Clear Sky Science · de
Ungerechte Ungleichheit in der Bildung: Ein Benchmark für die Forschung zur Fairness von KI
Warum das für Schüler und Gesellschaft wichtig ist
Weltweit verlassen sich Schulen zunehmend auf Daten und Algorithmen, um zu entscheiden, wer Unterstützung braucht, wer voraussichtlich Erfolg hat und wer Zugang zu speziellen Programmen erhält. Wenn die Daten, die diese Systeme speisen, jedoch verzerrt sind, können die Algorithmen unbemerkt Ungerechtigkeiten vertiefen statt abzubauen. Dieses Papier stellt einen neuen Bildungsdatensatz vor, der speziell dafür entwickelt wurde, damit Forschende unfaire Behandlung in der künstlichen Intelligenz untersuchen und verringern können, mit dem Ziel, allen Schülern — insbesondere solchen aus benachteiligten Verhältnissen — den Nutzen datenbasierter Werkzeuge zu sichern.
Ein neues Fenster in reale Klassenzimmer
Der Datensatz stammt aus öffentlichen Schulen auf den Kanarischen Inseln, Spanien, und begleitet mehr als vierzigtausend Schüler über mehrere Schuljahre. Statt nur Testergebnisse zu erfassen, kombiniert er Informationen von Schülern, ihren Familien, ihren Lehrkräften und Schulleitungen. Das bedeutet, dass er nicht nur abbildet, wie gut Schüler in Mathematik, Spanisch und Englisch abgeschnitten haben, sondern auch Familieneinkommen und Bildung, Lernressourcen zu Hause, Lehrpraktiken im Unterricht und wie Schüler die Schule erleben. Durch die Abdeckung mehrerer Jahre und Jahrgangsstufen ermöglicht die Datengrundlage Forschenden, den Fortschritt von Kindern zu verfolgen und zu identifizieren, wo sie zurückfallen oder die Schule abbrechen könnten.
Unordentliche Schul-Daten in faire Testumgebungen verwandeln
Bildungsdaten aus der Praxis sind unordentlich: sie enthalten Hunderte von Fragen, viele überlappende Themen und zahlreiche fehlende Antworten. Manche Familien überspringen sensible Fragen zu Einkommen oder Lebensbedingungen, oft aus Angst oder Stigmatisierung. Anstatt diese Lücken einfach mit Schätzungen zu füllen, unterscheiden die Autorinnen und Autoren sorgfältig zwischen zufällig fehlenden Antworten und solchen, die wahrscheinlich soziale Verwundbarkeit widerspiegeln. Bei Letzteren vermeiden sie automatische Reparaturen, die Ungleichheit verschleiern könnten, statt sie zu offenbaren. In Zusammenarbeit mit Fachleuten aus Bildung und Ökonomie bündeln sie verwandte Fragen zu einer kleineren Anzahl klarer, gemittelter Indikatoren — etwa wie häufig ein Schüler einen Computer nutzt oder wie stark die Bindung zu Lehrkräften erscheint — und belassen besonders sensible Muster intakt, damit Forschende sie mit Vorsicht behandeln können.
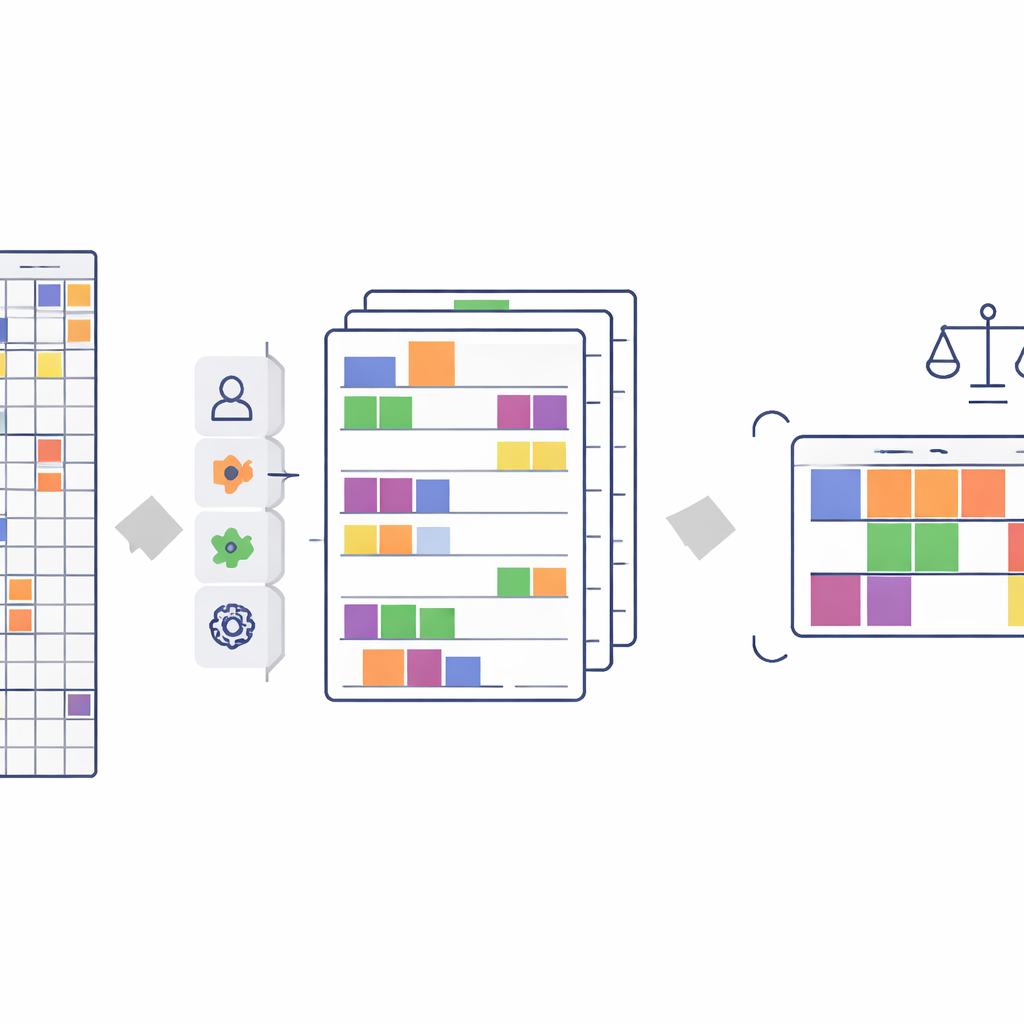
Die Geschichte in den Zahlen bewahren
Beim Reduzieren von mehr als 500 Umfragefragen auf etwa 140 Merkmale besteht das reale Risiko, die in den Daten erzählte Geschichte zu verzerren. Um zu prüfen, dass dies nicht geschieht, führt das Team eine Reihe statistischer Tests durch. Sie vergleichen die ursprünglichen und die vereinfachten Daten, um zu sehen, ob sie noch dieselben Zusammenhänge kodieren — sowohl zwischen Hintergrund und Leistung der Schüler als auch zwischen sensiblen Merkmalen (wie Geschlecht, Geburtsort oder Familieneinkommen) und Ergebnissen. Mit fortgeschrittenen Abhängigkeitsmaßen und mehreren Fairness-Checks zeigen sie, dass der neue, kompakte Datensatz nahezu alle Informationen des Originals bewahrt und entscheidend keine bestehenden unfairen Muster besser oder schlechter macht.
Was Forschende mit dieser Ressource untersuchen können
Da der Datensatz öffentlich und in einem einfach zu nutzenden Format verfügbar ist, bietet er eine gemeinsame „Prüfbank“ für viele Studienarten. Wissenschaftlerinnen und Wissenschaftler können Algorithmen entwickeln und vergleichen, die Schüler für begrenzte Plätze in Programmen einstufen, und dabei prüfen, ob die Auswahl bestimmte Gruppen benachteiligt. Sie können Werkzeuge entwerfen, die Schüler identifizieren, die still und leise zurückfallen, und erklären, welche Faktoren am stärksten verantwortlich sind, damit Lehrkräfte und Entscheidungsträger reagieren können. Die Daten unterstützen auch Frühwarnmodelle für Schulabbrüche sowie umfassendere Analysen, wie Familienressourcen, Berufe und Bildung der Eltern sowie der schulische Kontext die Lernchancen formen. Detaillierte Dokumentation und Open-Source-Code machen es einfach, die Arbeit der Autorinnen und Autoren zu reproduzieren und zu erweitern.
Wie dies faire KI in der Bildung voranbringt
Kurz gesagt liefert der Artikel einen sorgfältig bereinigten, gut dokumentierten Schuldatensatz, mit dem Forschende testen können, ob ihre Algorithmen Schüler fair behandeln. Er respektiert Datenschutzgesetze, bewahrt die realen Muster in den Daten — auch unbequeme — und macht sichtbar, wie fehlende Antworten selbst auf Belastungen hinweisen können. Indem sowohl die Rohdaten als auch eine kuratierte Version für algorithmische Nutzung angeboten werden, geben die Autorinnen und Autoren der Community eine gemeinsame Grundlage, um KI-Tools zu entwickeln, zu vergleichen und zu verbessern, die Schüler unterstützen sollen, ohne ungerechte Ungleichheit zu verstärken.
Zitation: Giovanelli, J., Magnini, M., Ciatto, G. et al. Unfair Inequality in Education: A Benchmark for AI-Fairness Research. Sci Data 13, 572 (2026). https://doi.org/10.1038/s41597-026-06827-x
Schlüsselwörter: Bildungsdaten, algorithmische Fairness, Schülerleistungen, sozioökonomische Ungleichheit, verantwortliche KI