Clear Sky Science · nl
Aanpasbare state-feedback echo state-netwerken voor leren van temporele reeksen
Machines leren beter het verleden te onthouden
Veel van wat we van computers willen — van spraakbegrip tot het ontcijferen van signalen uit de hersenen — berust op het herkennen van patronen die zich in de tijd ontvouwen. Dit artikel introduceert een nieuwe manier om een type neuraal netwerk te trainen zodat het deze zich ontwikkelende patronen nauwkeuriger kan onthouden en voorspellen, zonder enorme rekenkracht te vereisen. De methode, AFRICO genoemd, herschikt hoe informatie binnen het netwerk stroomt zodat het complexe, ruisige tijdseries zowel in geconstrueerde systemen als in levende hersenen beter kan volgen.
Waarom reservoir‑hersenen snel maar vergeetachtig zijn
Echo State Networks zijn een gestroomlijnde vorm van recurrente neurale netwerken. In plaats van elke verbinding te trainen vertrouwen ze op een groot “reservoir” van willekeurig verbonden neuronale units die binnenkomende signalen omzetten in een rijke interne echo van eerdere inputs. Alleen de laatste laag die deze activiteit uitleest wordt getraind, wat leren snel en goedkoop maakt. Omdat de interne bedrading echter vast blijft, kan het reservoir zich niet makkelijk aanpassen aan de specifieke patronen van een taak. Eerdere verbeteringen probeerden dit te verhelpen door de eigen output van het netwerk terug te voeren naar het reservoir, maar hielden die feedbackverbindingen doorgaans ook vast. Dat verbetert de prestatie enigszins, maar behandelt het reservoir nog steeds grotendeels als een onveranderlijke black box.
Het netwerk zijn eigen echo’s laten bijstellen
AFRICO verandert dit beeld door het netwerk toe te staan te regelen hoe inputs en interne signalen naar het reservoir worden geleid, terwijl de kern van de recurrente bedrading ongemoeid blijft. Tijdens het trainen duwt een algoritme dat de Extended Kalman Filter heet de sterktes van de input- en feedbackpaden bij, zodat de zich ontwikkelende activiteit van het reservoir beter de dynamiek van het doelsysteem weerspiegelt. In plaats van simpelweg een vaste interne echo te buigen om de gewenste output te bereiken, vormt AFRICO die echo zelf geleidelijk. Een tweede trainingsfase bouwt daarna een sparse readout die slechts een kleine, zorgvuldig gekozen subset van reservoirsignalen met de output verbindt, waardoor het uiteindelijke model zowel efficiënter als makkelijker te interpreteren wordt.
De methode op de proef gesteld
De auteurs hebben AFRICO getest op verschillende veeleisende taken. Eerst gebruikten ze synthetische systemen die door bekende vergelijkingen worden beschreven, beginnend met eenvoudige lineaire dynamica en vervolgens complexere niet-lineaire systemen. In elk geval leerden met AFRICO getrainde netwerken het werkelijke systeem veel nauwkeuriger te volgen dan een veelgebruikte aanpak genaamd FORCE, die alleen de readout traint terwijl de feedback vast blijft. Zelfs wanneer het interne reservoir opzettelijk beperkt werd in dynamisch bereik, herstelde AFRICO het correcte gedrag, terwijl netwerken met vaste feedback na verloop van tijd van het doel afdrijven. De methode bleek ook robuust tegen meetruis en bleef goed werken zelfs wanneer het reservoir relatief weinig neuronen bevatte.
Luisteren naar signalen van een levend oog
Om te laten zien dat de aanpak verder reikt dan voorbeeldcases, pasten de onderzoekers AFRICO toe op elektrische opnamen van fotoreceptoren van fruitvliegen die reageren op natuurlijk licht. Deze cellen zetten visuele input om in voltagesignalen met een rijke temporele structuur. Met slechts een handvol reservoirunits legde AFRICO de fijnmazige timing van de fotoreceptorrespons veel beter vast dan netwerken met vaste feedback, en deed dat met een readout die slechts een klein deel van alle mogelijke verbindingen gebruikte. De methode blonk ook uit op een uitdagende benchmarktaak bekend als NARMA10, die het modelleren van ingewikkelde, langeafstandsafhankelijkheden in een synthetisch signaal vereist — iets waar veel reservoirgebaseerde methoden moeite mee hebben.
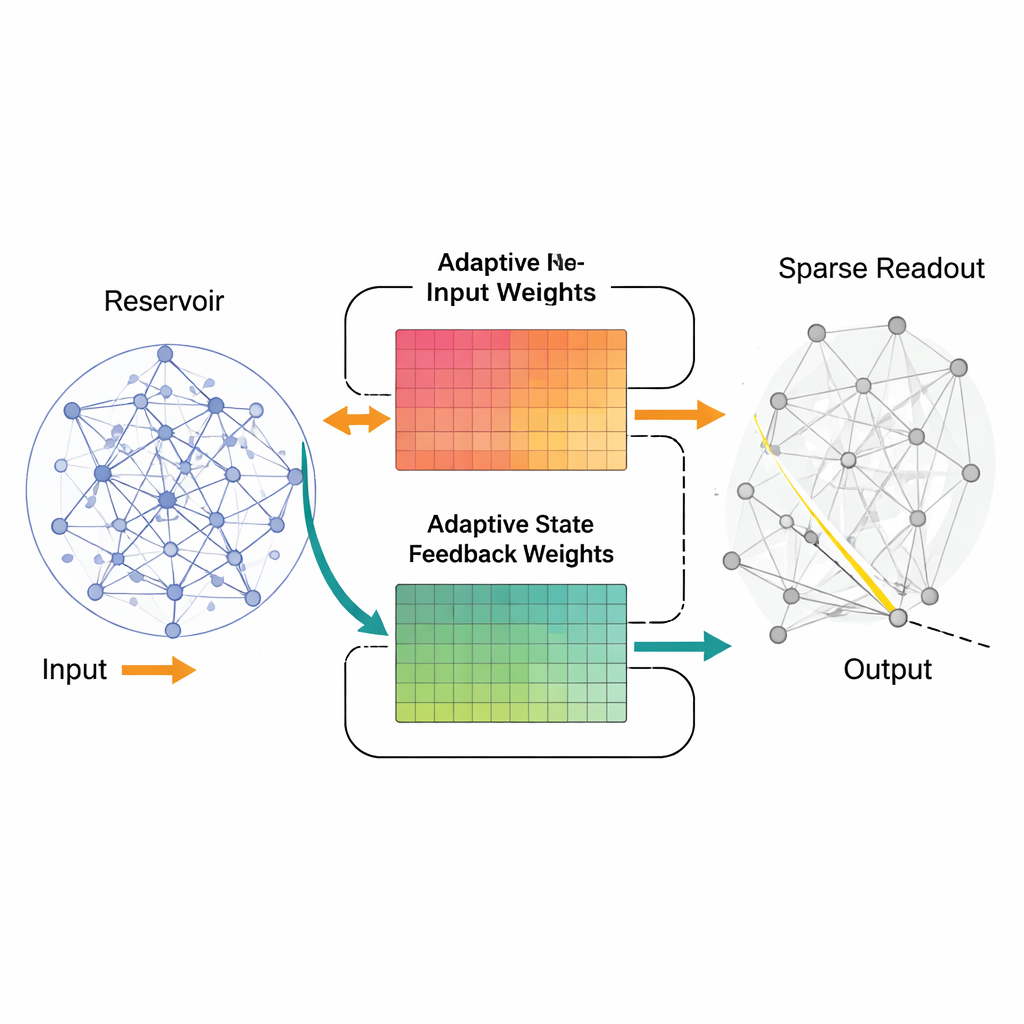
Wat dit betekent voor slimmere, slankere modellen
Op hoofdlijnen toont de studie aan dat het toestaan dat een netwerk aanpast hoe signalen zijn binnenkomen en teruggevoerd worden naar zijn interne toestand net zo belangrijk kan zijn als het fijnregelen van de uiteindelijke uitvoerlaag. AFRICO gebruikt dit idee om een vast willekeurig reservoir te veranderen in een flexibel dynamisch model dat complexe systemen kan nabootsen met minder neuronen en lagere fout, terwijl de training rekentechnisch bescheiden blijft. Voor de niet‑specialist is de boodschap dat we tijdsbewuste neurale netwerken kunnen bouwen die sneller, kleiner en beter interpreteerbaar zijn door slim te vormen hoe ze de echo van het verleden reproduceren — een stap naar meer praktische en hersenachtige hulpmiddelen om signalen die in de tijd evolueren te begrijpen en te voorspellen.
Bronvermelding: Lupascu, C.A., Coca, D. Adaptive state-feedback echo state networks for temporal sequence learning. Sci Rep 16, 13618 (2026). https://doi.org/10.1038/s41598-026-42971-5
Trefwoorden: echo state-netwerken, leren van temporele reeksen, reservoir computing, adaptieve feedback, tijdreeksmodellering