Clear Sky Science · de
Globale 0,25-Grad-Rasterdaten zum Schneewasseräquivalent, abgeleitet mit maschinellem Lernen aus In-situ-Messungen
Warum globaler Schnee für den Alltag wichtig ist
Schnee ist mehr als eine Winterlandschaft; er ist ein riesiger natürlicher Speicher, der in den kalten Monaten Wasser zurückhält und im Frühjahr freigibt, um Flüsse, Landwirtschaft, Städte und Wasserkraft zu speisen. Zu wissen, wie viel Wasser weltweit im Schnee gebunden ist, hilft Gesellschaften, sich auf Überschwemmungen, Dürreperioden und veränderte Wasserangebote in einem sich erwärmenden Klima vorzubereiten. Doch die Schlüsselgröße, die uns das verrät — das Schneewasseräquivalent — war überraschend schwer global zu erfassen.
Die Herausforderung, den Schnee der Welt zu wiegen
Wissenschaftler können Schnee an bestimmten Stellen messen, etwa mit Schneemessstrecken, automatischen Kissen, die die Schneedecke wiegen, und anderen Bodenmessstationen. Netzwerke in Nordamerika, Europa und Russland haben solche Daten über Jahrzehnte gesammelt. Satelliten, Wettermodelle und Radarinstrumente liefern ebenfalls Hinweise auf Schnee. Aber jede Quelle weist Lücken und Schwächen auf, besonders bei tiefem Schnee, in Wäldern und in steilem Gebirge. Deshalb weichen bestehende globale Karten oft darin ab, wie viel Schnee vorhanden ist, und viele Regionen, wie die Anden oder Teile Asiens, sind weiterhin schlecht beschrieben.
Einem Computer beibringen, aus Schnee und Wetter zu lernen
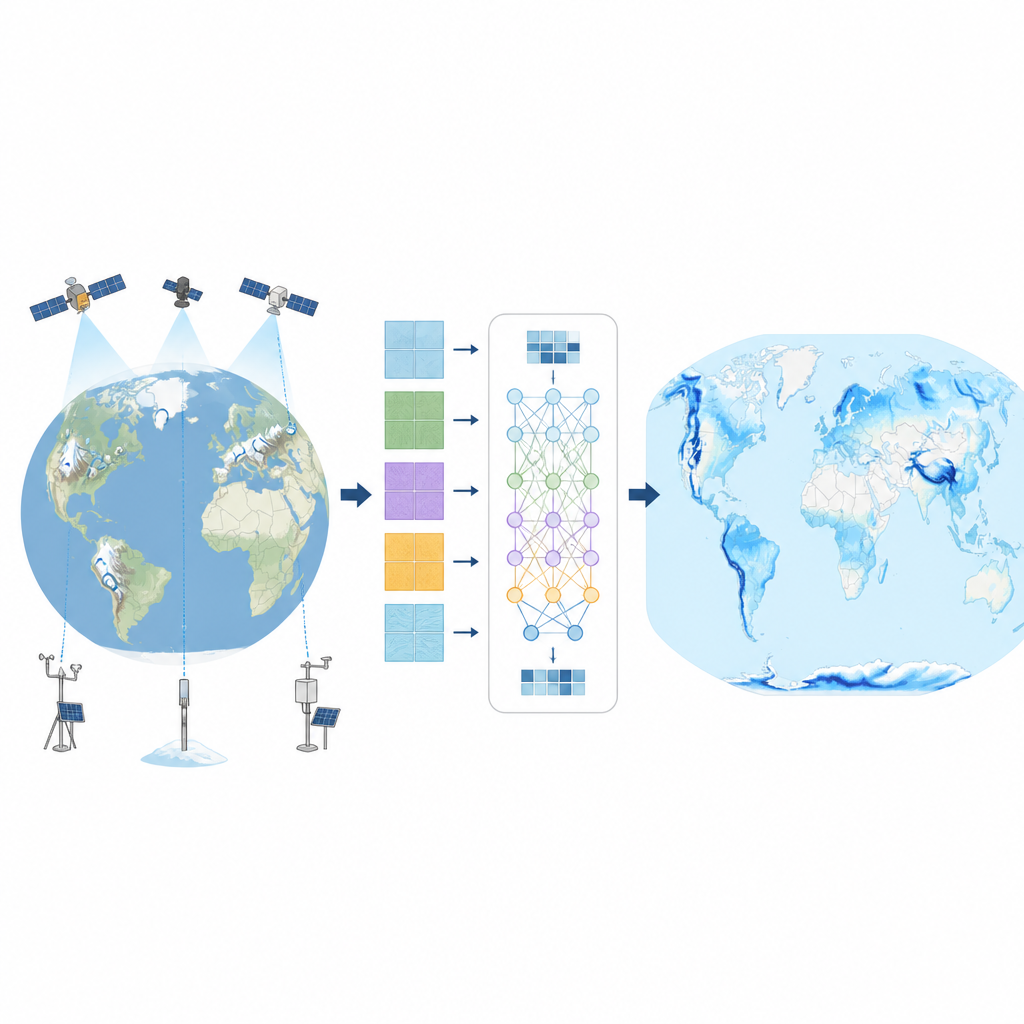
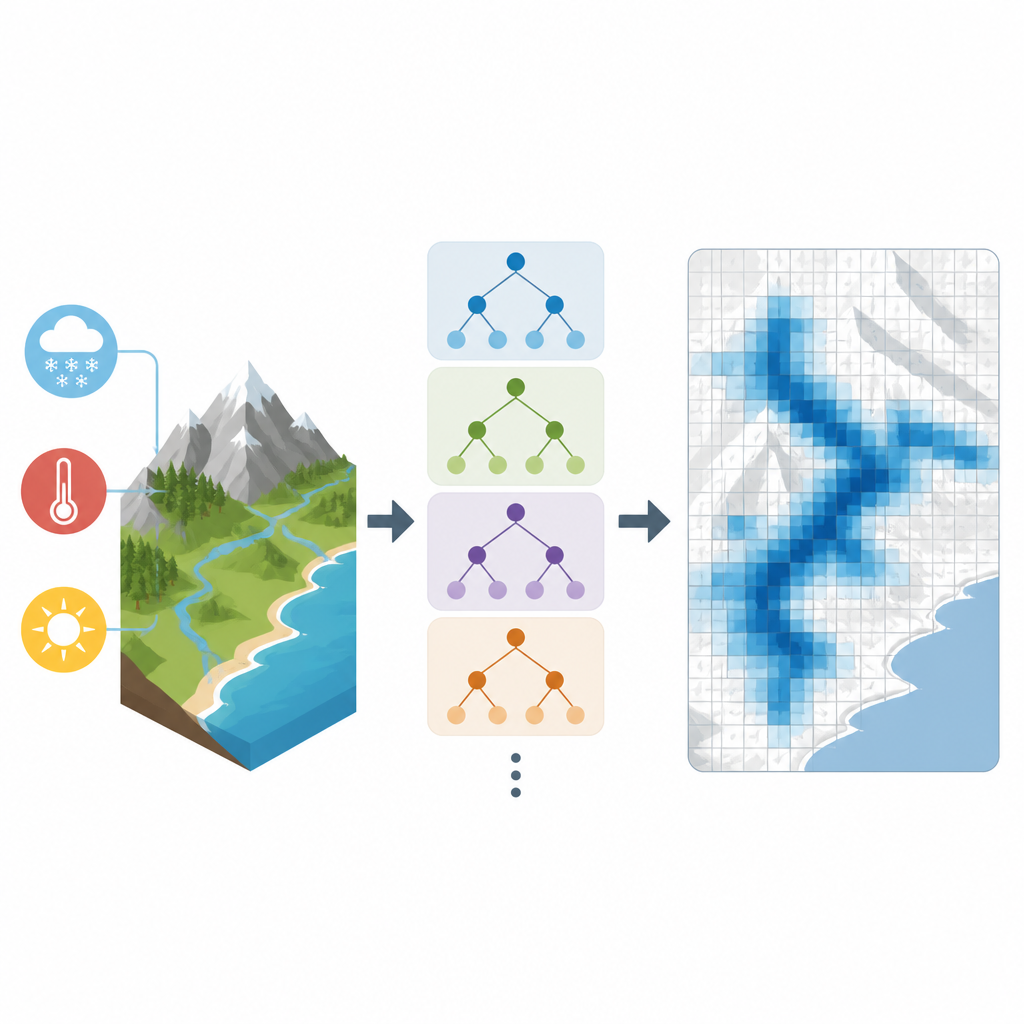
Um diese Lücken zu schließen, erstellten die Autorinnen und Autoren einen neuen täglichen globalen Datensatz zum Schneewasser namens SWEML, der ein Verfahren des maschinellen Lernens namens Random Forests nutzt. Sie sammelten lange Reihen von Boden-Schneemessungen aus mehreren Ländern sowie satellitenbasierte Produkte und eine moderne globale Wetter-Reanalyse, die konsistente Felder für Temperatur, Niederschlag, Strahlung und Wind liefert. Geländeparameter wie Höhe, Hangneigung und Vegetationstyp wurden hinzugefügt, weil sie stark beeinflussen, wie Schnee akkumuliert und schmilzt. Das Team gruppierte die schneebedeckten Rasterzellen der Welt in 14 Regionen mit ähnlichem Klima und Landschaftsmerkmalen und trainierte für jede Region separate Modelle des maschinellen Lernens, damit das System lokales Schneeverhalten genauer erfassen kann.
Von verstreuten Punkten zu einer globalen täglichen Schneekarte
Da verschiedene Stellen Schnee auf unterschiedliche Weise messen, stimmen die Rohdaten der Stationen nicht immer überein. Die Forschenden passten zunächst die Datensätze jeder Station so an, dass deren Mittelwert und Variabilität mit einem weit verbreiteten globalen Wetterprodukt übereinstimmten, während die täglichen Schwankungen der Originalbeobachtungen erhalten blieben. Dieser Schritt machte die Eingangsdaten konsistenter, ohne deren lokalen Charakter zu löschen. Die Random-Forest-Modelle lernten dann die Beziehungen zwischen diesen angepassten Schneewerten und dem umliegenden Wetter sowie Gelände. Nach dem Training wurden die Modelle verwendet, um das tägliche Schneewasser für jede 0,25-Grad-Rasterzelle der Erde — mit Ausnahme der Antarktis — von 1980 bis 2020 zu schätzen und so einen nahtlosen 41-jährigen Datensatz zu erzeugen.
Abgleich der Karten mit anderen Quellen
Das Team prüfte SWEML gründlich gegen mehrere unabhängige Referenzen. Dazu gehörten luftgestützte Gammastrahlenmessungen über Nordamerika, die auswerten, wie Schnee natürliche Strahlung abschirmt, hochauflösende Schneekarten für die Anden, die aus Satellitenbildern erstellt wurden, und eine Reihe weit verbreiteter globaler Schnee- und Landoberflächendatensätze. In Millionen von Vergleichen mit unberührten Bodenmessungen zeigte SWEML den geringsten typischen Fehler und eine geringe systematische Verzerrung, mit einer leichten Tendenz, Schnee etwas zu unterschätzen. Besonders gut schnitt es in hohen Gebirgen wie den Rocky Mountains und den Alpen ab, wo viele andere Produkte Probleme haben, und es reproduzierte saisonale Muster wie Zeitpunkt und Ausmaß des maximalen Schneedeckenbestands treuer als seine Konkurrenten.
Was das für Wasser- und Klima-Planung bedeutet
Zum ersten Mal verfügen Wissenschaftlerinnen und Wasserverwalter über einen maschinell-lernenden, global durchgehenden täglichen Datensatz darüber, wie viel Wasser über vier Jahrzehnte im Schnee gespeichert ist. SWEML wird lokale Feldarbeit nicht ersetzen, und es gibt weiterhin Herausforderungen in sehr zerklüftetem Gelände oder in Regionen mit wenig bis keinen Trainingsdaten. Dennoch bietet es eine starke neue Grundlage, um sich ändernde Schneereserven zu verfolgen, Flut- und Dürre-Risikoabschätzungen zu verbessern und Klima- sowie Wasserprognosemodelle mit konsistenten Langzeitdaten zu versorgen. In einer Welt mit verschobenen Wintern ist diese Art von großem Überblick über das globale Schnee-Reservoir ein wichtiger Schritt hin zu einer klügeren Bewirtschaftung des Wassers.
Zitation: Seo, J., Panahi, M., Kim, J. et al. Global 0.25-degree gridded Snow water equivalent data derived from machine learning using in-situ measurements. Sci Data 13, 739 (2026). https://doi.org/10.1038/s41597-026-06895-z
Schlüsselwörter: Schneewasseräquivalent, maschinelles Lernen, globaler Schneedatensatz, Hydrologie, Klimawandel