezig is, maar ook wat ze doen en of ze zich in een risicogebied bevinden.
De digitale veiligheidswacht verfijnen
Het team versterkte het model verder zodat het betrouwbaar werkt in rommelige tunnels. Een module voor functieverbetering helpt het netwerk zich te concentreren op belangrijke regio’s van elk frame en onbelangrijke achtergronddetails te negeren. Ze gebruikten ook een methode genaamd K-means++ om de interne “anchor”-boxen van het model beter af te stemmen op de typische afmetingen en vormen van mijnwerkers en apparatuur die in de videobeelden voorkomen, wat de detectie van kleine of verre figuren verbetert. Door vele trainings- en testronden, inclusief vergelijkingen met eerdere YOLO-versies en andere gangbare modellen, bereikte hun verbeterde systeem hoge nauwkeurigheid: een mean average precision van 95,7 procent, met vergelijkbaar sterke precisie en recall, zelfs wanneer meerdere mijnwerkers, complexe achtergronden en weinig licht aanwezig waren.
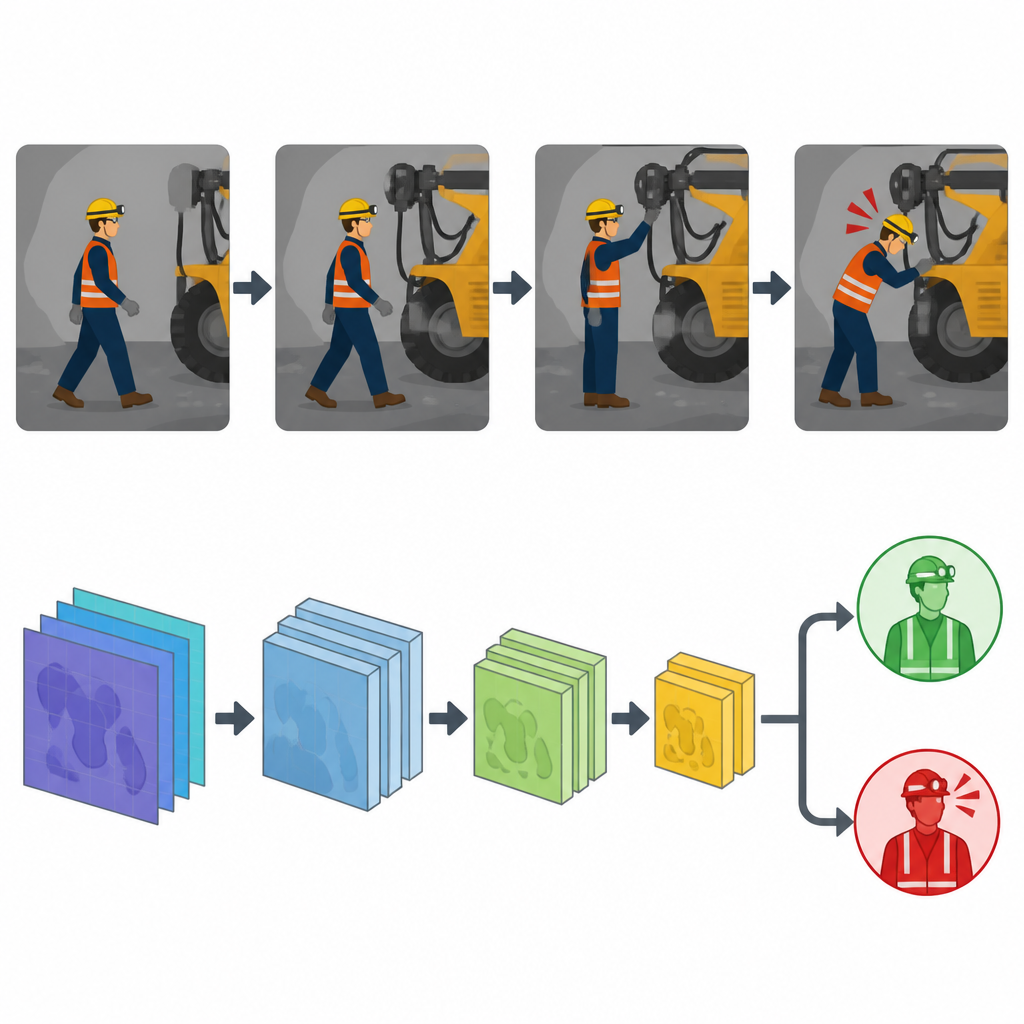
Van slimme waarschuwingen naar veiligere diensten
In dagelijks gebruik kan deze technologie draaien op edge-apparaten nabij de camera’s, live video scannen en snel waarschuwingen versturen wanneer een mijnwerker zonder helm wordt gezien, iemand op een bewegende band rijdt of een persoon een gevarenzone betreedt. De studie toont aan dat met de juiste datavoorbereiding en modelontwerp geautomatiseerde systemen een breed scala aan onveilig gedrag vrijwel direct kunnen herkennen. Hoewel de auteurs opmerken dat er meer werk nodig is om nog complexere scènes aan te kunnen en het systeem op schaal in werkende mijnen te implementeren, suggereren hun resultaten dat continue, intelligente bewaking een krachtige aanvulling kan worden op training en regels om mijnwerkers veiliger te houden.
Bronvermelding: Juan, L., Zhu, Q., Jiang, D. et al. Research on identification method and application of unsafe behavior of coal mine personnel. Sci Rep 16, 15909 (2026). https://doi.org/10.1038/s41598-026-47077-6
Trefwoorden: veiligheid in kolenmijnen, detectie van onveilig gedrag, computer vision, YOLOv11, werknemersbewaking