Clear Sky Science · fr
Déploiement d’un système prédictif basé sur l’apprentissage automatique pour la diarrhée infantile en Afrique subsaharienne
Pourquoi un outil numérique peut aider à sauver des vies de jeunes enfants
La diarrhée continue de causer la mort de nombreux jeunes enfants en Afrique subsaharienne, malgré l’existence de traitements et de mesures préventives simples. Les agents de santé ont souvent du mal à identifier à temps les enfants les plus à risque. Cette étude décrit comment des chercheurs ont transformé un programme informatique en un outil en ligne opérationnel capable de signaler tôt les enfants vulnérables, offrant aux cliniques et aux travailleurs communautaires un moyen pratique de concentrer les soins là où ils sont le plus nécessaires.

Étudier les familles à l’échelle d’une région entière
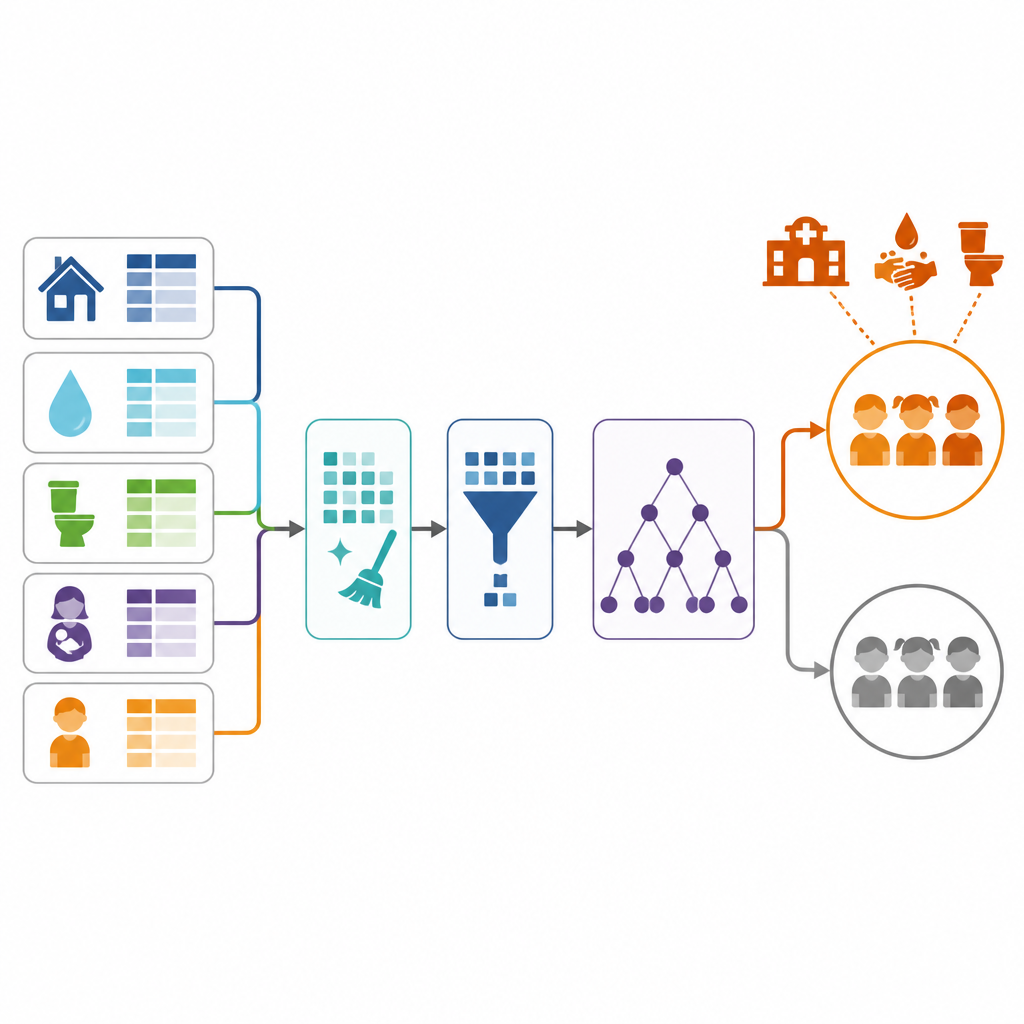
Les chercheurs se sont appuyés sur des données d’enquête provenant de près de 290 000 enfants de moins de cinq ans dans 27 pays d’Afrique subsaharienne. Ces enquêtes nationales recueillent des détails sur les enfants, leurs mères, leurs logements et leur accès aux soins et à l’eau potable. À partir de ces informations, l’équipe a défini la diarrhée comme tout épisode signalé par la mère au cours des deux semaines précédentes. Ils ont ensuite sélectionné un large éventail de facteurs de risque possibles, allant de l’âge et du niveau d’instruction de la mère à la richesse du ménage, la source d’eau potable, le type de toilettes, les visites en clinique et la distance aux structures de santé.
Transformer des dossiers désordonnés en score de risque
Les données du monde réel sont loin d’être propres : certaines réponses manquent, de nombreux éléments sont stockés sous forme de texte et bien moins d’enfants déclarent de la diarrhée que l’inverse. L’équipe a soigneusement nettoyé les données, comblé les lacunes à l’aide de méthodes statistiques standard et converti les mots en valeurs numériques compréhensibles par l’ordinateur. Comme les cas de diarrhée étaient beaucoup plus rares que les non-cas, ils ont utilisé une technique générant des exemples synthétiques réalistes pour que l’ordinateur apprenne aussi bien des enfants malades que des enfants sains. Ils ont également éliminé les variables plus faibles ou redondantes afin de garder le modèle concentré sur les signaux les plus informatifs.
Comment fonctionne le moteur de prédiction
Pour prédire quels enfants sont susceptibles de développer une diarrhée, les auteurs ont choisi une méthode appelée Random Forest, qui combine de nombreux arbres de décision simples pour rendre un verdict final. Ils ont scindé les données en ensembles d’entraînement et de test, ajusté les paramètres clés du modèle et évalué ses performances. Le système final a correctement classé environ quatre enfants sur cinq et, surtout, identifié la majorité des vrais cas de diarrhée. Cette sensibilité élevée est importante car manquer un enfant malade peut avoir des conséquences potentiellement mortelles, alors que certaines fausses alertes sont acceptables si elles entraînent des soins supplémentaires.
Du code informatique à un outil utilisable
Ce qui distingue ce travail n’est pas seulement la précision du modèle, mais le fait qu’il fonctionne déjà comme un service en ligne. À l’aide d’un cadre web léger, l’équipe a emballé le modèle dans une application qui peut recevoir de nouvelles informations sur l’enfant et le ménage via un formulaire web simple ou un système d’information sanitaire. L’application renvoie ensuite une estimation du risque en temps réel. Un chatbot distinct de questions-réponses, entraîné sur des lignes directrices de santé publique, aide à expliquer la signification des entrées et offre des informations générales sur la diarrhée infantile, sans modifier les prédictions du modèle.
Ce que cela signifie pour les agents de santé et les familles
En termes simples, l’étude montre qu’il est possible de transformer des données et des algorithmes complexes en un outil pratique qui pourrait aider le personnel de première ligne à intervenir plus tôt pour les enfants les plus susceptibles de souffrir de diarrhée. Bien que le système nécessite encore des essais sur le terrain, une intégration aux plateformes nationales de santé et une formation des utilisateurs, il illustre une trajectoire claire de la recherche vers l’action. Si ces outils sont affinés et adoptés, ils pourraient permettre une utilisation plus intelligente des ressources limitées, aidant ainsi davantage d’enfants à grandir en bonne santé en Afrique subsaharienne.
Citation: Taye, E.A., Alemu, E.A., Kebede, H.A. et al. Deployment of a machine learning-based predictive system for childhood diarrhea in Sub-Saharan Africa. Sci Rep 16, 15199 (2026). https://doi.org/10.1038/s41598-026-43140-4
Mots-clés: diarrhée infantile, apprentissage automatique, Afrique subsaharienne, outil de santé publique, prévision du risque