Clear Sky Science · nl
Implementatie van een machine learning-gebaseerd voorspellingssysteem voor kinderdiarree in Sub-Sahara Afrika
Waarom een digitaal hulpmiddel kan helpen jonge levens te redden
Diarree doodt nog steeds veel jonge kinderen in Sub-Sahara Afrika, ondanks het bestaan van eenvoudige behandelingen en preventiemaatregelen. Zorgverleners vinden het vaak lastig om tijdig te signaleren welke kinderen het meest risico lopen. Deze studie beschrijft hoe onderzoekers een computerprogramma omzetten naar een werkend online hulpmiddel dat kwetsbare kinderen vroeg kan aanwijzen, waardoor klinieken en wijkwerkers hun zorg praktisch kunnen richten waar die het meest nodig is.

Gezinnen in een hele regio in kaart brengen
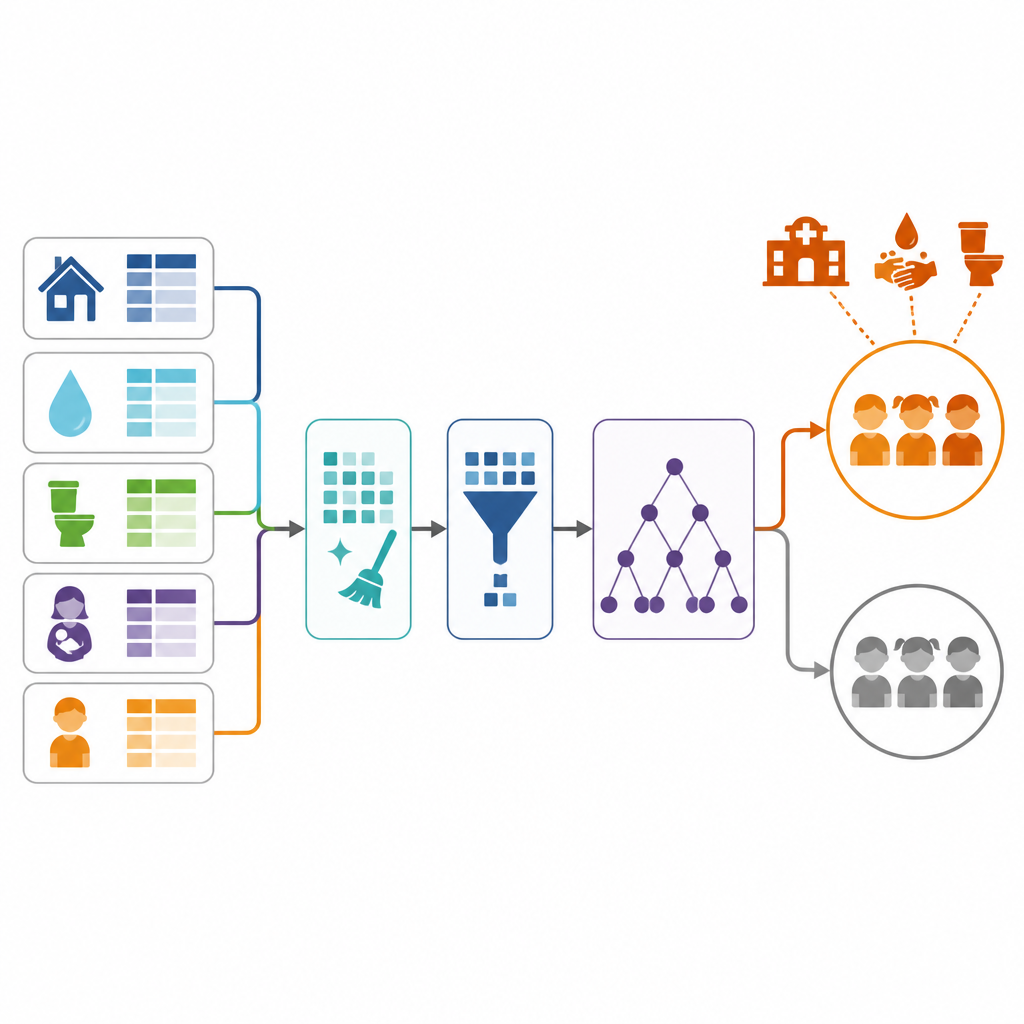
De onderzoekers gebruikten enquêtegegevens van bijna 290.000 kinderen onder de vijf jaar in 27 landen in Sub-Sahara Afrika. Deze nationale enquêtes leggen details vast over kinderen, hun moeders, hun woningen en hun toegang tot zorg en schoon water. Op basis van deze informatie definieerde het team diarree als elke episode die de moeder in de voorgaande twee weken rapporteerde. Vervolgens selecteerden ze een brede reeks mogelijke risicofactoren, variërend van de leeftijd en opleiding van de moeder tot huishoudelijk vermogen, bron van drinkwater, type toilet, kliniekbezoeken en afstand tot gezondheidsvoorzieningen.
Rommelige gegevens omzetten in een risicoscore
Gegevens uit de praktijk zijn zelden netjes: sommige antwoorden ontbreken, veel reacties zijn als tekst opgeslagen en veel minder kinderen melden diarree dan niet. Het team maakte de data zorgvuldig schoon, vulde lacunes met standaard statistische methoden in en zette tekst om in numerieke vormen die computers kunnen verwerken. Omdat diarreegevallen veel zeldzamer waren dan niet-gevallen, gebruikten ze een techniek die realistische synthetische voorbeelden genereert zodat de computer evenveel van zieke als van gezonde kinderen leert. Ze verwijderden ook zwakkere of overlappende variabelen om het model te concentreren op de meest informatieve signalen.
Hoe de voorspellingsmotor werkt
Om te voorspellen welke kinderen waarschijnlijk diarree zullen krijgen, kozen de auteurs voor een methode genaamd Random Forest, die veel eenvoudige beslisbomen combineert tot één eindbeslissing. Ze splitsten de data in trainings- en testdelen, stelden belangrijke modelinstellingen bij en controleerden de prestaties. Het uiteindelijke systeem classificeerde ongeveer vier van de vijf kinderen correct en identificeerde, cruciaal, het merendeel van de werkelijke diarreegevallen. Deze hoge sensitiviteit is belangrijk omdat het missen van een ziek kind levensbedreigende gevolgen kan hebben, terwijl enkele valse alarmen acceptabel zijn als ze extra zorg uitlokken.
Van computercode naar een bruikbaar hulpmiddel
Wat dit werk onderscheidt is niet alleen de nauwkeurigheid van het model, maar ook het feit dat het al als online dienst draait. Met een lichtgewicht webframework pakte het team het model in een applicatie die nieuwe kind- en huishoudgegevens via een eenvoudig webformulier of een gezondheidssysteem kan accepteren. De applicatie geeft vervolgens in realtime een risico-inschatting terug. Een aparte vraag-en-antwoord-chatbot, getraind op richtlijnen voor de volksgezondheid, helpt uitleggen wat de invoer betekent en biedt algemene informatie over kinderdiarree, zonder de voorspellingen van het model te veranderen.
Wat dit betekent voor zorgverleners en gezinnen
Kort gezegd laat de studie zien dat het mogelijk is om complexe data en algoritmen om te zetten in een praktisch hulpmiddel dat hulpverleners in het veld kan helpen eerder te handelen voor de kinderen die het meest waarschijnlijk diarree zullen krijgen. Hoewel het systeem nog veldtests, integratie met nationale gezondheidsplatforms en gebruikersopleiding nodig heeft, illustreert het een duidelijk traject van onderzoek naar actie. Als het verder verfijnd en geadopteerd wordt, kunnen dergelijke hulpmiddelen een slimmer gebruik van beperkte middelen ondersteunen en helpen dat meer kinderen in Sub-Sahara Afrika gezond opgroeien.
Bronvermelding: Taye, E.A., Alemu, E.A., Kebede, H.A. et al. Deployment of a machine learning-based predictive system for childhood diarrhea in Sub-Saharan Africa. Sci Rep 16, 15199 (2026). https://doi.org/10.1038/s41598-026-43140-4
Trefwoorden: kinderdiarree, machine learning, Sub-Sahara Afrika, instrument voor volksgezondheid, risicovoorspelling