Clear Sky Science · fr
Jeux de données de trafic à haute résolution à l’échelle de la ville avec réseaux raffinés pour le contrôle hiérarchique du trafic
Pourquoi le trafic urbain a besoin de meilleures données
Quiconque s’est déjà retrouvé coincé à une série de feux rouges ou a avancé au pas sur une rue encombrée du centre-ville a ressenti le caractère chaotique du trafic urbain. Pourtant, la plupart des systèmes qui pilotent ces feux et gèrent les flux s’appuient encore sur des données incomplètes et peu détaillées. Cet article présente une nouvelle famille de jeux de données à l’échelle de la ville, conçue pour offrir aux chercheurs et aux urbanistes une image beaucoup plus précise de la façon dont les véhicules se déplacent réellement dans les réseaux routiers, ouvrant la voie à un pilotage de la congestion plus intelligent et mieux coordonné.
De quelques rues à des villes entières
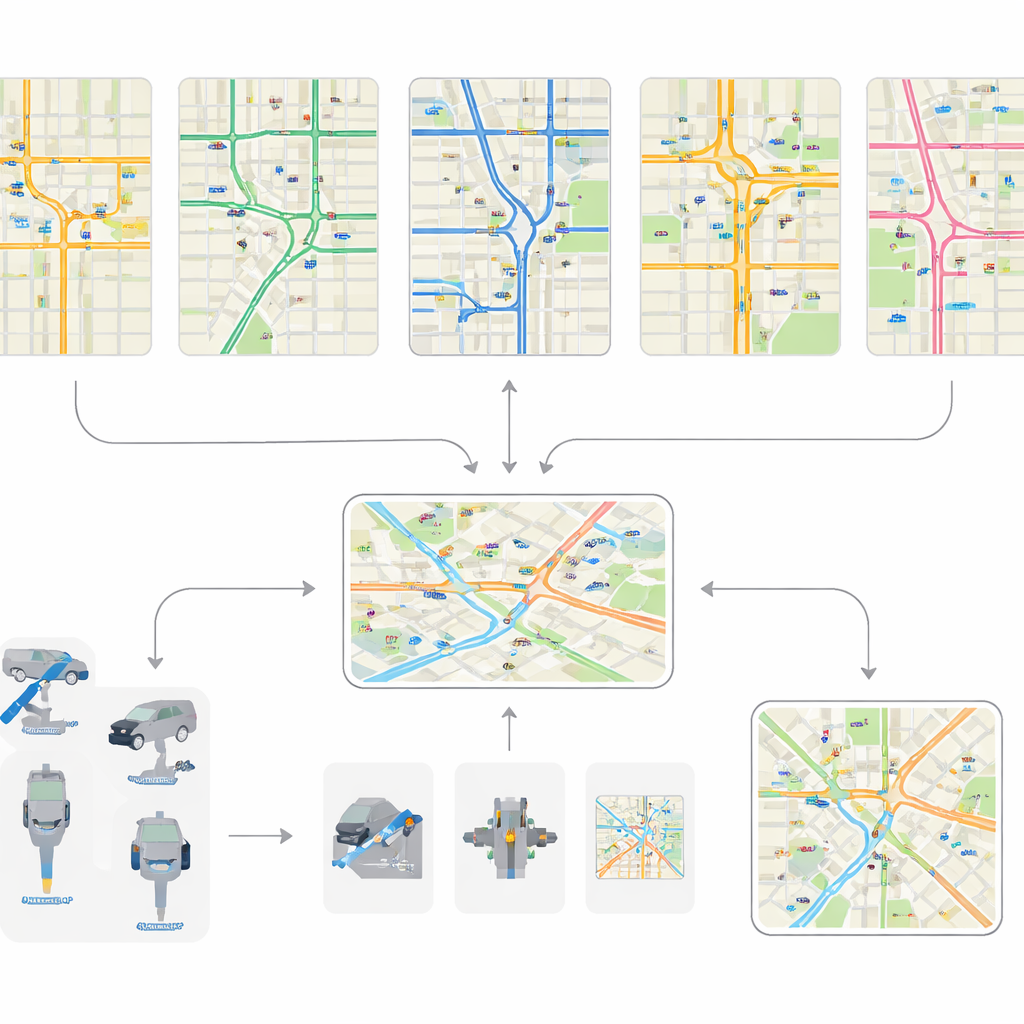
Les auteurs rassemblent et uniformisent des données de trafic détaillées provenant de cinq zones urbaines très différentes : Jinan, Hangzhou, Manhattan, Nanchang et Xuancheng. Ces villes couvrent tout, de courts corridors artériels avec une douzaine d’intersections à de vastes réseaux comportant des milliers de carrefours. Les jeux de données ouverts antérieurs se concentraient généralement sur de petites grilles régulières et des instantanés d’une heure. En revanche, cette collection capture une grande variété d’agencements routiers, de formes d’intersections et de profils de demande. L’un des apports marquants est le jeu de données de Xuancheng, qui représente presque une ville entière avec des centaines d’intersections modélisées en détail fin, y compris l’organisation des voies individuelles et la structure des intersections complexes.
Voir chaque voiture, pas seulement un échantillon
La plupart des données de trafic existantes proviennent de caméras ou de capteurs épars, qui n’observent que des portions du réseau et pour de courtes périodes. Les données de Xuancheng adoptent une approche différente. La ville dispose d’un système d’identification automatique des véhicules (AVI) installé sur des segments routiers clés, enregistrant les moments d’entrée et de sortie de chaque véhicule. En appariant des identifiants anonymes issus des relevés d’entrée et de sortie, les auteurs reconstruisent des trajets complets pour des centaines de milliers de déplacements par jour sur un mois entier. Cela leur permet d’observer comment les conducteurs choisissent réellement leurs itinéraires, comment les flux varient entre semaine et week-end, et comment les jours fériés modifient la demande. Les véhicules sont aussi classés en grandes catégories, telles que passagers et fret, pour que les simulations reflètent l’impact des différents types de véhicules sur le trafic.
Transformer des relevés désordonnés en une carte commune
Parce que les données brutes des cinq villes étaient stockées dans des formats et des niveaux de détail différents, l’équipe a développé un flux de traitement unifié. D’abord, ils reconstruisent chaque réseau routier sous forme de carte numérique cohérente, identifiant intersections et voies de liaison même lorsque les sources originales utilisent des définitions géométriques distinctes. Ils estiment la taille et la position des intersections en englobant les formes brutes dans des rectangles simples et alignent les approches sur les directions cardinales à l’aide d’une méthode d’optimisation. Ensuite, ils standardisent les feux de signalisation en définissant un petit ensemble de motifs de mouvement typiques — tels que les virages à gauche ou les mouvements droits le long de chaque corridor — et en appariant automatiquement chaque intersection réelle à ces motifs. Enfin, ils construisent les flux de véhicules et nettoient les données : les itinéraires invraisemblables sont supprimés, les segments manquants sont inférés à partir du réseau, et les trajets continus sont assemblés à partir de nombreux relevés capteurs courts.
Du véhicule isolé aux réseaux entiers
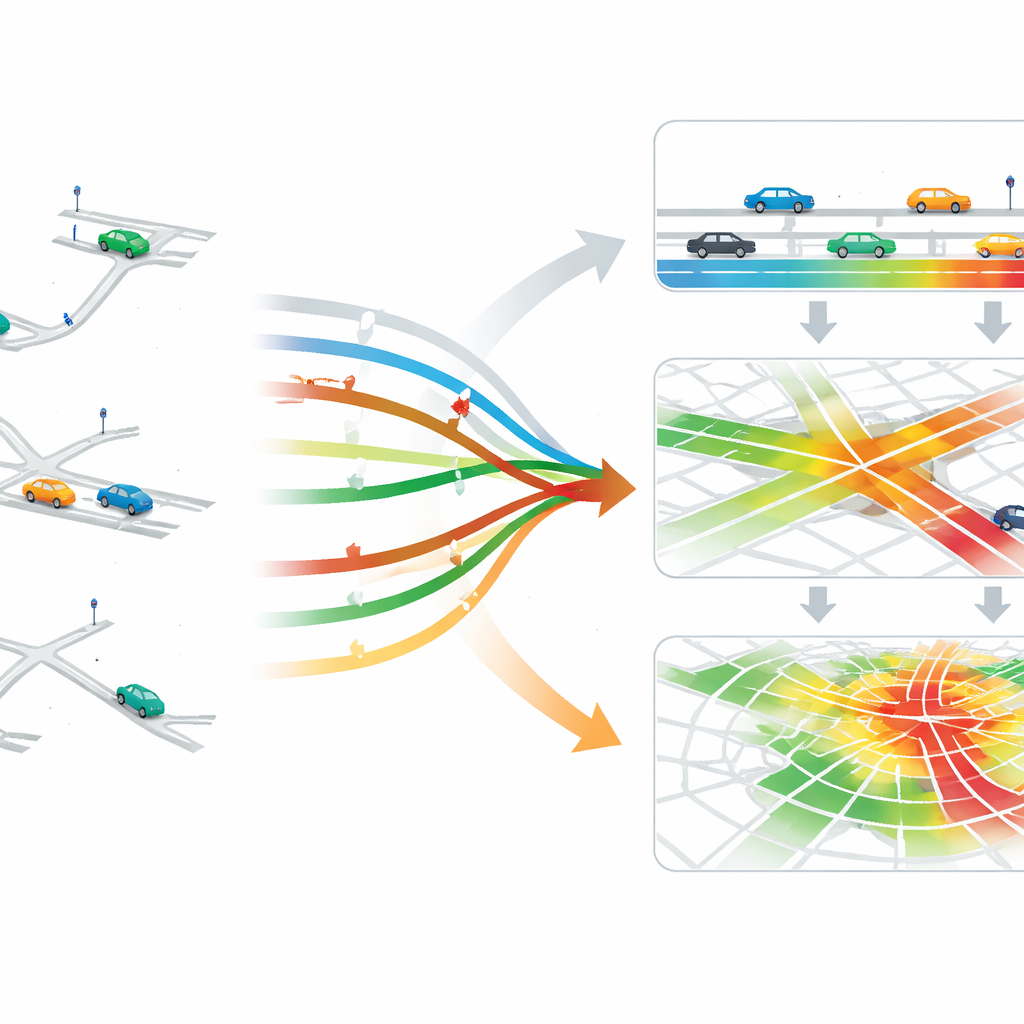
Une fois les trajets et les réseaux en place, les auteurs génèrent des données d’« état » de trafic à trois niveaux. Au niveau le plus détaillé, ils suivent les véhicules individuels, y compris leurs positions et vitesses, ce qui permet de tester des idées comme un routage plus fluide ou des pelotons de véhicules. Au niveau intermédiaire, ils résument les conditions sur chaque voie et intersection, telles que files d’attente et densités — informations cruciales pour le réglage des signaux. Au niveau le plus large, ils agrègent les conditions sur des zones entières de la ville, soutenant des stratégies qui régulent le nombre de véhicules autorisés à entrer dans une zone congestionnée. Le tout est fourni dans un format de simulation commun (CityFlow), afin que différentes méthodes de contrôle puissent être testées de façon équitable et efficace.
Vérifier que la ville numérique correspond à la réalité
Pour s’assurer que leur monde reconstruit ressemble au réel, les chercheurs valident à la fois les cartes et les trajets. Ils comparent le réseau routier converti aux données géographiques d’origine et constatent que la plupart des connexions et positions sont préservées à quelques mètres près. Pour les trajets, ils simulent des véhicules le long d’une route sélectionnée et comparent les temps de parcours aux mesures réelles ; les moyennes sont très proches, avec de petites différences expliquées par des facteurs comme des conducteurs dépassant occasionnellement les limites de vitesse dans la réalité. Ils montrent également que les données d’état dérivées peuvent soutenir des stratégies avancées : en utilisant des informations au niveau des voies pour appliquer un contrôle des feux basé sur la pression, puis en ajoutant un contrôle « périmètre » à l’échelle de la ville pour éviter la surcharge d’une zone centrale, et enfin en démontrant que le reroutage d’un seul véhicule sur la base de ces informations peut réduire son temps de trajet en cas de forte circulation.
Ce que cela signifie pour les conducteurs quotidiens
Pour les non-spécialistes, l’intérêt de ce travail réside moins dans les algorithmes que dans la base qu’il établit. En publiant des jeux de données détaillés, bien validés et documentés ouvertement, les auteurs fournissent aux ingénieurs du trafic et aux chercheurs en IA un terrain réaliste pour concevoir et tester de nouveaux schémas de contrôle avant de les appliquer sur les voies réelles. Avec des représentations précises de la configuration des routes, du fonctionnement des signaux et de l’évolution de la demande sur des jours et des semaines, les outils futurs pourront être réglés pour réduire les retards, économiser du carburant et rendre les déplacements urbains plus prévisibles. En bref, ces jeux de données constituent une étape essentielle vers des systèmes de trafic qui réagissent à la complexité du monde réel plutôt qu’à des modèles idéalisés.
Citation: Ma, Q., Guo, X., Zhong, W. et al. City-scale high-resolution traffic datasets with refined networks for hierarchical traffic control. Sci Data 13, 547 (2026). https://doi.org/10.1038/s41597-026-06892-2
Mots-clés: données de trafic urbain, contrôle hiérarchique du trafic, simulation de trafic, identification automatique des véhicules, mobilité à l’échelle de la ville