Clear Sky Science · de
Adaptive State-Feedback Echo-State-Netzwerke für das Lernen zeitlicher Sequenzen
Maschinen beibringen, sich besser an die Vergangenheit zu erinnern
Viele der Aufgaben, die wir Computern anvertrauen — vom Verstehen gesprochener Sprache bis zur Dekodierung von Gehirnsignalen — beruhen darauf, Muster zu erkennen, die sich über die Zeit entfalten. Dieses Papier stellt eine neue Trainingsmethode für eine bestimmte Art neuronaler Netze vor, mit der sie sich diese zeitlich verlaufenden Muster genauer merken und vorhersagen können, ohne enorme Rechenressourcen zu benötigen. Die Methode namens AFRICO formt die Informationsflüsse innerhalb des Netzes so um, dass es komplexe, verrauschte Zeitreihen sowohl in technischen Systemen als auch in biologischen Gehirnen nachverfolgen kann.
Warum Reservoir‑Gehirne schnell, aber vergesslich sind
Echo-State-Netzwerke sind eine schlanke Variante rekurrenter neuronaler Netze. Anstatt jede Verbindung zu trainieren, nutzen sie ein großes „Reservoir“ zufällig verschalteter Neuronen, das eingehende Signale in einen reichen internen Nachhall vergangener Eingaben transformiert. Nur die letzte Schicht, die diese Aktivität ausliest, wird trainiert, wodurch das Lernen schnell und kostengünstig ist. Da die interne Verschaltung jedoch unverändert bleibt, kann sich das Reservoir nicht leicht an die spezifischen Muster einer Aufgabe anpassen. Früheren Verbesserungsansätzen versuchten, die Ausgabe des Netzes zurück ins Reservoir zu speisen, hielten diese Rückkopplungen aber meist ebenfalls fest. Das verbessert die Leistung zwar etwas, behandelt das Reservoir jedoch weiterhin weitgehend als unveränderliche Blackbox.
Dem Netzwerk erlauben, seine eigenen Echos zu justieren
AFRICO verändert dieses Bild, indem es dem Netz erlaubt, die Art und Weise anzupassen, wie Eingaben und interne Signale in das Reservoir geleitet werden, während die zentrale rekurrente Verschaltung unangetastet bleibt. Während des Trainings stimmt ein Algorithmus, der Erweiterte Kalman-Filter, die Stärken der Eingangs- und Rückkopplungspfade so ab, dass die sich entwickelnde Aktivität des Reservoirs die Dynamik des Zielsystems besser widerspiegelt. Anstatt einen fixen internen Nachhall nur zu verbiegen, um die gewünschte Ausgabe zu erreichen, formt AFRICO diesen Nachhall schrittweise selbst. In einer zweiten Trainingsphase wird dann ein spärlicher Readout aufgebaut, der nur eine kleine, sorgfältig ausgewählte Teilmenge von Reservoir-Signalen mit der Ausgabe verbindet — das macht das endgültige Modell sowohl effizienter als auch leichter interpretierbar.
Die Methode auf die Probe stellen
Die Autoren testeten AFRICO an mehreren anspruchsvollen Aufgaben. Zunächst verwendeten sie synthetische Systeme, die durch bekannte Gleichungen beschrieben sind, beginnend mit einfachen linearen Dynamiken und übergehend zu komplexeren nichtlinearen. In jedem Fall lernten AFRICO-trainierte Netze, das wahre System weitaus genauer nachzuverfolgen als ein weit verbreiteter Ansatz namens FORCE, der nur den Readout trainiert und die Rückkopplung festhält. Selbst wenn das interne Reservoir absichtlich in seinem dynamischen Bereich beschränkt wurde, rekonstruierte AFRICO das korrekte Verhalten, während Netze mit fixer Rückkopplung mit der Zeit vom Ziel abdrifteten. Die Methode erwies sich auch als robust gegenüber Messrauschen und funktionierte weiterhin gut, selbst wenn das Reservoir relativ wenige Neuronen enthielt.
Den Signalen eines lebenden Auges zuhören
Um zu zeigen, dass der Ansatz über Spielzeugbeispiele hinausgeht, wendeten die Forschenden AFRICO auf elektrische Aufzeichnungen von Fotorezeptoren der Fruchtfliege an, die auf natürliches Licht reagieren. Diese Zellen wandeln visuelle Eingaben in Spannungssignale mit reicher zeitlicher Struktur um. Mit nur einer Handvoll Reservoir-Einheiten erfasste AFRICO das feine Timing der Fotorezeptorantwort deutlich besser als Netze mit fester Rückkopplung und tat dies mit einem Readout, der nur einen kleinen Bruchteil aller möglichen Verbindungen nutzte. Die Methode zeigte außerdem hervorragende Ergebnisse bei einer anspruchsvollen Benchmark-Aufgabe namens NARMA10, die das Modellieren komplexer, langreichweitiger Abhängigkeiten in einem synthetischen Signal erfordert — eine Herausforderung, bei der viele reservoirbasierte Methoden Schwierigkeiten haben.
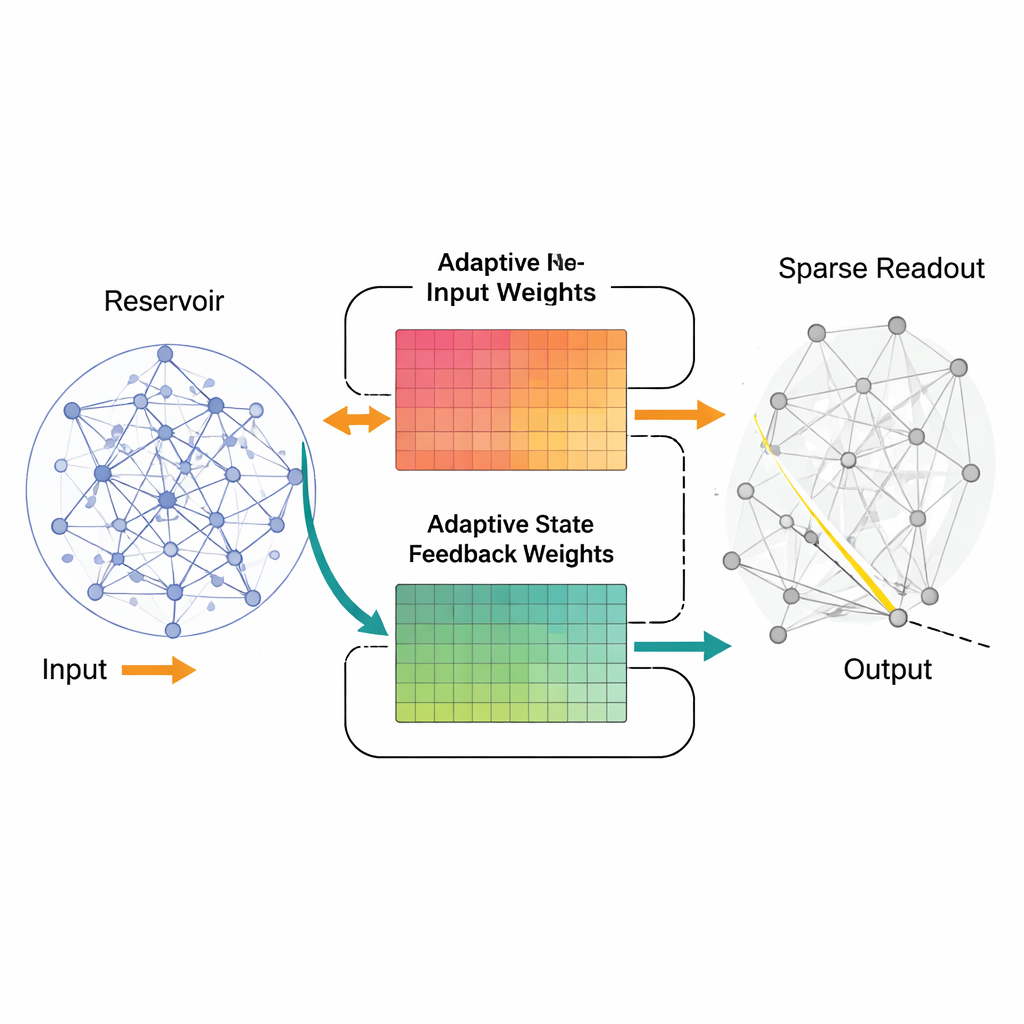
Was das für schlauere, sparsamere Modelle bedeutet
Auf einer übergeordneten Ebene zeigt die Studie, dass es genauso wichtig sein kann, einem Netzwerk zu erlauben, anzupassen, wie Signale in seinen internen Zustand eintreten und zurückfließen, wie die Feinabstimmung seiner finalen Ausgabeschicht. AFRICO nutzt diese Idee, um ein festes, zufälliges Reservoir in ein flexibles dynamisches Modell zu verwandeln, das komplexe Systeme mit weniger Neuronen und geringeren Fehlern nachahmen kann, während das Training rechnerisch moderat bleibt. Für eine sachlich interessierte Leserschaft lautet die Schlussfolgerung: Wir können zeitbewusste neuronale Netze bauen, die schneller, kleiner und besser interpretierbar sind, indem wir gezielt gestalten, wie sie die Vergangenheit nachhallen lassen — ein Schritt hin zu praktischeren und gehirnähnlicheren Werkzeugen zum Verstehen und Vorhersagen zeitlich sich entwickelnder Signale.
Zitation: Lupascu, C.A., Coca, D. Adaptive state-feedback echo state networks for temporal sequence learning. Sci Rep 16, 13618 (2026). https://doi.org/10.1038/s41598-026-42971-5
Schlüsselwörter: Echo-State-Netzwerke, Lernen zeitlicher Sequenzen, Reservoir-Computing, adaptive Rückkopplung, Zeitreihenmodellierung