Clear Sky Science · nl
Ongecontroleerde defectclustering in atomaire-resolutie-microscopie met een convolutionele variationale autoencoder
Waarom kleine onvolkomenheden in kristallen ertoe doen
Moderne elektronica, zonnecellen en sensoren zijn afhankelijk van materialen die op atomaire schaal ogenschijnlijk perfect geordend zijn. In werkelijkheid zit elk kristal vol met kleine onvolkomenheden — ontbrekende atomen, extra atomen of lichte verschuivingen in het patroon — die een apparaat juist efficiënter kunnen maken of stilletjes de prestaties kunnen verwoesten. Het artikel achter deze samenvatting presenteert een methode waarmee kunstmatige intelligentie deze onvolkomenheden automatisch kan opsporen in beelden met hoge resolutie, zonder menselijke labeling of experttuning, en daarmee de weg vrijmaakt voor snellere en minder bevooroordeelde materiaalontdekking.
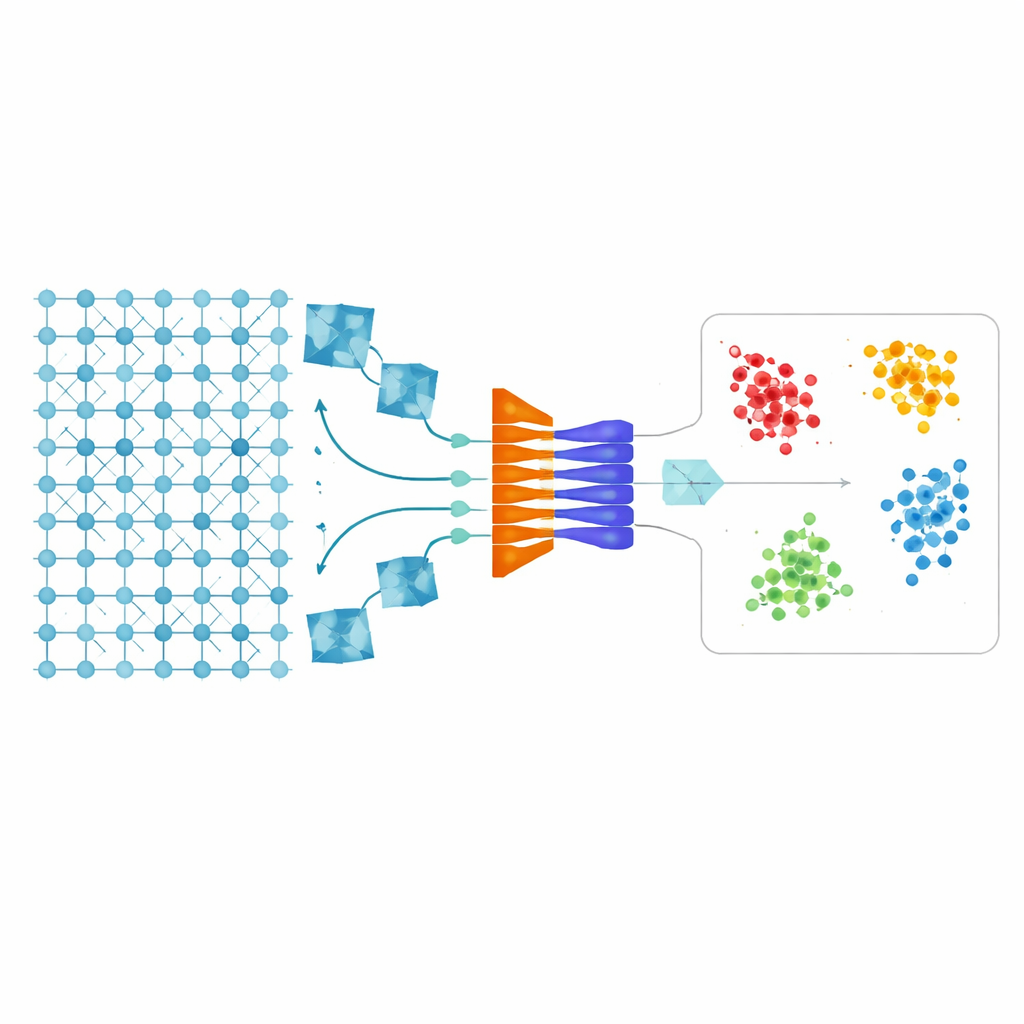
Een computer laten leren hoe “perfect” eruitziet
De onderzoekers vertrekken van een eenvoudig idee: in plaats van de computer elke mogelijke soort defect te leren, leer je hem alleen hoe een perfect kristal eruitziet. Ze gebruiken atomaire-resolutiebeelden van een krachtige elektronenmicroscoop, waar elke heldere stip overeenkomt met een kolom van atomen. Een speciaal type neuraal netwerk, een convolutionele variationale autoencoder, wordt getraind op regio’s van het beeld waarvan wordt aangenomen dat ze vrij zijn van defecten. Na verloop van tijd leert dit netwerk het regelmatige, herhalende patroon van het kristal en wordt het zeer bedreven in het reconstrueren van hoe een ideale, onaangetaste kristalrooster eruit zou moeten zien.
Verschillen omzetten in een kaart van onvolkomenheden
Zodra het netwerk het ideale patroon heeft geleerd, wordt elk nieuw microscoopfragment erdoor gevoed. Het model produceert zijn beste schatting van een vlekkeloze versie van dat fragment. Door deze schatting van het echte beeld af te trekken, ontstaat een “verschil”-afbeelding die alleen benadrukt wat niet past in het geleerde patroon — zoals een extra atoom, een ontbrekende atoomdubbelstructuur of een verschuiving in stapeling. Een aanvullende filterstap verwijdert willekeurige ruis en randartefacten, waardoor een schoon signaal overblijft dat zich richt op echte structurele afwijkingen in plaats van op hoe het afbeeldingsvenster is uitgesneden. In feite herformuleert het systeem het probleem van “leer alle mogelijke defecten” naar “vind alles wat niet normaal is.”
Van ruwe beelden naar betekenisvolle groepen
Om deze onvolkomenheden in nuttige categorieën te sorteren, zet het team elk fragment om in een set van 47 eenvoudige numerieke beschrijvingen. Die beschrijven onder andere hoe helder het fragment gemiddeld is, hoe scheef de intensiteitsverdeling is, hoeveel scherpe kenmerken het bevat en hoe de patronen zich ruimtelijk herhalen. Vervolgens snoeien ze deze lijst in drie stappen: het verwijderen van redundante beschrijvingen die vrijwel identiek gedrag vertonen, het wegstrepen van beschrijvingen die niet helpen beelden in onderscheidende groepen te verdelen, en het filtreren van kenmerken die vrijwel niet variëren. Deze shortlist levert een compactere, meer informatieve verzameling kenmerken op die echte structurele verschillen beter vastlegt en tegelijk ruis en rekenlast reduceert.
Het aantal defecttypen door de data laten bepalen
Met deze verfijnde kenmerken gebruiken de auteurs standaard clustertools zodat de data zichzelf kan organiseren. Ze comprimeren eerst de kenmerkruimte met hoofdcomponentenanalyse, die de belangrijkste variaties behoudt en tegelijkertijd het aantal dimensies vermindert. Daarna passen ze herhaaldelijk de klassieke k-means-clustering toe, terwijl ze systematisch zowel het aantal clusters als het aantal hoofdcomponenten variëren. Een kwaliteitsmaat, de silhouette-score, geeft aan hoe goed gescheiden de gevonden groepen zijn. Door mogelijkheden af te tasten, identificeert het kader automatisch niet alleen waar de clusters liggen, maar ook hoeveel defecttypes het dataset het beste beschrijven — zonder voorafgaande labels of handmatige keuzes.
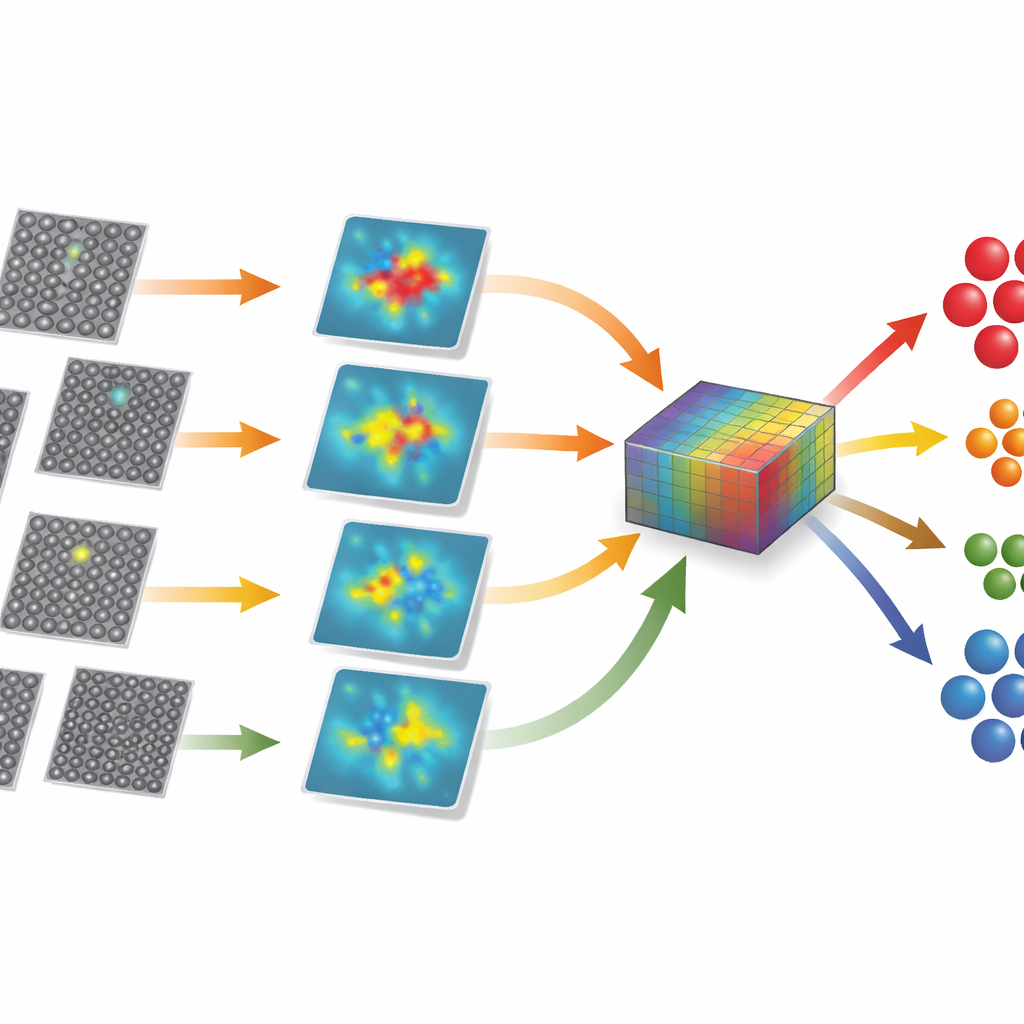
De aanpak aantonen op twee verschillende kristallen
De methode is getest op beelden van twee goed bestudeerde materialen: cadmiumtelluride, gebruikt in dunnefilmzonnecellen, en strontiumtitaan, een model-oxidekristal. In cadmiumtelluride bevat de dataset bulkregio’s, meerdere typen stapelingsfouten, speciale dislocatiestructuren en keergrenzen, naast kunstmatig toegevoegde extra en ontbrekende atomen. Ondanks subtiele contrastverschillen en storende randeffecten herstelt het kader automatisch zeven verschillende clusters die overeenkomen met deze categorieën, met slechts een handvol foutclassificaties uit meer dan duizend beelden. Toegepast op strontiumtitaan, waar sommige defecten slechts licht afwijken van het perfecte rooster, vindt dezelfde workflow opnieuw het juiste aantal groepen en sorteert de beelden met hoge nauwkeurigheid, wat aantoont dat de aanpak niet strak is afgestemd op één materiaal.
Wat dit betekent voor toekomstig materiaalonderzoek
In eenvoudige bewoordingen laat de studie zien dat een computer zichzelf kan leren atomaire defecten in microscoopbeelden te herkennen en te groeperen met minimale menselijke sturing. Door het normale patroon van een kristal te leren en zich te concentreren op de verschillen, kan het systeem grote beeldverzamelingen doorzoeken, onderscheidende defecttypes ontdekken en dat op gewone laboratoriumcomputers doen. Dit soort onbegeleid, automatisch sorteren kan onderzoekers helpen snel in kaart te brengen hoe defecten in een monster zijn verdeeld en hoe ze samenhangen met prestaties, en legt zo de basis voor meer autonome, data-gedreven ontwerp- en optimalisatieprocessen voor next-generation materialen.
Bronvermelding: Ayyubi, R.A.W., Sultanov, S., Buban, J.P. et al. Unsupervised defect clustering in atomic-resolution microscopy using a convolutional variational autoencoder. npj Comput Mater 12, 166 (2026). https://doi.org/10.1038/s41524-026-02024-x
Trefwoorden: atomaire defecten, elektronenmicroscopie, onbegeleid leren, autoencoders, materiaalcharacterisatie