Clear Sky Science · en
Unfair Inequality in Education: A Benchmark for AI-Fairness Research
Why this matters for students and society
Across the world, schools increasingly rely on data and algorithms to decide who needs help, who is likely to succeed, and even who gets access to special programs. But if the data feeding these systems is biased, the algorithms can quietly deepen unfairness instead of fighting it. This paper introduces a new education dataset built specifically so researchers can study and reduce unfair treatment in artificial intelligence, with the goal of helping all students—especially those from disadvantaged backgrounds—benefit from data-driven tools.
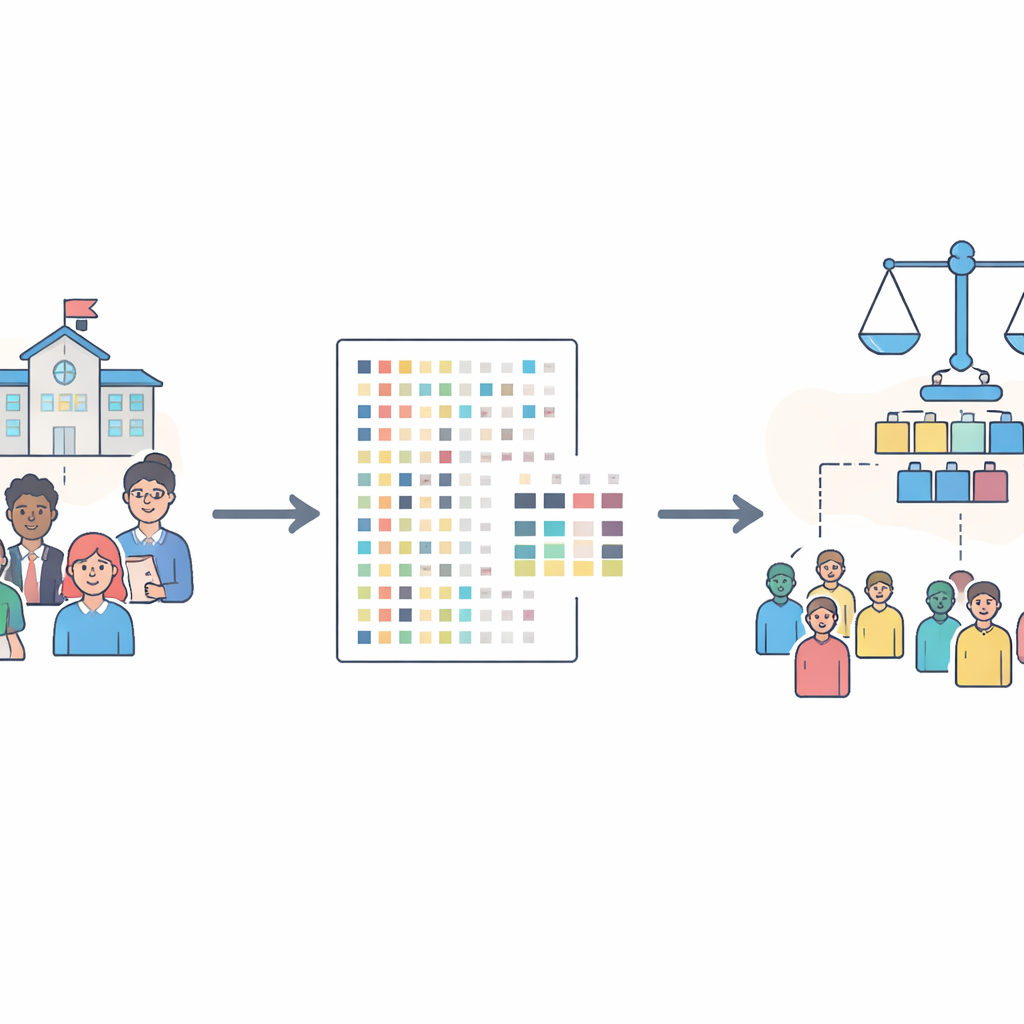
A new window into real classrooms
The dataset comes from public schools in the Canary Islands, Spain, and follows more than forty thousand students over multiple school years. Instead of just recording test scores, it combines information from students, their families, their teachers, and school principals. This means it captures not only how well students did in math, Spanish, and English, but also family income and education, learning resources at home, teaching practices in the classroom, and how students feel about school. By spanning several years and multiple grade levels, the data allows researchers to track how children progress and where they might fall behind or drop out.
Turning messy school data into fair test beds
Real-life education data is messy: it contains hundreds of questions, many overlapping topics, and lots of blank answers. Some families skip sensitive questions about income or living conditions, often because of fear or stigma. Rather than simply filling in these gaps with guesses, the authors carefully distinguish between random missing answers and those that likely reflect social vulnerability. For the latter, they avoid automatic repair that might hide inequality instead of revealing it. Working with education and economics experts, they group related questions into a smaller set of clear, averaged indicators—such as how often a student uses a computer or how strong their bond with teachers feels—while leaving especially sensitive patterns intact for researchers to handle with care.
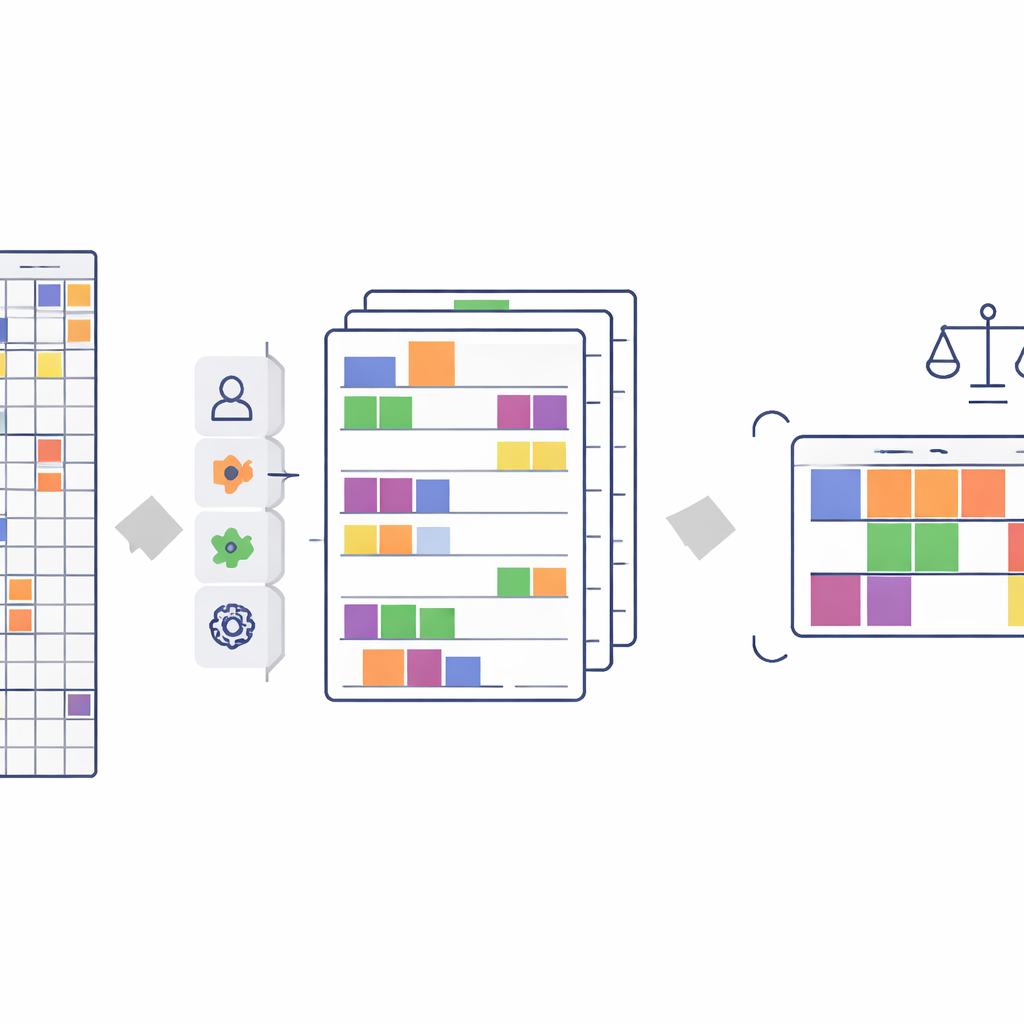
Keeping the story in the numbers
When shrinking more than 500 survey questions down to about 140 features, there is a real risk of distorting the story the data tells. To check that this did not happen, the team runs a battery of statistical tests. They compare the original and simplified data to see whether they still encode the same relationships—both between student background and performance, and between sensitive traits (such as gender, birthplace, or family income) and outcomes. Using advanced measures of dependence and several fairness checks, they show that the new, compact dataset preserves almost all of the information found in the original, and, crucially, does not make existing unfair patterns any better or worse.
What researchers can explore with this resource
Because the dataset is publicly available in an easy-to-use format, it offers a common “test bench” for many kinds of studies. Scientists can build and compare algorithms for ranking students for limited places in programs, while checking that selection does not disadvantage certain groups. They can design tools to spot students who are quietly slipping behind and explain which factors are most responsible, so teachers and policymakers can respond. The data also supports early warning models for school dropout, and broader analyses of how family resources, parents’ jobs and education, and school context shape learning chances. Detailed documentation and open-source code make it straightforward to reproduce and extend the authors’ work.
How this advances fair AI in education
In plain terms, the article delivers a carefully cleaned, well-documented school dataset that lets researchers stress-test whether their algorithms treat students fairly. It respects privacy laws, preserves the real patterns in the data—including uncomfortable ones—and exposes how missing answers themselves may signal hardship. By offering both the raw information and a curated version designed for algorithmic use, the authors give the community a shared foundation to build, compare, and improve AI tools that aim to support students without reinforcing unfair inequality.
Citation: Giovanelli, J., Magnini, M., Ciatto, G. et al. Unfair Inequality in Education: A Benchmark for AI-Fairness Research. Sci Data 13, 572 (2026). https://doi.org/10.1038/s41597-026-06827-x
Keywords: educational data, algorithmic fairness, student performance, socioeconomic inequality, responsible AI