Clear Sky Science · en
Adaptive state-feedback echo state networks for temporal sequence learning
Teaching Machines to Better Remember the Past
Many of the things we want computers to do – from understanding speech to decoding signals from the brain – depend on spotting patterns that unfold over time. This paper introduces a new way to train a type of neural network so that it can remember and predict these unfolding patterns more accurately, without demanding huge computing power. The method, called AFRICO, reshapes how information flows inside the network so it can track complex, noisy time series in both engineered systems and living brains.
Why Reservoir Brains Are Fast but Forgetful
Echo State Networks are a streamlined kind of recurrent neural network. Instead of training every connection, they rely on a large “reservoir” of randomly wired neurons that transform incoming signals into a rich internal echo of past inputs. Only the final layer that reads out this activity is trained, which makes learning fast and cheap. However, because the internal wiring stays fixed, the reservoir cannot easily adapt to the specific patterns of a task. Earlier upgrades tried to help by feeding the network’s own output back into the reservoir, but typically kept those feedback connections fixed as well. That improves performance somewhat, yet still treats the reservoir as a mostly unchangeable black box.
Letting the Network Tune Its Own Echoes
AFRICO changes this picture by allowing the network to adjust how inputs and internal signals are routed into the reservoir, while still leaving the core recurrent wiring untouched. During training, an algorithm called the Extended Kalman Filter nudges the strengths of the input and feedback pathways so that the reservoir’s evolving activity better mirrors the dynamics of the target system. Instead of simply bending a fixed internal echo to match the desired output, AFRICO gradually sculpts that echo itself. A second training stage then builds a sparse readout that connects only a small, carefully chosen subset of reservoir signals to the output, making the final model both more efficient and easier to interpret.
Putting the Method to the Test
The authors benchmarked AFRICO on several demanding tasks. First, they used synthetic systems governed by known equations, starting with simple linear dynamics and moving to more complex nonlinear ones. In each case, AFRICO-trained networks learned to track the true system far more accurately than a widely used approach called FORCE, which trains only the readout while keeping feedback fixed. Even when the internal reservoir was deliberately constrained to have limited dynamic range, AFRICO recovered the correct behavior, while the fixed-feedback networks drifted away from the target over time. The method also proved robust to measurement noise and continued to work well even when the reservoir contained relatively few neurons.
Listening to the Signals of a Living Eye
To show that the approach extends beyond toy examples, the researchers applied AFRICO to electrical recordings from fruit fly photoreceptors responding to natural light. These cells transform visual input into voltage signals with rich temporal structure. With only a handful of reservoir units, AFRICO captured the fine-scale timing of the photoreceptor response much better than fixed-feedback networks, and did so with a readout that relied on only a small fraction of all possible connections. The method also excelled on a challenging benchmark task known as NARMA10, which requires modelling intricate, long-range dependencies in a synthetic signal that many reservoir-based methods struggle to reproduce accurately.
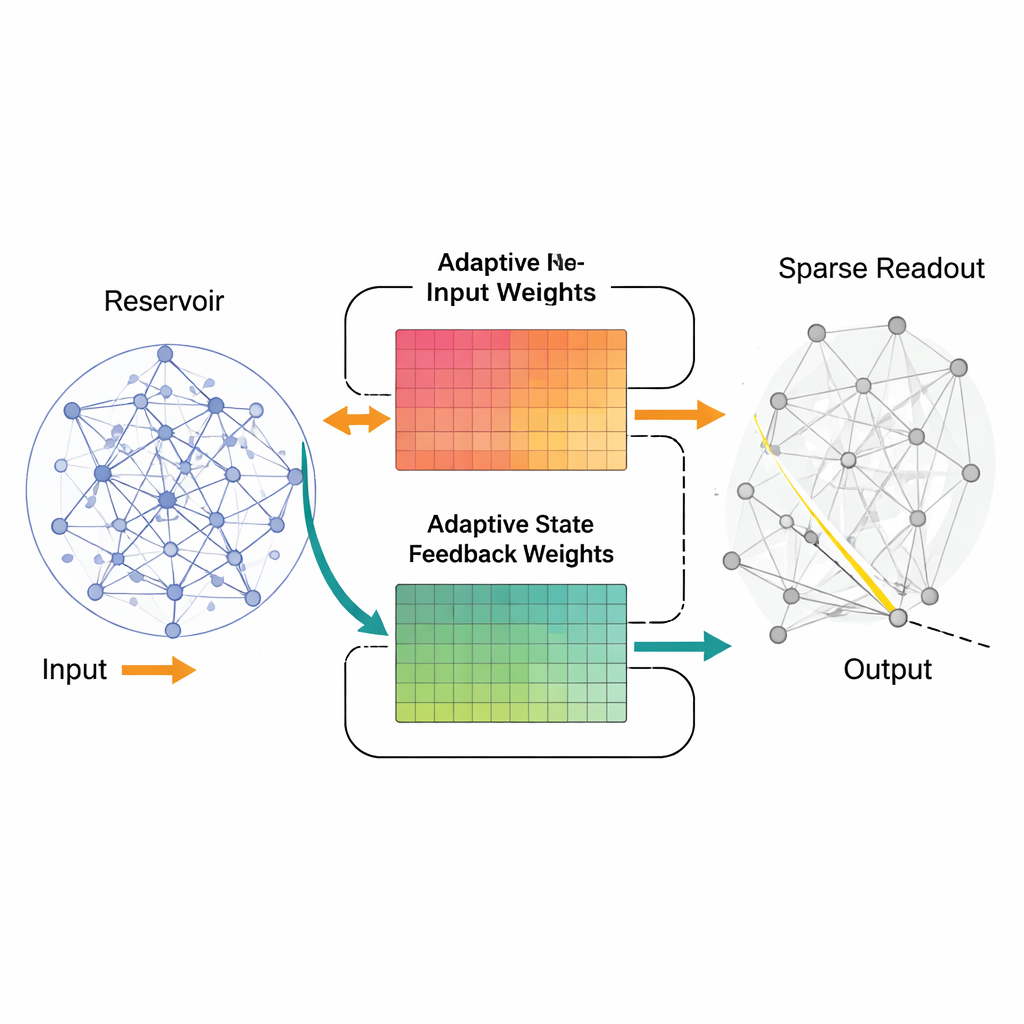
What This Means for Smarter, Leaner Models
At a high level, the study shows that letting a network adjust how signals enter and feed back into its internal state can be just as important as fine-tuning its final output layer. AFRICO uses this idea to turn a fixed random reservoir into a flexible dynamical model that can mimic complex systems with fewer neurons and lower error, while keeping training computationally modest. For a lay reader, the takeaway is that we can build time-aware neural networks that are faster, smaller, and more interpretable by smartly shaping how they echo the past – a step toward more practical and brain-like tools for understanding and predicting signals that evolve over time.
Citation: Lupascu, C.A., Coca, D. Adaptive state-feedback echo state networks for temporal sequence learning. Sci Rep 16, 13618 (2026). https://doi.org/10.1038/s41598-026-42971-5
Keywords: echo state networks, temporal sequence learning, reservoir computing, adaptive feedback, time series modelling