Clear Sky Science · nl
Een onderwaterbeeldendatabank voor occlusiebewuste instance-segmentatie van vissen
Waarom vissen tellen onder water zo moeilijk is
Viskwekerijen veranderen in hightechbedrijven, waar camera’s en algoritmen stilletjes duizenden dieren in de gaten houden. Toch blijkt een ogenschijnlijk eenvoudige taak — één vis onderscheiden van een andere in een druk aquarium — verrassend lastig. Vissen zwemmen over en onder elkaar, blokkeren het zicht van de camera en verschijnen soms slechts gedeeltelijk aan de rand van een afbeelding. Dit artikel introduceert een nieuwe verzameling onderwaterbeelden, de Fish Occlusion Dataset (FOD), ontwikkeld om computers te helpen individuele vissen te herkennen, zelfs wanneer ze deels verborgen zijn. Die vaardigheid is cruciaal voor het automatiseren van voeren, gezondheidscontroles en voorraadinschatting in moderne aquacultuur.
Een nieuwe beeldbibliotheek voor drukke vistentanks
Het hart van dit werk is een grote, zorgvuldig samengestelde set onderwaterfoto’s van karpers (crucian carp), een veelgehouden kweekvis. De onderzoekers filmden 66 vissen in een bak met een gespecialiseerde onderwatercamera boven het water en haalden stilstaande frames uit de video’s. Na het verwijderen van bijna-duplicaten bleven ze zitten met meer dan duizend afbeeldingen van één vis en honderden scènes met meerdere vissen. Elke zichtbare vis werd met de hand omrasterd op pixelniveau, zodat computers toegang krijgen tot precieze vormen in plaats van grove vakken. In totaal bevat FOD 14.376 afbeeldingen en 144.894 zorgvuldig gelabelde vissen, waarmee het een van de gedetailleerdste openbare bronnen in zijn soort is. 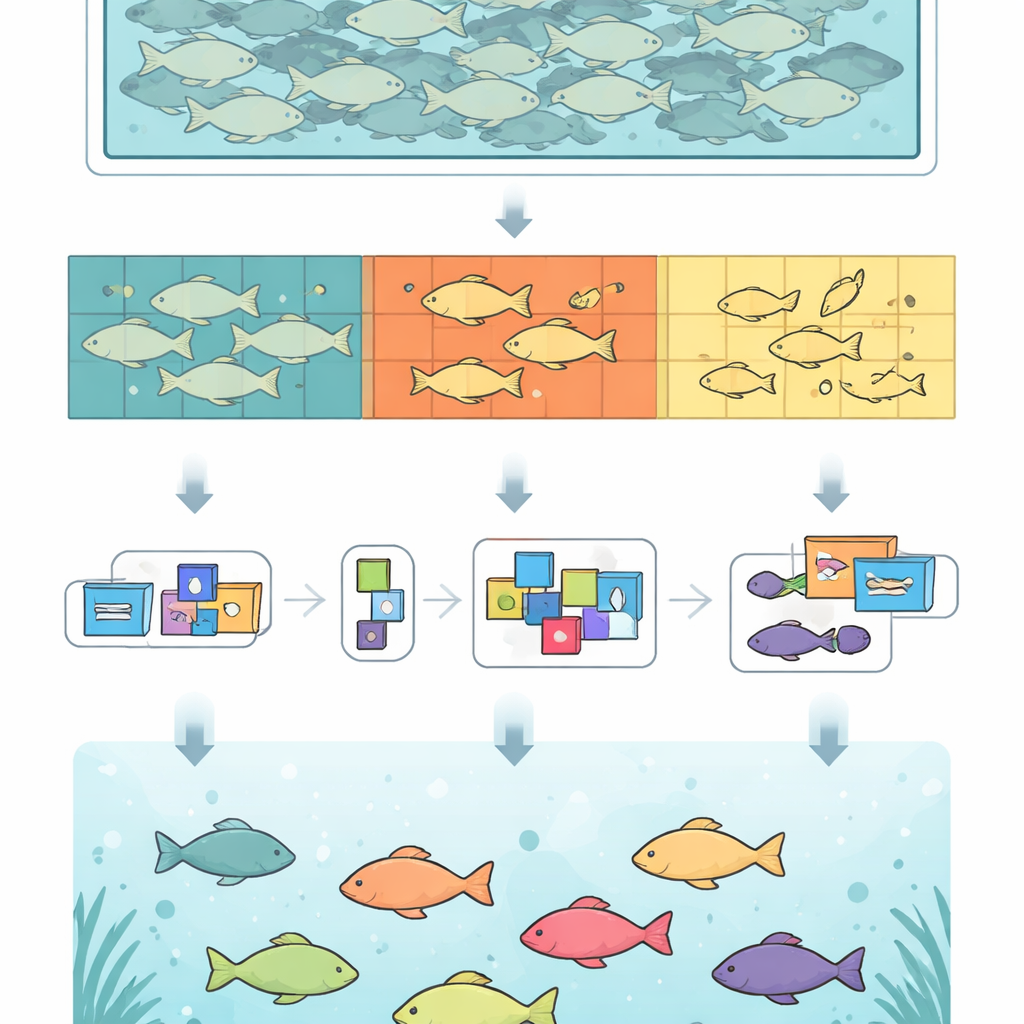
Computers leren door overlapping heen te zien
Om echt te testen hoe goed algoritmen met drukte omgaan, had het team veel voorbeelden nodig waarin vissen elkaar overlappen. Het nauwkeurig omlijnen in zulke scènes kost extreem veel tijd, dus namen ze een slimme omweg. Eerst genereerden ze hoogwaardige maskers voor individuele vissen. Vervolgens sneden ze die vissen digitaal uit en plakten ze ze in nieuwe samenstellingen op achtergrondafbeeldingen. Door vissen te roteren, te schalen en te verschuiven, en door te begrenzen hoeveel ze elkaar mogen bedekken, creëerden ze 13.000 synthetische afbeeldingen met realistische, dichte scholen en gecontroleerde overlap. Zachte blending langs de randen zorgt dat deze composities er natuurlijk uitzien. De uiteindelijke dataset mengt originele en synthetische scènes, wat zowel variatie als realisme biedt.
Beoordelen hoe verborgen elke vis is
Niet elke occlusie is hetzelfde: een volledig zichtbare vis is veel makkelijker te herkennen dan een die slechts als enkele verspreide stukjes zichtbaar is. Om dit vast te leggen, verdeelden de auteurs elke vis in drie eenvoudige groepen. “Whole” vissen zijn volledig zichtbaar, “part” vissen zijn gedeeltelijk geblokkeerd door anderen, en “fragment” vissen verschijnen alleen in afzonderlijke stukken. Deze extra laag van labeling laat onderzoekers precies zien waar hun algoritmen moeite hebben. Bij analyse van de aantallen bleek dat de meeste vissen in de dataset in de “part”-groep vallen, wat weerspiegelt wat er in drukke bakken daadwerkelijk gebeurt. Ze toonden ook aan dat traditionele samenvattende scores tekortkomingen bij kleine fragmenten kunnen verbergen, zodat rapporteren per occlusieniveau een duidelijker beeld geeft van de sterke en zwakke punten van modellen.
Hoe huidige algoritmen presteren
Om te laten zien wat FOD kan bijdragen, testte het team acht populaire beeldsegmentatiemethoden, waaronder zowel lang bestaande detectiegebaseerde modellen als nieuwere "proposal-free" ontwerpen die directer met beeldregio’s werken. Alle methoden behaalden hoge gemiddelde nauwkeurigheid op de dataset, en één methode, Mask2Former, viel op door het scherpst geproduceerde omtrekken, vooral wanneer vissen overlappen. Toch faalden zelfs de beste modellen vaker wanneer vissen in fragmenten waren gebroken — de prestaties daalden daar merkbaar vergeleken met volledig zichtbare vissen. Een extra experiment liet zien waarom de mix van echte en synthetische data in FOD belangrijk is: trainen alleen op echte scènes leidde tot slechte omgang met occlusie, terwijl trainen alleen op synthetische beelden sommige details van echte afbeeldingen miste. De combinatie van beide leverde de meest robuuste modellen op. 
Wat dit betekent voor slimmere viskwekerijen
In praktische termen biedt deze nieuwe dataset een testterrein voor computer-visionsystemen die in echte viskwekerijen moeten functioneren, waar heldere aanzichten eerder uitzondering dan regel zijn. Door doelbewust te focussen op overlappende vissen en door zowel de beelden als de code die gebruikt is om ze te maken te delen, verschaffen de auteurs een basis voor betrouwbaardere, occlusiebewuste monitoringsinstrumenten. Hoewel de huidige collectie slechts één soort in een gecontroleerde bak bestrijkt, kan dezelfde aanpak worden uitgebreid naar andere vissen en uitdagendere omgevingen. Naarmate deze technieken zich verspreiden, zouden vissers continue, precieze informatie kunnen krijgen over voorraadgrootte, gedrag en groei — wat hen helpt voer efficiënter te gebruiken, gezondheidsproblemen vroeg te signaleren en duurzamer te opereren.
Bronvermelding: Wang, X., Yu, H., Zhang, C. et al. An underwater image dataset for occlusion-aware fish instance segmentation. Sci Data 13, 526 (2026). https://doi.org/10.1038/s41597-026-06898-w
Trefwoorden: onderwaterbeeldvorming, viskwekerij, computer vision, instance-segmentatie, occlusie