Clear Sky Science · nl
Oneerlijke ongelijkheid in het onderwijs: een referentie voor AI-eerlijkheidsonderzoek
Waarom dit belangrijk is voor studenten en de samenleving
Wereldwijd vertrouwen scholen steeds vaker op gegevens en algoritmen om te bepalen wie hulp nodig heeft, wie waarschijnlijk zal slagen en zelfs wie toegang krijgt tot speciale programma’s. Maar als de gegevens die deze systemen voeden bevooroordeeld zijn, kunnen de algoritmen ongerechtigheid ongemerkt verergeren in plaats van tegengaan. Dit artikel introduceert een nieuwe onderwijsdataset die speciaal is ontwikkeld zodat onderzoekers oneerlijke behandeling door kunstmatige intelligentie kunnen bestuderen en verminderen, met als doel alle studenten—vooral degenen uit achtergestelde milieus—te laten profiteren van datagedreven hulpmiddelen.
Een nieuw venster op echte klaslokalen
De dataset is afkomstig van openbare scholen op de Canarische Eilanden, Spanje, en volgt meer dan veertigduizend studenten over meerdere schooljaren. In plaats van alleen testresultaten vast te leggen, combineert ze informatie van studenten, hun gezinnen, hun docenten en schooldirecteuren. Dit betekent dat niet alleen wordt vastgelegd hoe goed leerlingen het deden in wiskunde, Spaans en Engels, maar ook gezinsinkomen en scholingsniveau, leermiddelen thuis, lespraktijken in het klaslokaal en hoe leerlingen zich voelen over school. Doordat de gegevens meerdere jaren en verschillende leerjaren bestrijken, kunnen onderzoekers volgen hoe kinderen zich ontwikkelen en waar ze mogelijk achterblijven of voortijdig uitvallen.
Rommelige schoolgegevens omzetten in eerlijke testomgevingen
Gegevens uit de praktijk zijn rommelig: ze bevatten honderden vragen, veel overlappende onderwerpen en veel lege antwoorden. Sommige gezinnen slaan gevoelige vragen over inkomen of woonsituatie over, vaak uit angst of schaamte. In plaats van deze lacunes eenvoudigweg met gissingen op te vullen, maken de auteurs zorgvuldig onderscheid tussen willekeurig ontbrekende antwoorden en antwoorden die waarschijnlijk sociale kwetsbaarheid weerspiegelen. Voor die laatste vermijden ze automatische reparatie die ongelijkheid zou kunnen verbergen in plaats van onthullen. In samenwerking met onderwijs- en economie-experts groeperen ze gerelateerde vragen tot een kleiner aantal duidelijke, gemiddelde indicatoren—zoals hoe vaak een leerling een computer gebruikt of hoe sterk de band met docenten voelt—terwijl ze bijzonder gevoelige patronen ongemoeid laten zodat onderzoekers daar voorzichtig mee om kunnen gaan.
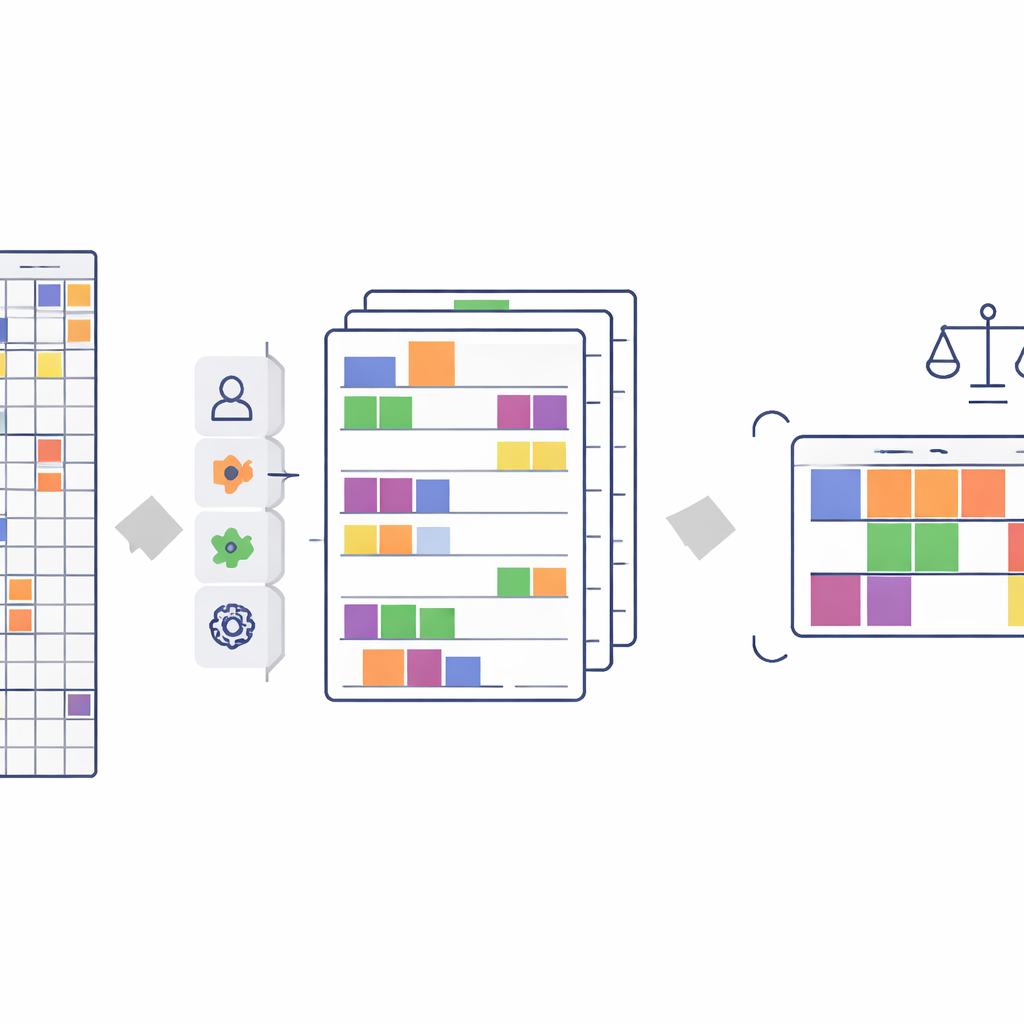
Het verhaal in de cijfers bewaren
Bij het verkleinen van meer dan 500 enquêtevragen naar ongeveer 140 kenmerken bestaat het reële risico dat het verhaal dat de gegevens vertellen wordt vervormd. Om te controleren dat dit niet is gebeurd, voert het team een reeks statistische tests uit. Ze vergelijken de originele en de vereenvoudigde gegevens om te zien of ze nog steeds dezelfde relaties coderen—zowel tussen achtergrond van de leerling en prestaties, als tussen gevoelige kenmerken (zoals geslacht, geboorteland of gezinsinkomen) en uitkomsten. Met behulp van geavanceerde afhankelijkheidsmaten en verschillende eerlijkheidscontroles tonen ze aan dat de nieuwe, compacte dataset bijna alle informatie uit het origineel behoudt en, cruciaal, bestaande oneerlijke patronen noch verergert noch verzacht.
Wat onderzoekers met deze bron kunnen onderzoeken
Omdat de dataset openbaar beschikbaar is in een gebruiksvriendelijk formaat, biedt ze een gemeenschappelijk “testbank” voor veel soorten studies. Wetenschappers kunnen algoritmen bouwen en vergelijken om studenten te rangschikken voor beperkte plaatsen in programma’s, terwijl ze controleren dat selectie bepaalde groepen niet benadeelt. Ze kunnen hulpmiddelen ontwerpen om leerlingen te signaleren die stilletjes achteruitgaan en verklaren welke factoren daar het meest verantwoordelijk voor zijn, zodat leraren en beleidsmakers kunnen ingrijpen. De gegevens ondersteunen ook vroegtijdige waarschuwingsmodellen voor schooluitval en bredere analyses van hoe gezinsmiddelen, het beroep en de opleiding van ouders en de schoolcontext de leerkansen vormen. Gedetailleerde documentatie en open-source code maken het eenvoudig om het werk van de auteurs te reproduceren en uit te breiden.
Hoe dit eerlijkere AI in het onderwijs bevordert
Kort gezegd levert het artikel een zorgvuldig opgeschoonde, goed gedocumenteerde schooldataset die onderzoekers in staat stelt te testen of hun algoritmen leerlingen eerlijk behandelen. Het respecteert privacywetten, behoudt de echte patronen in de data—ook de ongemakkelijke—en legt bloot hoe ontbrekende antwoorden zelf signalen van moeilijkheden kunnen zijn. Door zowel de ruwe informatie als een samengestelde versie die is ontworpen voor algoritmisch gebruik aan te bieden, geven de auteurs de gemeenschap een gedeelde basis om AI-hulpmiddelen te bouwen, vergelijken en verbeteren die erop gericht zijn studenten te ondersteunen zonder oneerlijke ongelijkheid te bestendigen.
Bronvermelding: Giovanelli, J., Magnini, M., Ciatto, G. et al. Unfair Inequality in Education: A Benchmark for AI-Fairness Research. Sci Data 13, 572 (2026). https://doi.org/10.1038/s41597-026-06827-x
Trefwoorden: onderwijsgegevens, algorithmische eerlijkheid, studentprestaties, sociaal-economische ongelijkheid, verantwoorde AI