Clear Sky Science · nl
Hybride diepe neurale netwerk met PCA-geoptimaliseerde kenmerken voor het verbeteren van hersentumorklassificatie
Waarom het vroeg opsporen van hersentumoren ertoe doet
Hersentumoren behoren tot de meest gevreesde vormen van kanker omdat ze zich binnen het controlecentrum van het lichaam ontwikkelen, vaak geruisloos totdat ze ernstige symptomen veroorzaken. Artsen vertrouwen op MRI-scans om deze tumoren te vinden en te volgen, maar moderne scanners leveren per patiënt duizenden gedetailleerde beelden op. Hoe bekwaam ook, een menselijke radioloog kan moeite hebben om al die informatie snel en consistent te doorzoeken. Deze studie beschrijft een computersysteem dat helpt door hersenscans te lezen en ze in vier groepen te verdelen—glioma, meningeoom, hypofysetumor of geen tumor—met een nauwkeurigheid die veel eerdere methoden evenaart of overtreft.
Complexe scans omzetten in helderdere beelden
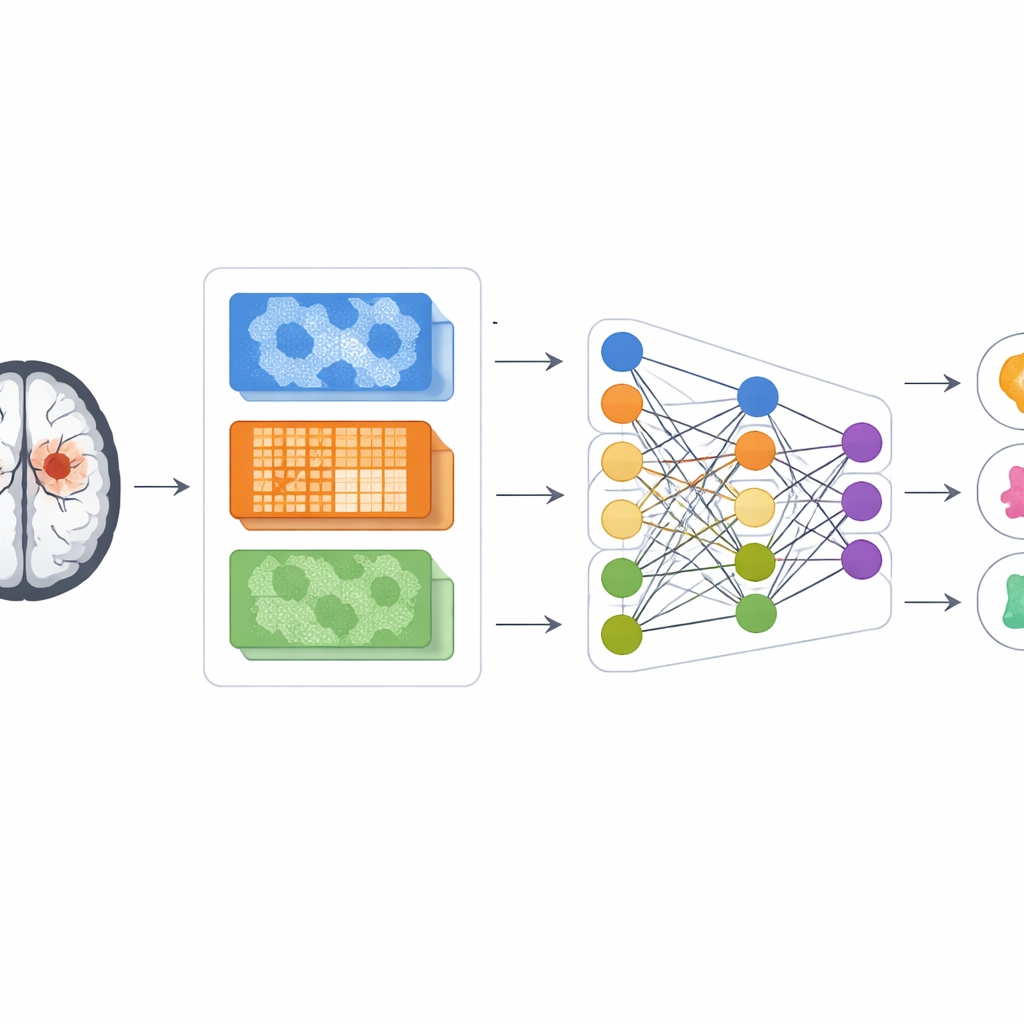
De kern van het werk is een poging om de vloed van visuele gegevens van MRI-machines te temmen. De auteurs bouwen voort op een krachtig beeldherkenningsnetwerk genaamd DenseNet121, oorspronkelijk getraind op alledaagse foto’s, en hertrainen het om patronen in hersenscans te herkennen. Voordat de beelden dit netwerk bereiken, worden ze zorgvuldig voorbereid: hun grootte wordt gestandaardiseerd, het contrast wordt gladgestreken en versterkt, en de regio’s die het meest waarschijnlijk tumoren bevatten worden geïsoleerd met behulp van een clusteringmethode die vergelijkbare pixels groepeert. Deze stappen helpen de computer zich te concentreren op het hersenweefsel dat het meest relevant is en verminderen afleiding door ruis of achtergrondstructuren.
Een mengeling van verschillende manieren om naar een tumor te kijken
In plaats van alleen te vertrouwen op wat het diepe netwerk zelf leert, berekent het systeem ook klassieke beeldbeschrijvingen die radiologen en ingenieurs al jaren gebruiken. De ene set legt vast hoe lichte en donkere plekken naast elkaar zijn gerangschikt, waarbij textuur en randen worden benadrukt. Een andere richt zich op zeer kleine lokale patronen in pixelintensiteit, die subtiele korreligheid in weefsel kunnen onthullen. Een derde volgt hoe vergelijkbare intensiteiten zich over grotere gebieden clusteren, en benadrukt of een regio glad en uniform is of gegolfd en onregelmatig. Door deze drie gezichtspunten te combineren tot één kenmerkenset krijgt het model een rijkere beschrijving van elke verdachte tumor dan met alleen diepe leren.
De gegevens beheersbaar en betrouwbaar maken
De gecombineerde beschrijving van elke scan is extreem hoog-dimensionaal, wat een leeralgoritme kan verwarren en kan leiden tot overfitting—waarbij het model trainingsbeelden memoriseert in plaats van algemene regels te leren. Om dit te voorkomen gebruiken de auteurs een wiskundig hulpmiddel genaamd principal component analysis om de informatie te comprimeren tot een kleiner aantal informatieve componenten voordat deze in het classificatienetwerk wordt gevoerd. Belangrijk is dat al deze stappen zijn ontworpen om echt klinisch gebruik na te bootsen: scans van elke patiënt worden ofwel in de trainingsgroep of in de testgroep gehouden, nooit in beide, zodat het model niet kan sjoemelen door dezelfde anatomie twee keer te zien. Het netwerk zelf bevat dropout-lagen en het schudden van data, technieken die tijdens training opzettelijk toeval toevoegen zodat het uiteindelijke systeem robuuster is voor nieuwe gevallen.
Hoe goed het systeem verschillende tumoren herkent
De onderzoekers testen hun methode op meer dan zevenduizend MRI-beelden uit een veelgebruikte openbare collectie. De scans beslaan vier categorieën: glioma, meningeoom, hypofysetumor en normaal brein. Met hun hybride ontwerp bereiken ze ongeveer 95,9% algemene nauwkeurigheid. Precisie, recall en de gecombineerde F1-score—alle drie standaardmaten voor hoeveel gevallen correct worden gelabeld en hoeveel fouten er worden gemaakt—blijven elk rond de 94%. Het model is vooral sterk in het identificeren van hypofysetumoren en normale breinen, en verwisselt slechts zelden gliomen met meningeomen, die aan de randen vergelijkbaar kunnen lijken. Leercurves tonen dat de prestaties op trainings- en ongeziene validatiebeelden samen toenemen zonder grote verschillen, wat suggereert dat het netwerk de veelvoorkomende valkuil van overfitting heeft vermeden.
Wat dit kan betekenen voor patiënten en artsen
Voor niet‑specialisten is de belangrijkste boodschap dat het combineren van meerdere manieren om een afbeelding te beschrijven met een modern diep leernetwerk ruwe MRI-scans kan omzetten in betrouwbare, geautomatiseerde suggesties over het type tumor. Het systeem is niet bedoeld om radiologen te vervangen, maar om te dienen als een tweede paar ogen dat snel en consistent werkt over grote aantallen scans. Met verdere tests op gegevens van verschillende ziekenhuizen en scanners, en toekomstige verbeteringen in hoe tumoren worden afgebakend en kenmerken worden geselecteerd, zouden dergelijke hulpmiddelen kunnen helpen gevaarlijke gezwellen eerder te detecteren, verkeerde classificaties te verminderen en snellere behandelbeslissingen te ondersteunen.
Bronvermelding: Pandey, B.K., Pandey, D., Lee, TF. et al. Hybrid deep neural network with PCA based features optimization for enhancing brain tumor classification. Sci Rep 16, 9968 (2026). https://doi.org/10.1038/s41598-026-39154-7
Trefwoorden: hersen tumor MRI, diepe leerdiagnose, analyse van medische beelden, tumorklassificatie, computerondersteunde detectie