Clear Sky Science · fr
Réseau neuronal profond hybride avec optimisation des caractéristiques basée sur l'ACP pour améliorer la classification des tumeurs cérébrales
Pourquoi il est important de détecter les tumeurs cérébrales tôt
Les tumeurs cérébrales figurent parmi les cancers les plus redoutés parce qu’elles se développent au sein du centre de commande du corps, souvent de façon silencieuse, jusqu’à provoquer des symptômes graves. Les médecins s’appuient sur les examens IRM pour repérer et suivre ces tumeurs, mais les appareils modernes produisent des milliers d’images détaillées pour chaque patient. Quel que soit leur talent, les radiologues humains peuvent peiner à trier rapidement et de façon cohérente autant d’informations. Cette étude décrit un système informatique qui aide en lisant les scanners cérébraux et en les classant en quatre groupes — gliome, méningiome, tumeur hypophysaire ou absence de tumeur — avec une précision qui rivalise ou dépasse de nombreuses méthodes antérieures.
Transformer des scans complexes en images plus claires
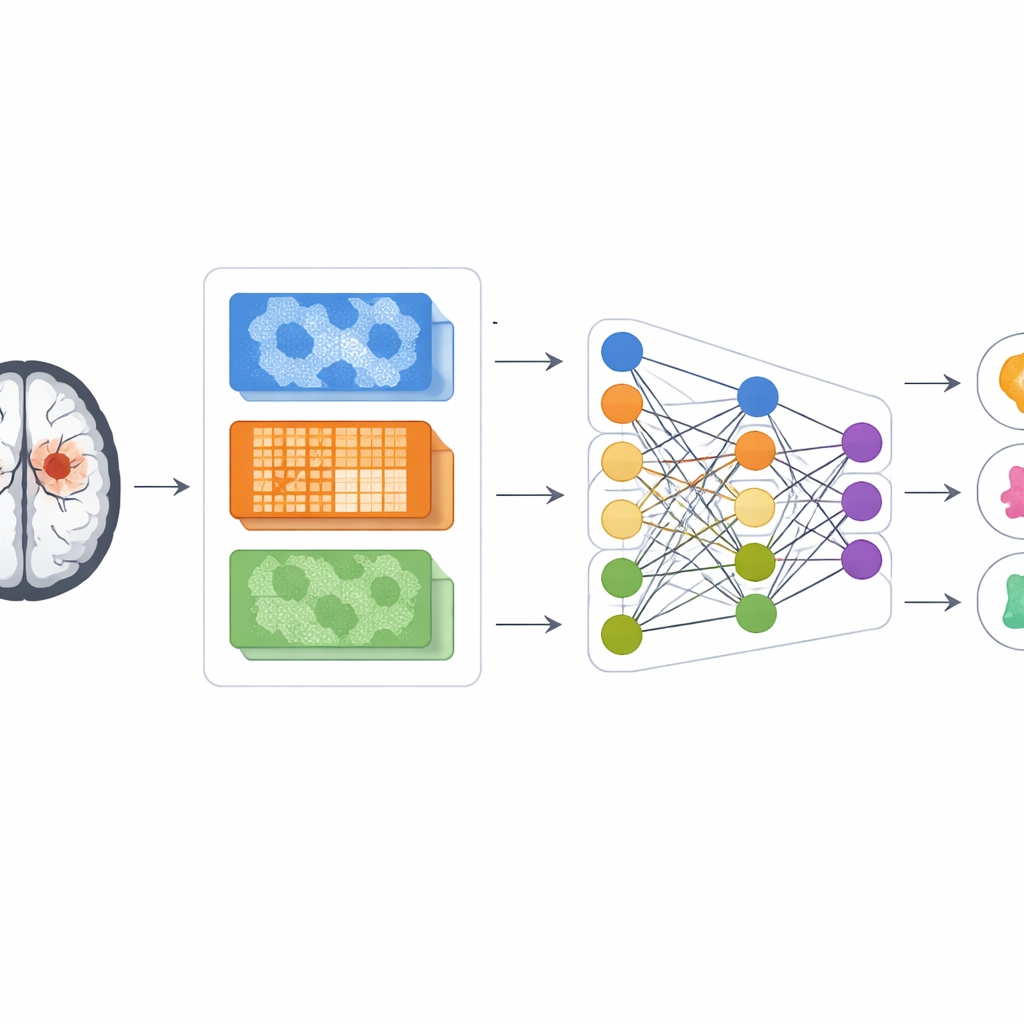
Au cœur du travail se trouve l’effort de maîtriser le flot de données visuelles provenant des machines IRM. Les auteurs s’appuient sur un puissant réseau de reconnaissance d’images appelé DenseNet121, initialement entraîné sur des photographies courantes, et le réentraînent pour reconnaître des motifs dans les images cérébrales. Avant que les images n’atteignent ce réseau, elles sont soigneusement préparées : leur taille est standardisée, le contraste est lissé et amplifié, et les régions les plus susceptibles de contenir des tumeurs sont isolées au moyen d’une méthode de regroupement qui rassemble des pixels similaires. Ces étapes aident l’ordinateur à se concentrer sur le tissu cérébral le plus pertinent et à réduire les distractions liées au bruit ou aux structures de fond.
Mélanger plusieurs façons d’examiner une tumeur
Plutôt que de ne compter que sur ce que le réseau profond apprend seul, le système calcule également des descripteurs d’image classiques utilisés depuis des années par les radiologues et les ingénieurs. Un ensemble capture la disposition des zones claires et sombres adjacentes, mettant en évidence la texture et les contours. Un autre se concentre sur des motifs locaux très fins de l’intensité des pixels, ce qui peut révéler une granulosité subtile du tissu. Un troisième suit la façon dont des intensités similaires se regroupent sur des zones plus larges, soulignant si une région est lisse et homogène ou plutôt hétérogène et irrégulière. En fusionnant ces trois points de vue en un seul jeu de caractéristiques, le modèle obtient une description plus riche de chaque tumeur suspecte que celle fournie par l’apprentissage profond seul.
Rendre les données gérables et fiables
La description combinée de chaque scan est extrêmement haute en dimension, ce qui peut embrouiller un algorithme d’apprentissage et conduire au surapprentissage — lorsque le modèle mémorise les images d’entraînement au lieu d’apprendre des règles générales. Pour éviter cela, les auteurs utilisent un outil mathématique appelé analyse en composantes principales (ACP) pour compresser l’information en un nombre réduit de composantes informatives avant de l’envoyer au réseau de classification. Il est important de noter que toutes ces étapes sont conçues pour imiter un usage clinique réel : les scans de chaque patient sont conservés soit dans le groupe d’entraînement soit dans le groupe de test, jamais dans les deux, afin que le modèle ne puisse pas tricher en voyant deux fois la même anatomie. Le réseau lui‑même inclut des couches de dropout et des permutations des données, des techniques qui ajoutent délibérément de l’aléa pendant l’entraînement afin que le système final soit plus robuste face à de nouveaux cas.
Quelle est la performance du système pour reconnaître les différentes tumeurs
Les chercheurs testent leur méthode sur plus de sept mille images IRM issues d’une collection publique largement utilisée. Les scans couvrent quatre catégories : gliome, méningiome, tumeur hypophysaire et cerveau normal. Grâce à leur conception hybride, ils atteignent environ 95,9 % de précision globale. La précision, le rappel et le score F1 combiné — toutes des mesures standard du nombre de cas correctement étiquetés et des erreurs commises — se situent chacune autour de 94 %. Le modèle est particulièrement performant pour identifier les tumeurs hypophysaires et les cerveaux normaux, et ne confond que rarement les gliomes avec les méningiomes, qui peuvent paraître similaires à leurs frontières. Les courbes d’apprentissage montrent que la performance sur les images d’entraînement et sur les images de validation non vues augmente de concert sans larges écarts, ce qui suggère que le réseau a évité le piège fréquent du surapprentissage.
Ce que cela pourrait signifier pour les patients et les médecins
Pour un non‑spécialiste, le message principal est que la combinaison de plusieurs façons de décrire une image avec un réseau moderne d’apprentissage profond peut transformer des scans IRM bruts en suggestions automatisées et fiables sur le type de tumeur. Le système n’a pas vocation à remplacer les radiologues, mais à servir de seconde paire d’yeux qui travaille rapidement et de manière cohérente sur un grand nombre de scans. Avec des tests complémentaires sur des données provenant d’hôpitaux et d’appareils différents, et des améliorations futures de la délimitation des tumeurs et de la sélection des caractéristiques, des outils comme celui‑ci pourraient aider à détecter plus tôt des croissances dangereuses, réduire les erreurs de classification et favoriser des décisions thérapeutiques prises en temps utile.
Citation: Pandey, B.K., Pandey, D., Lee, TF. et al. Hybrid deep neural network with PCA based features optimization for enhancing brain tumor classification. Sci Rep 16, 9968 (2026). https://doi.org/10.1038/s41598-026-39154-7
Mots-clés: IRM tumeur cérébrale, diagnostic par apprentissage profond, analyse d'images médicales, classification des tumeurs, détection assistée par ordinateur