Clear Sky Science · nl
Wereldwijde 0,25-graden gegroepeerde gegevens over sneeuwwater equivalent afgeleid met machine learning uit in-situ metingen
Waarom wereldwijde sneeuw van belang is voor het dagelijks leven
Sneeuw is meer dan een wintertafereel; het is een omvangrijk natuurlijk reservoir dat in koude maanden water opslaat en het in de lente vrijgeeft om rivieren, landbouw, steden en waterkracht te voeden. Weten hoeveel water wereldwijd in sneeuw is opgeslagen helpt samenlevingen zich voor te bereiden op overstromingen, droogte en verschuivende watervoorzieningen in een opwarmend klimaat. Toch is de sleutelgrootheid die ons dit vertelt, het sneeuwwater equivalent, verrassend moeilijk op wereldschaal te meten.
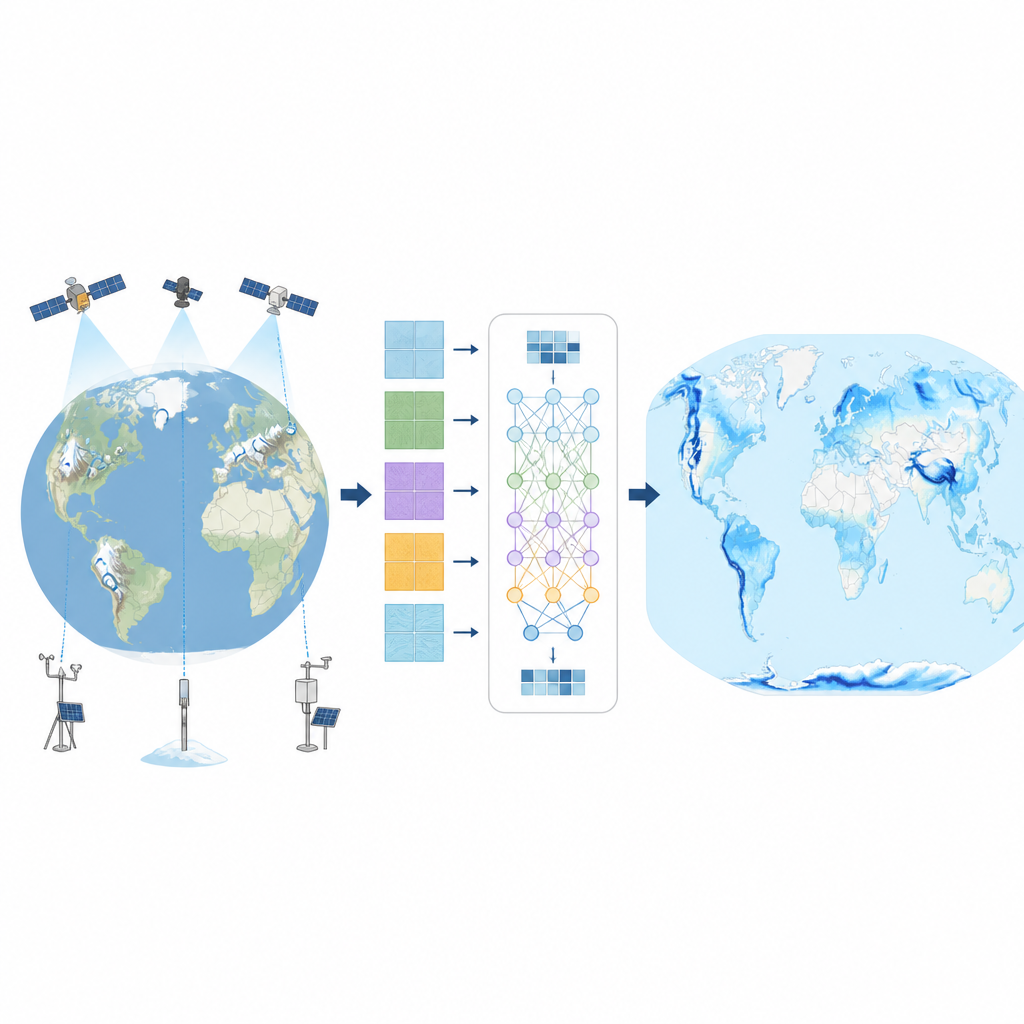
De uitdaging van het wegen van ’s werelds sneeuw
Wetenschappers kunnen sneeuw op specifieke plekken meten met sneeuwprofielen, automatische kussens die de sneeuwlaag wegen en andere grondstations. Netwerken in Noord-Amerika, Europa en Rusland hebben zulke gegevens al decennia verzameld. Satellieten, weermodellen en radarinstrumenten geven ook aanwijzingen over sneeuw. Maar elke bron heeft leemtes en zwakke punten, vooral in diepe sneeuw, bossen en steile bergen. Daardoor verschillen bestaande wereldkaarten vaak in de hoeveelheid sneeuw, en blijven veel regio’s, zoals de Andes of delen van Azië, slecht beschreven.
Een computer leren van sneeuw en weer
Om deze leemtes te dichten, bouwden de auteurs een nieuwe dagelijkse wereldwijde dataset voor sneeuwwater, genaamd SWEML, met een machine learning-methode bekend als random forests. Ze verzamelden lange reeksen grondmetingen van sneeuw uit meerdere landen, samen met satellietproducten en een moderne wereldwijde weerreanalyse die consistente gegevens over temperatuur, neerslag, straling en wind levert. Terreinkenmerken zoals hoogte, helling en vegetatietype werden toegevoegd omdat ze sterk bepalen hoe sneeuw zich ophoopt en smelt. Het team verdeelde de besneeuwde rastervakken van de wereld in 14 regio’s met vergelijkbare klimaat- en landschapskenmerken en trainde voor elke regio aparte machine learning-modellen, zodat het systeem lokaal sneeuwgedrag nauwkeuriger kon leren.
Van verspreide punten naar een wereldwijde dagelijkse sneeuwkaart
Aangezien verschillende instanties sneeuw op verschillende manieren meten, sluiten de ruwe stationgegevens niet altijd op elkaar aan. De onderzoekers pasten eerst elk stationrecord aan zodat het gemiddelde en de variabiliteit overeenkwamen met een veelgebruikt globaal weerproduct, terwijl de dag-tot-dag schommelingen uit de oorspronkelijke observaties werden behouden. Deze stap maakte de invoergegevens consistenter zonder hun lokale karakter uit te wissen. De random forest-modellen leerden vervolgens de verbanden tussen deze aangepaste sneeuwwaarden en het omringende weer en terrein. Nadat ze getraind waren, gebruikten de modellen schattingen van dagelijks sneeuwwater voor elk rastervak van 0,25 graad op aarde, met uitzondering van Antarctica, van 1980 tot 2020, wat een naadloos 41-jarig record opleverde.
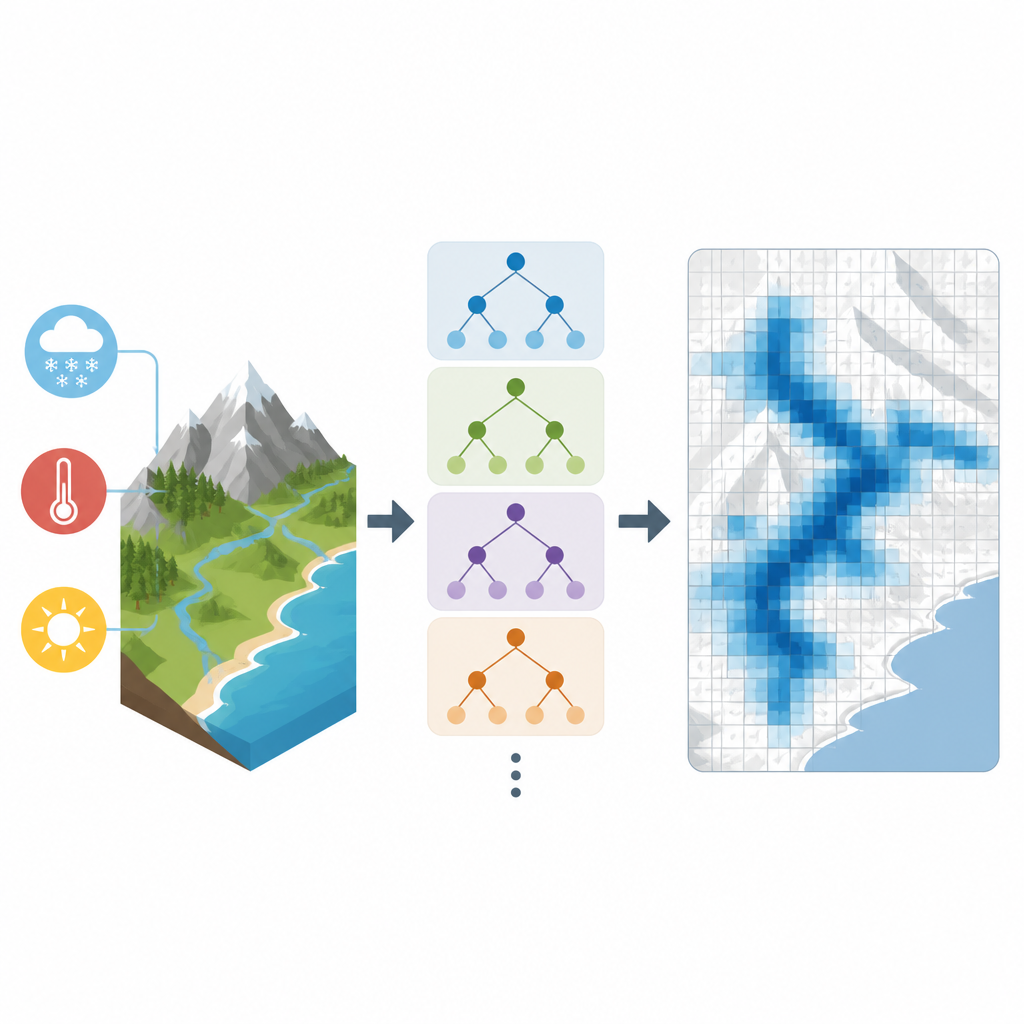
De kaarten controleren aan de hand van andere bronnen
Het team testte SWEML grondig tegen verschillende onafhankelijke referenties. Deze omvatten gamma-stralingsvluchten boven Noord-Amerika die sneeuwwater afleiden uit de manier waarop sneeuw natuurlijke straling tegenhoudt, gedetailleerde sneeuwkaarten voor de Andes opgebouwd uit satellietbeelden, en een reeks veelgebruikte wereldwijde sneeuw- en landoppervlaktedatasets. In miljoenen vergelijkingen met onaangeroerde grondmetingen vertoonde SWEML de laagste typische fout en een kleine algemene bias, met een lichte neiging tot onderschatting van sneeuw. Het presteerde bijzonder goed in hoge berggebieden zoals de Rocky Mountains en de Alpen, waar veel andere producten moeite hebben, en het reproduceerde seizoenspatronen zoals de timing en omvang van de maximale sneeuwlaag trouwer dan de concurrenten.
Wat dit betekent voor water- en klimaatplanning
Voor het eerst beschikken wetenschappers en waterbeheerders over een door machine learning ondersteund, wereldwijd continu dagelijks record van hoeveel water in sneeuw is opgeslagen over vier decennia. SWEML zal lokaal veldwerk niet vervangen en staat nog steeds voor uitdagingen in zeer ruig terrein of in regio’s met weinig of geen trainingsgegevens. Maar het biedt een krachtig nieuw fundament voor het volgen van veranderende sneeuwvoorraden, het verbeteren van risicoanalyses voor overstromingen en droogte, en het voeden van klimaat- en watermodellen die consistente langetermijningangen nodig hebben. In een wereld met verschuivende winters is dit soort brede blik op het planetaire sneeuwreservoir een belangrijke stap naar slimmer waterbeheer.
Bronvermelding: Seo, J., Panahi, M., Kim, J. et al. Global 0.25-degree gridded Snow water equivalent data derived from machine learning using in-situ measurements. Sci Data 13, 739 (2026). https://doi.org/10.1038/s41597-026-06895-z
Trefwoorden: sneeuwwater equivalent, machine learning, wereldwijde sneeuwdataset, hydrologie, klimaatverandering