Clear Sky Science · it
Un set di immagini subacquee per la segmentazione istantanea dei pesci consapevole dell’occlusione
Perché contare i pesci sott’acqua è difficile
Le aziende ittiche si stanno trasformando in operazioni ad alta tecnologia, dove telecamere e algoritmi osservano silenziosamente migliaia di animali. Eppure un compito sorprendentemente semplice — distinguere un pesce dall’altro in un acquario affollato — si rivela molto complesso. I pesci nuotano sopra e sotto gli altri, ostruiscono la vista della telecamera e compaiono solo a pezzi ai bordi dell’immagine. Questo articolo presenta una nuova raccolta di immagini subacquee, il Fish Occlusion Dataset (FOD), pensata per aiutare i computer a riconoscere singoli pesci anche quando sono parzialmente nascosti. Questa capacità è fondamentale per automatizzare la somministrazione del cibo, i controlli di salute e la stima delle scorte nell’acquacoltura moderna.
Una nuova libreria di immagini per vasche affollate
Al centro di questo lavoro c’è un ampio set di fotografie subacquee, attentamente curate, di carassi, un pesce allevato comunemente. I ricercatori hanno filmato 66 pesci in una vasca con una videocamera subacquea specializzata montata sopra l’acqua, quindi hanno estratto fotogrammi dai video. Dopo aver rimosso immagini quasi duplicate, hanno ottenuto oltre mille immagini con un singolo pesce e centinaia di scene con più pesci. Ogni pesce visibile è stato delineato a mano a livello di singolo pixel, offrendo ai computer forme precise invece di semplici riquadri approssimativi. In totale, FOD contiene 14.376 immagini e 144.894 pesci meticolosamente etichettati, rendendolo una delle risorse pubbliche più dettagliate del suo genere. 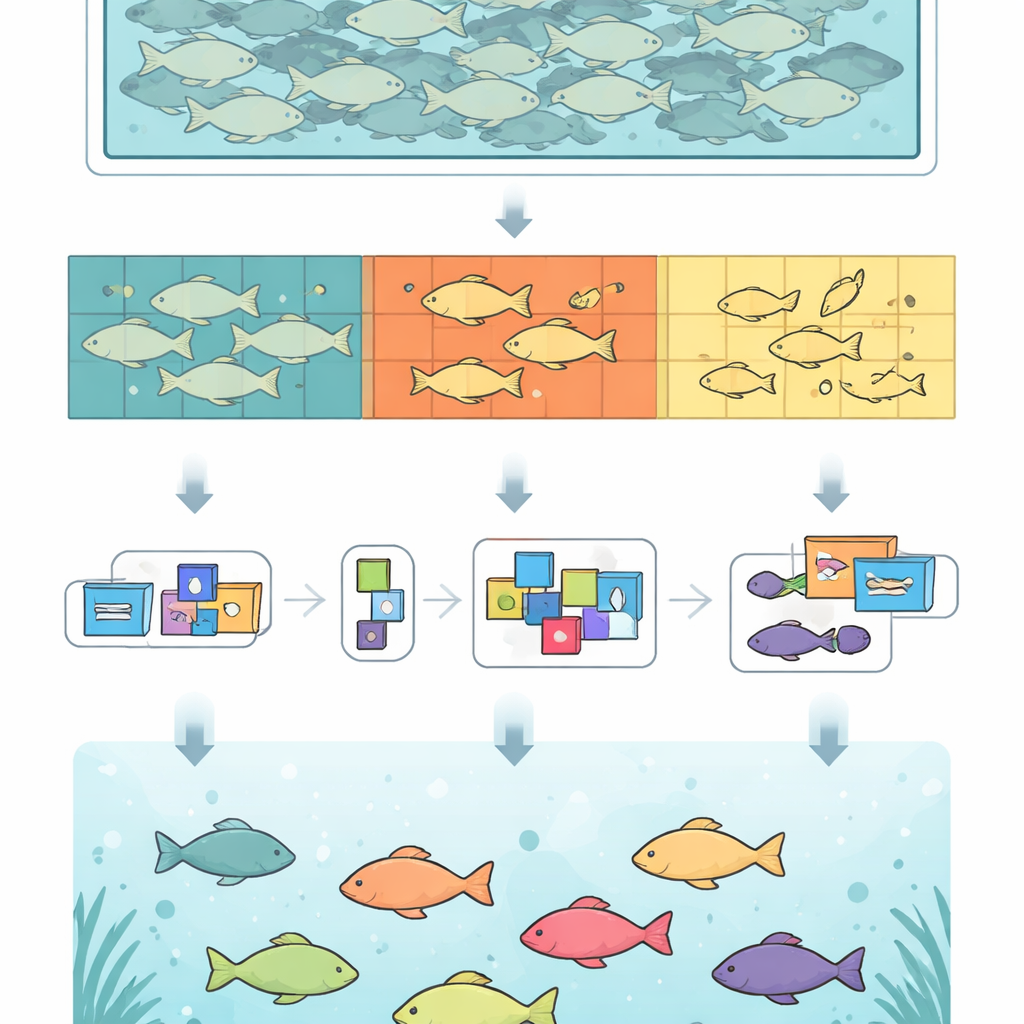
Insegnare ai computer a vedere attraverso le sovrapposizioni
Per mettere davvero alla prova la capacità degli algoritmi di gestire l’affollamento, il team aveva bisogno di molti esempi in cui i pesci si sovrappongono. Tracciare contorni dettagliati in queste scene richiede moltissimo tempo, così hanno adottato un escamotage intelligente. Prima hanno generato maschere di alta qualità per singoli pesci. Poi hanno ritagliato digitalmente quei pesci e li hanno incollati su immagini di sfondo in nuove composizioni. Ruotando, ridimensionando e spostando i pesci, e limitando quanto possono coprirsi a vicenda, hanno creato 13.000 immagini sintetiche con banchi densi e realistici e sovrapposizioni controllate. Un’accurata fusione dei bordi mantiene questi compositi dall’aspetto naturale. Il dataset finale mescola scene originali e sintetiche, offrendo allo stesso tempo varietà e realismo.
Classificare quanto ogni pesce è nascosto
Non tutte le occlusioni sono uguali: un pesce completamente visibile è molto più facile da riconoscere rispetto a uno che appare solo come alcuni frammenti sparsi. Per catturare questa differenza, gli autori hanno suddiviso ogni pesce in tre gruppi semplici. I pesci “interi” sono completamente visibili, i pesci “parziali” sono in parte bloccati da altri, e i pesci “frammento” compaiono solo in pezzi separati. Questo ulteriore livello di etichettatura permette ai ricercatori di vedere esattamente dove gli algoritmi incontrano difficoltà. Analizzando i dati, hanno riscontrato che la maggior parte dei pesci nel dataset rientra nel gruppo “parziale”, riflettendo ciò che accade realmente nelle vasche affollate. Hanno inoltre mostrato che i comuni punteggi riassuntivi possono nascondere fallimenti sui piccoli frammenti, quindi riportare i risultati per livello di occlusione dà un quadro più chiaro dei punti di forza e di debolezza dei modelli.
Come si comportano gli algoritmi attuali
Per dimostrare cosa può offrire FOD, il team ha testato otto metodi popolari di segmentazione delle immagini, includendo sia modelli basati su rilevamento consolidati sia progetti più recenti “senza proposte” che lavorano in modo più diretto con le regioni dell’immagine. Tutti hanno raggiunto elevata accuratezza media sul dataset, e un metodo in particolare, Mask2Former, si è distinto per produrre i contorni più netti, specialmente quando i pesci si sovrapponevano. Tuttavia anche i modelli migliori hanno mostrato difficoltà quando i pesci erano frammentati: le prestazioni in questi casi calavano in modo evidente rispetto ai pesci completamente visibili. Un esperimento aggiuntivo ha evidenziato perché la miscela di dati reali e sintetici di FOD è importante: l’addestramento solo su scene reali portava a una scarsa gestione delle occlusioni, mentre addestrare solo su sintetiche perdeva alcuni dettagli delle immagini reali. Combinare entrambi ha prodotto i modelli più robusti. 
Cosa significa per allevamenti ittici più intelligenti
In termini pratici, questo nuovo dataset offre un banco di prova per sistemi di visione artificiale che devono operare in allevamenti reali, dove le viste chiare sono l’eccezione più che la regola. Concentrandosi intenzionalmente sui pesci sovrapposti e condividendo sia le immagini sia il codice usato per costruirle, gli autori forniscono una base per strumenti di monitoraggio più affidabili e consapevoli delle occlusioni. Sebbene la collezione attuale copra una sola specie in una vasca controllata, lo stesso approccio può essere esteso ad altri pesci e a ambienti più impegnativi. Man mano che queste tecniche si diffonderanno, gli allevatori potranno ottenere informazioni continue e precise sul numero di capi, sul comportamento e sulla crescita — aiutandoli a usare il mangime in modo più efficiente, a individuare precocemente problemi di salute e a gestire operazioni più sostenibili.
Citazione: Wang, X., Yu, H., Zhang, C. et al. An underwater image dataset for occlusion-aware fish instance segmentation. Sci Data 13, 526 (2026). https://doi.org/10.1038/s41597-026-06898-w
Parole chiave: imaging subacqueo, acquacoltura, visione artificiale, segmentazione per istanza, occlusione