Clear Sky Science · nl
Stadsschaal hoge-resolutie verkeersdatasets met verfijnde netwerken voor hiërarchische verkeersregeling
Waarom stedelijk verkeer betere gegevens nodig heeft
Ieder die wel eens een reeks rode lichten heeft meegemaakt of langzaam over een dichtgeslibde binnenstadstraat heeft gekropen, weet hoe rommelig stadsverkeer kan zijn. Toch vertrouwen de meeste systemen die die lichten aansturen en de doorstroming beheren nog steeds op onvolledige, weinig gedetailleerde gegevens. Dit artikel introduceert een nieuwe familie van stadsschaal verkeersdatasets die onderzoekers en planners een veel helderder beeld geven van hoe voertuigen zich daadwerkelijk door echte wegnetwerken bewegen, en zo de deur openen naar slimmer, meer gecoördineerd congestiebeheer.
Van een paar straten tot hele steden
De auteurs verzamelen en standaardiseren gedetailleerde verkeersgegevens uit vijf zeer verschillende stedelijke gebieden: Jinan, Hangzhou, Manhattan, Nanchang en Xuancheng. Deze steden bestrijken alles van korte arteriële corridors met slechts een dozijn kruispunten tot uitgestrekte netwerken met duizenden knooppunten. Eerdere open datasets richtten zich meestal op kleine, nette rasters en korte snapshots van één uur. In tegenstelling daarmee legt deze verzameling een grote verscheidenheid aan wegindelingen, kruispuntvormen en vraagpatronen vast. Een van de opvallende bijdragen is de Xuancheng-dataset, die bijna een hele stad omvat met honderden kruisingen gemodelleerd in fijn detail, inclusief hoe individuele rijstroken zijn gerangschikt en hoe complexe kruispunten zijn opgebouwd.
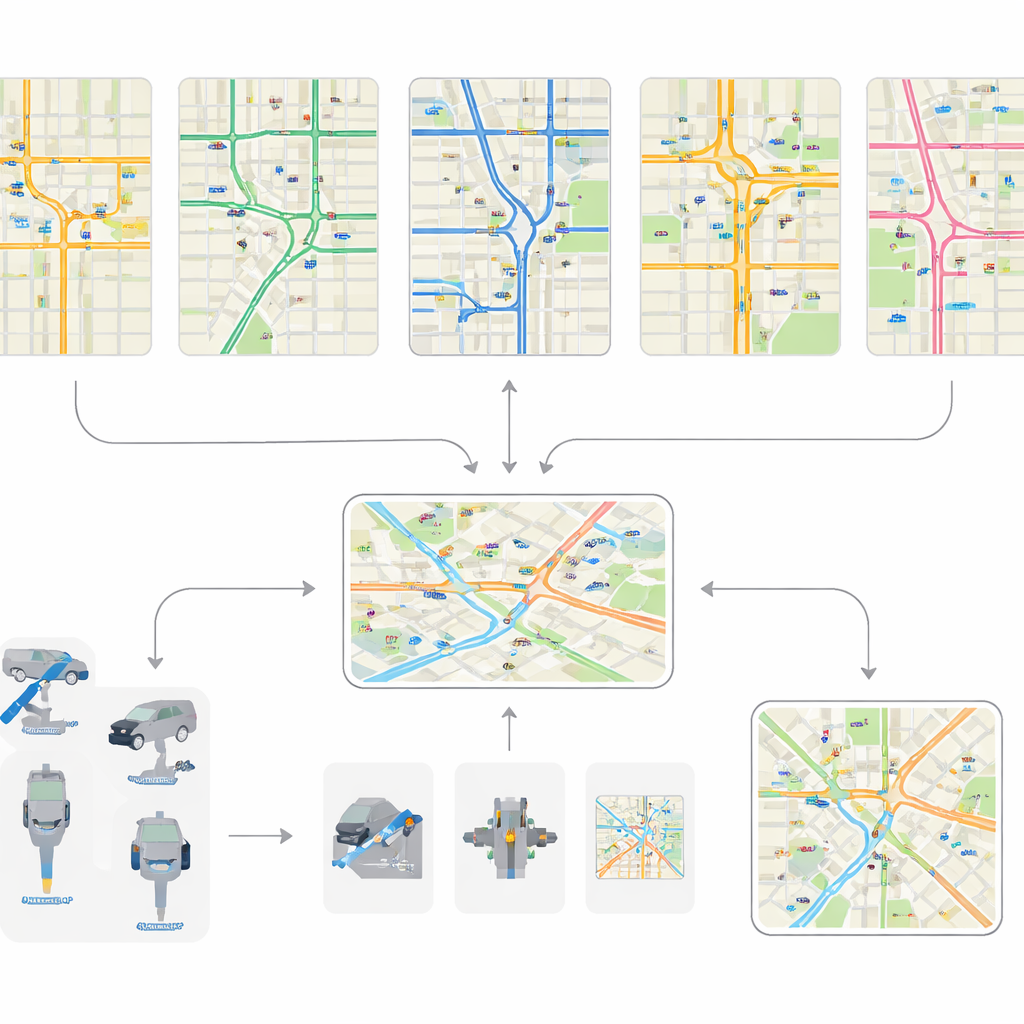
Elke auto zien, niet slechts een steekproef
De meeste bestaande verkeersgegevens komen van camera’s of dunne sensorbedekkingen, die slechts delen van het netwerk en voor korte periodes vastleggen. De Xuancheng-gegevens volgen een andere aanpak. De stad heeft een automatisch voertuigidentificatiesysteem (AVI) geïnstalleerd op belangrijke wegvakken, dat registreert wanneer elk voertuig binnenkomt en weer verlaat. Door anonieme identificaties van in- en uitrijdregistraties op elkaar af te stemmen, reconstrueren de auteurs volledige trajecten voor honderden duizenden ritten per dag over een hele maand. Hierdoor kunnen ze zien hoe bestuurders werkelijk routes kiezen, hoe stromen veranderen tussen weekdagen en weekends, en hoe feestdagen de vraag herschikken. Voertuigen worden ook ingedeeld in brede typen, zoals personen- en vrachtverkeer, zodat simulaties kunnen weerspiegelen hoe verschillende soorten voertuigen het verkeer beïnvloeden.
Rommelige registraties omzetten naar een gemeenschappelijke kaart
Omdat de ruwe gegevens van de vijf steden in verschillende formaten en detailniveaus waren opgeslagen, ontwikkelde het team een eenduidige verwerkingsworkflow. Eerst bouwen ze elk wegennet opnieuw op als een consistent digitaal kaartbeeld, waarbij kruispunten en verbindingswegen worden geïdentificeerd, zelfs wanneer de oorspronkelijke bronnen verschillende geometriedefinities gebruiken. Ze schatten de grootte en positie van kruispunten door ruwe vormen in eenvoudige rechthoeken te omsluiten en stemmen aanrijrichtingen af op kardinale oriëntaties met behulp van een optimalisatiemethode. Vervolgens standaardiseren ze verkeerslichten door een kleine set typische bewegingspatronen te definiëren — zoals linksafslaan of rechtdoorbewegingen langs een corridor — en elke echte kruising automatisch op deze patronen te matchen. Ten slotte construeren ze voertuigstromen en schonen de gegevens op: onwaarschijnlijke routes worden verwijderd, ontbrekende segmenten worden afgeleid uit het netwerk en continue ritten worden samengesteld uit vele korte sensorwaarnemingen.
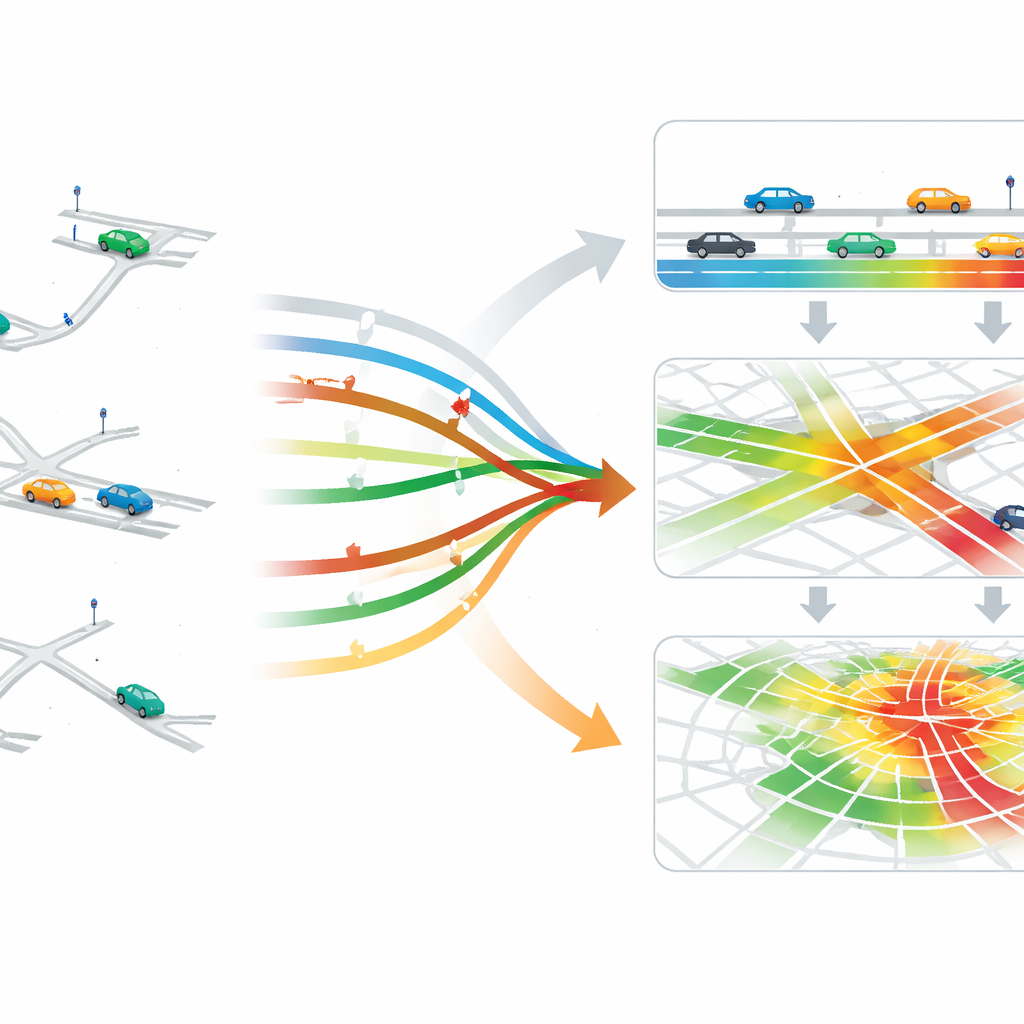
Van individuele auto’s tot hele netwerken
Zodra ritten en netwerken op hun plek staan, genereren de auteurs verkeers"status"gegevens op drie niveaus. Op het meest gedetailleerde niveau volgen ze individuele voertuigen, inclusief hun posities en snelheden, wat gebruikt kan worden om ideeën te testen zoals vloeiendere routekeuze of voertuigplatoons. Op het tussenniveau vatten ze de omstandigheden per rijstrook en kruispunt samen, zoals wachtrijen en dichtheden — informatie die cruciaal is voor het afstemmen van verkeerslichten. Op het breedste niveau aggregeren ze condities over hele stadsgebieden, wat strategieën ondersteunt die reguleren hoeveel voertuigen een congestiegevoelig gebied mogen binnenrijden. Dit alles wordt verpakt in een gemeenschappelijk simulatiedataformaat (CityFlow), zodat verschillende regelmethoden eerlijk en efficiënt getest kunnen worden.
Controleren dat de digitale stad overeenkomt met de realiteit
Om er zeker van te zijn dat hun gereconstrueerde wereld op de echte lijkt, valideren de onderzoekers zowel de kaarten als de ritten. Ze vergelijken het geconverteerde wegennet met de oorspronkelijke geografische gegevens en constateren dat de meeste verbindingen en posities binnen slechts een paar meter behouden blijven. Voor ritten simuleren ze voertuigen langs een geselecteerde weg en vergelijken reistijden met echte metingen; de gemiddelden liggen zeer dicht bij elkaar, met kleine verschillen die verklaard kunnen worden door factoren zoals dat bestuurders in de echte wereld af en toe de snelheidslimiet overschrijden. Ze tonen ook aan dat de afgeleide statusgegevens geavanceerde strategieën kunnen ondersteunen: het gebruik van rijstrookniveau-informatie voor een druktegebaseerde signaalregeling, vervolgens het toevoegen van stadbrede "perimeter"-regeling om te voorkomen dat een kerngebied overbelast raakt, en ten slotte laten zien dat het omleiden van één voertuig op basis van deze informatie zijn reistijd in zwaar verkeer kan verkorten.
Wat dit betekent voor alledaagse bestuurders
Voor niet-specialisten ligt de betekenis van dit werk minder in de algoritmen en meer in de basis die het biedt. Door gedetailleerde, goed gevalideerde en openlijk gedocumenteerde datasets vrij te geven, bieden de auteurs verkeerskundigen en AI-onderzoekers een realistisch speelveld om nieuwe regelingsschema’s te ontwerpen en te testen voordat ze echte straten beïnvloeden. Met nauwkeurige representaties van hoe wegen zijn aangelegd, hoe signalen werken en hoe de vraag over dagen en weken stijgt en daalt, kunnen toekomstige hulpmiddelen worden afgestemd om vertragingen te verminderen, brandstof te besparen en reizen door de stad voorspelbaarder te maken. Kortom: deze datasets vormen een essentiële tussenstap naar verkeerssystemen die reageren op de complexiteit van de echte wereld in plaats van op geïdealiseerde modellen.
Bronvermelding: Ma, Q., Guo, X., Zhong, W. et al. City-scale high-resolution traffic datasets with refined networks for hierarchical traffic control. Sci Data 13, 547 (2026). https://doi.org/10.1038/s41597-026-06892-2
Trefwoorden: stedelijke verkeersgegevens, hiërarchische verkeersregeling, verkeerssimulatie, automatische voertuigidentificatie, mobiliteit op stadsschaal