Clear Sky Science · fr
Recherche sur la méthode d’identification et l’application du comportement dangereux du personnel des mines de charbon
Pourquoi surveiller les mineurs par caméra peut sauver des vies
En profondeur, les mineurs de charbon travaillent dans des galeries étroites et sombres où une seule erreur peut provoquer un accident grave. Cette étude montre comment une vision par ordinateur plus intelligente peut analyser les flux vidéo des mines en temps réel, repérer des comportements à risque comme l’absence de casque ou l’entrée dans des zones dangereuses, et aider à prévenir les incidents avant qu’ils ne surviennent. En transformant des images souterraines granuleuses en signaux exploitables par les équipes de sécurité, la recherche ouvre la voie à un avenir où la technologie veille en permanence sur les travailleurs sous la surface.
Trois types de choix risqués sous terre
Les auteurs commencent par se demander à quoi ressemble réellement le « comportement dangereux » dans une mine de charbon. Ils regroupent les problèmes les plus courants en trois catégories faciles à comprendre. Les problèmes de type objet concernent l’équipement et les accessoires, comme ne pas porter de casque ou laisser des outils éparpillés où l’on peut trébucher. Les problèmes de type action portent sur les gestes des personnes, incluant la glissade, l’escalade de barrières ou le fait de monter sur des convoyeurs au lieu d’emprunter des chemins piétonniers appropriés. Les problèmes de type zone se concentrent sur les endroits où les gens se rendent, comme pénétrer dans des zones dangereuses signalées ou quitter un poste assigné sans autorisation. Ce cadre simple aide à relier les habitudes quotidiennes à des risques d’accidents bien réels.

Construire une image réaliste de la vie en mine
Pour apprendre à l’ordinateur à reconnaître le danger, l’équipe a d’abord dû rassembler un jeu d’images large et diversifié. Ils ont collecté des vidéos de surveillance réelles de mines en activité et ont reconstitué des scènes en laboratoire pour imiter les conditions souterraines. À partir de ces sources, ils ont constitué un ensemble de 31 000 images couvrant objets, actions et zones dangereuses. Ils l’ont ensuite enrichi par des techniques comme le retournement d’images et l’ajustement de la luminosité pour simuler différents angles de caméra et niveaux d’éclairage. Parce que les caméras souterraines peinent souvent avec la poussière, les vibrations et le faible éclairage, les chercheurs ont aussi utilisé une méthode d’apprentissage profond appelée DnCNN pour réduire le bruit des images, rendant plus nettes les silhouettes de casques, de corps et d’équipements pour les algorithmes.
Apprendre aux machines à voir les comportements dangereux
Sur cet ensemble de données nettoyé et enrichi, les auteurs ont conçu un système de reconnaissance des comportements dangereux basé sur une version améliorée du modèle de détection d’objets YOLOv11. Une partie du système se concentre sur la détection des personnes et des équipements, y compris si un mineur porte un casque ou se tient près d’une machine particulière. Une autre partie, appelée YOLOv11-Pose, suit les points clés du corps, comme les épaules, les genoux et les mains, et utilise leurs positions dans le temps pour déduire des actions comme la marche, la flexion ou la chute. En combinant ces deux perspectives, le système peut non seulement identifier qui et quoi est présent, mais aussi ce qu’ils font et s’ils se trouvent dans une zone à risque.
Affiner le gardien numérique
L’équipe a en outre renforcé le modèle pour qu’il fonctionne de manière fiable dans des galeries encombrées. Un module d’amélioration des caractéristiques aide le réseau à se concentrer sur les régions importantes de chaque image tout en ignorant les détails de fond inutiles. Ils ont également utilisé une méthode appelée K-means++ pour mieux adapter les « boîtes d’ancrage » internes du modèle aux tailles et formes typiques des mineurs et des équipements observés dans les vidéos, ce qui améliore la détection des sujets petits ou éloignés. À travers de nombreuses itérations d’entraînement et de tests, y compris des comparaisons avec des versions antérieures de YOLO et d’autres modèles courants, leur système amélioré a atteint une précision élevée : une moyenne de précision (mAP) de 95,7 %, avec une précision et un rappel tout aussi solides, même en présence de plusieurs mineurs, d’arrière-plans complexes et de faible luminosité.
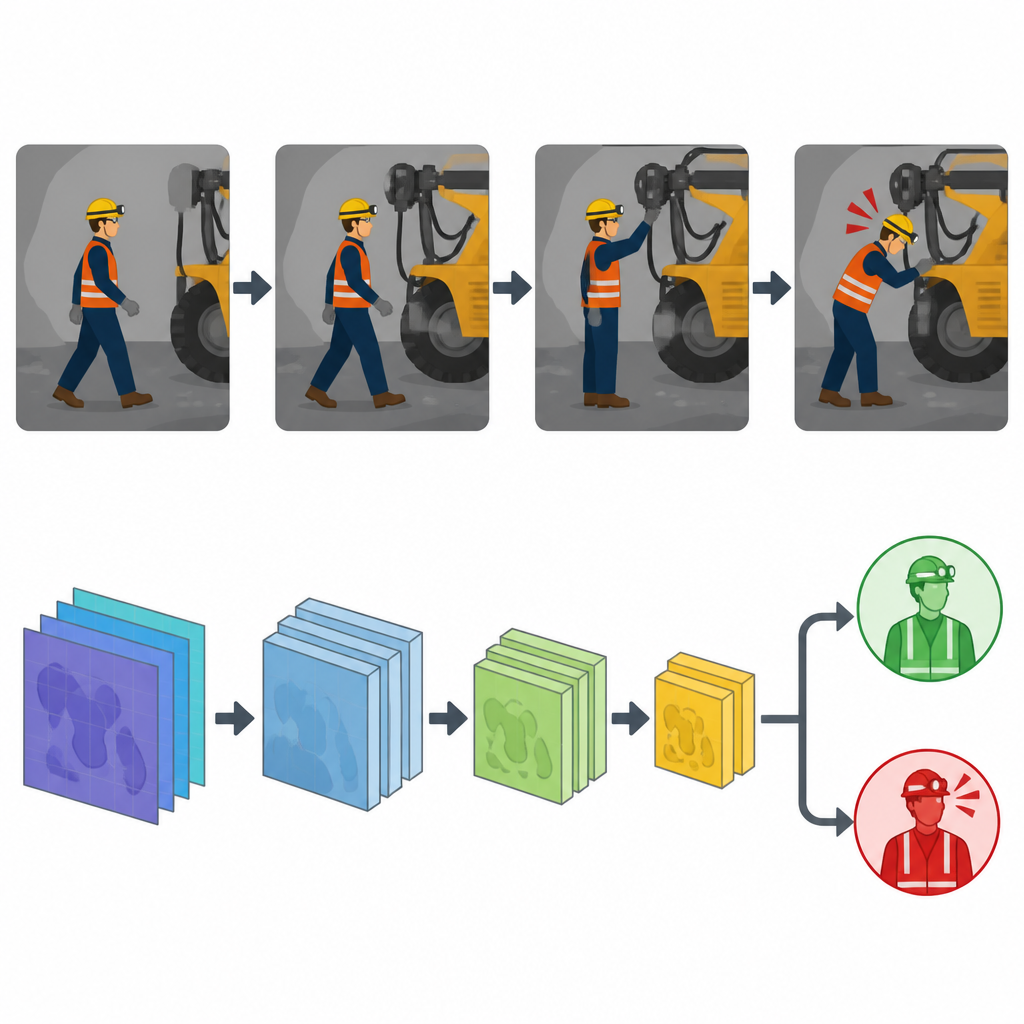
Des alertes intelligentes à des équipes plus sûres
Dans l’usage courant, cette technologie pourrait tourner sur des appareils en périphérie proches des caméras, analyser la vidéo en direct et envoyer des alertes rapides lorsqu’elle détecte un mineur sans casque, une personne sur un convoyeur en mouvement ou quelqu’un entrant dans une zone dangereuse. L’étude montre qu’avec une préparation des données et une conception de modèle adaptées, les systèmes automatisés peuvent reconnaître une large gamme de comportements dangereux presque en temps réel. Les auteurs soulignent qu’il reste du travail pour gérer des scènes encore plus complexes et pour déployer le système à l’échelle dans des mines opérationnelles, mais leurs résultats suggèrent que la surveillance intelligente et continue peut devenir un partenaire puissant des formations et des règles pour protéger les mineurs.
Citation: Juan, L., Zhu, Q., Jiang, D. et al. Research on identification method and application of unsafe behavior of coal mine personnel. Sci Rep 16, 15909 (2026). https://doi.org/10.1038/s41598-026-47077-6
Mots-clés: sécurité des mines de charbon, détection de comportements dangereux, vision par ordinateur, YOLOv11, surveillance des travailleurs