Clear Sky Science · de
Unüberwachtes Clustern von Defekten in atomaufgelöster Mikroskopie mithilfe eines konvolutionalen variationalen Autoencoders
Warum winzige Fehler in Kristallen wichtig sind
Moderne Elektronik, Solarzellen und Sensoren bauen auf Materialien, die auf atomarer Skala nahezu perfekt geordnet erscheinen. In Wirklichkeit ist jeder Kristall von winzigen Fehlern durchsetzt – fehlende Atome, zusätzliche Atome oder kleine Verschiebungen im Muster –, die ein Bauteil effizienter machen oder seine Leistung heimlich beeinträchtigen können. Die hier zusammengefasste Studie stellt eine Methode vor, mit der künstliche Intelligenz diese Fehler automatisch in hochauflösenden Mikroskopbildern aufspürt, ohne menschliche Beschriftung oder aufwändige Expertenanpassung, und so einen Weg zu schnellerer und weniger voreingenommener Materialforschung eröffnet.
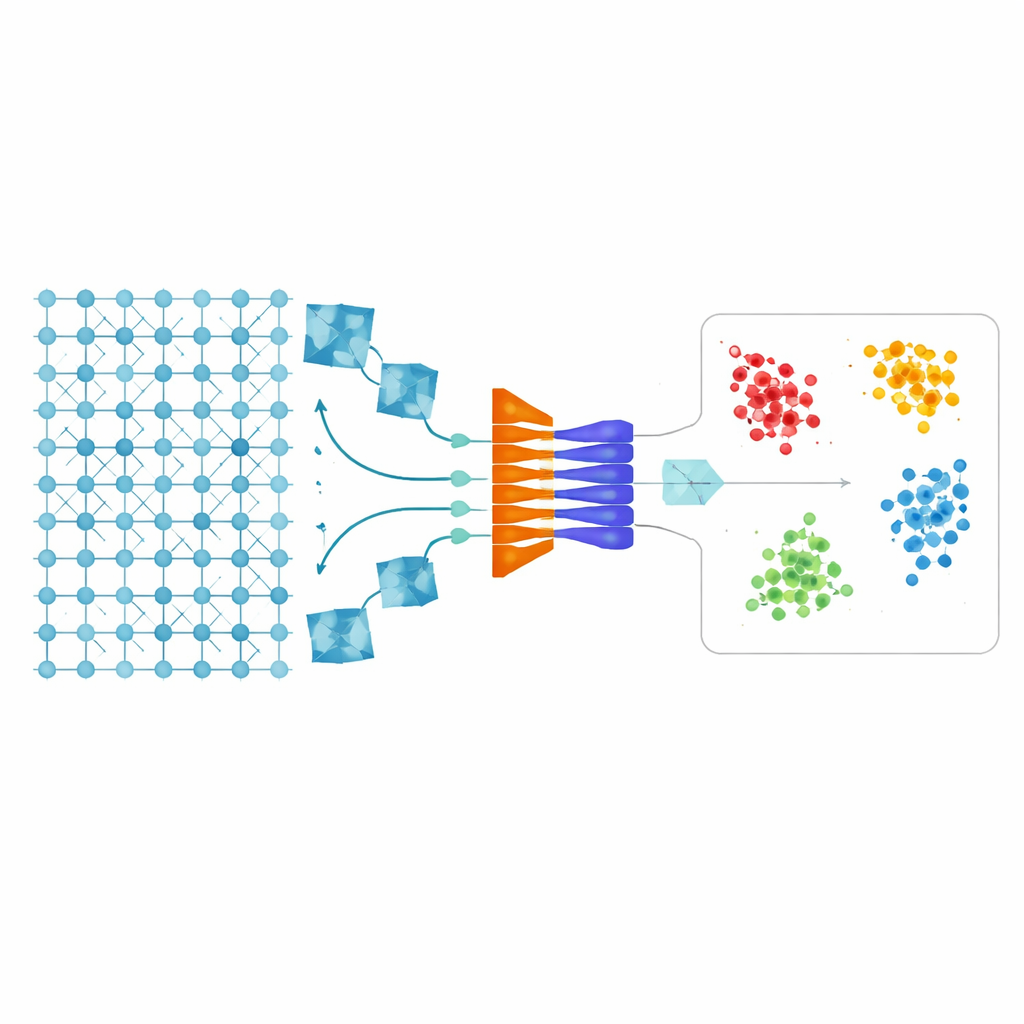
Den Computer lernen lassen, wie „perfekt“ aussieht
Die Forscher beginnen mit einer einfachen Idee: Anstatt dem Computer jeden möglichen Defekttyp beizubringen, bringen sie ihm nur bei, wie ein perfekter Kristall aussieht. Sie verwenden atomaufgelöste Bilder aus einem leistungsfähigen Elektronenmikroskop, in denen jeder helle Punkt einer Atomsäule entspricht. Ein spezieller Typ neuronaler Netze, ein konvolutionaler variationaler Autoencoder, wird auf Bildausschnitten trainiert, die als defektfrei gelten. Mit der Zeit lernt das Netzwerk das regelmäßige, sich wiederholende Muster des Kristalls und wird sehr gut darin, zu rekonstruieren, wie ein ideales, ungestörtes Gitter aussehen sollte.
Unterschiede in eine Karte der Fehler verwandeln
Sobald das Netzwerk das ideale Muster gelernt hat, wird jeder neue Mikroskopausschnitt durch das Modell geführt. Das Modell erzeugt seine beste Schätzung einer makellosen Version dieses Ausschnitts. Durch Subtraktion dieser Schätzung vom realen Bild entsteht ein „Differenz“-Bild, das nur das hervorhebt, was nicht zum gelernten Muster passt – etwa ein zusätzliches Atom, ein fehlendes Atompaar oder eine Verschiebung in der Stapelung. Ein weiterer Filterungsschritt entfernt zufälliges Rauschen und Randartefakte, sodass ein klares Signal zurückbleibt, das echte strukturelle Auffälligkeiten betont statt der Art, wie das Bildfenster geschnitten wurde. Effektiv formuliert das System das Problem um von „lerne alle möglichen Defekte“ zu „finde alles, was nicht normal ist“.
Von Rohbildern zu sinnvollen Gruppen
Um diese Fehler in nützliche Kategorien zu sortieren, wandelt das Team jeden Ausschnitt in eine Menge von 47 einfachen numerischen Beschreibern um. Diese beschreiben etwa die mittlere Helligkeit des Ausschnitts, wie asymmetrisch seine Intensitätsverteilung ist, wie viele scharfe Merkmale er enthält und wie sich seine Muster im Raum wiederholen, neben weiteren Eigenschaften. Anschließend kürzen sie diese Liste in drei Schritten: Entfernen redundanter Beschreiber, die sich nahezu identisch verhalten; Verwerfen solcher, die Bilder nicht in unterschiedliche Gruppen trennen; und Herausfiltern solcher, die kaum variieren. Diese Auswahl ergibt eine schlankere, informativerere Merkmalsmenge, die reale strukturelle Unterschiede besser erfasst und gleichzeitig Rauschen und Rechenaufwand reduziert.
Die Daten entscheiden lassen, wie viele Defekttypen es gibt
Mit diesen verfeinerten Merkmalen wenden die Autorinnen und Autoren gängige Clustering-Werkzeuge an, um die Daten selbst organisieren zu lassen. Zuerst komprimieren sie den Merkmalsraum mittels Hauptkomponentenanalyse, die die wichtigsten Variationen bewahrt und gleichzeitig die Dimensionalität reduziert. Dann nutzen sie die klassische Clustering-Methode k‑means mehrfach, während sie systematisch sowohl die Anzahl der Cluster als auch die Zahl der Hauptkomponenten variiert. Eine Qualitätsmetrik namens Silhouette-Score gibt an, wie gut die resultierenden Gruppen getrennt sind. Durch das Durchsuchen dieser Möglichkeiten identifiziert das Framework automatisch nicht nur, wo die Cluster liegen, sondern auch, wie viele Defekttypen das Datenset am besten beschreiben – ganz ohne vorherige Labels oder manuelle Entscheidungen.
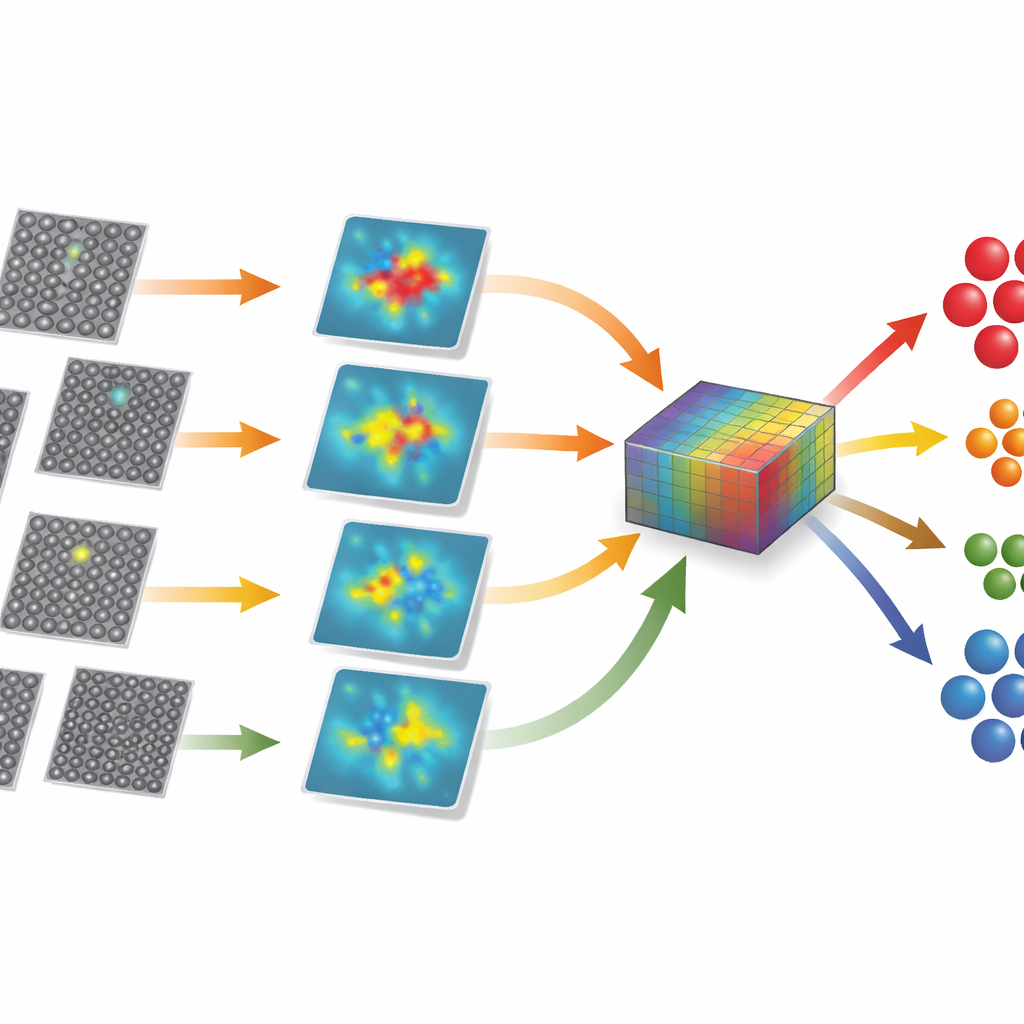
Validierung der Methode an zwei unterschiedlichen Kristallen
Die Methode wurde an Bildern zweier gut untersuchter Materialien getestet: Cadmiumtellurid, das in Dünnschicht-Solarzellen Verwendung findet, und Strontiumtitanat, einem Modelloxidkristall. Bei Cadmiumtellurid umfasst der Datensatz Volumenbereiche, mehrere Arten von Stapelfehlern, spezielle Versetzungsstrukturen und Zwillingsgrenzen sowie künstlich hinzugefügte zusätzliche und fehlende Atome. Trotz feiner Kontrastunterschiede und störender Randeffekte findet das Framework automatisch sieben verschiedene Cluster, die diesen Kategorien entsprechen, mit nur wenigen Fehlzuordnungen bei mehr als tausend Bildern. Auf Strontiumtitanat angewendet, wo einige Defekte sich nur leicht vom perfekten Gitter unterscheiden, findet derselbe Workflow erneut die korrekte Anzahl an Gruppen und ordnet die Bilder mit hoher Genauigkeit zu, was zeigt, dass der Ansatz nicht eng auf ein Material zugeschnitten ist.
Was das für die zukünftige Materialforschung bedeutet
Einfach gesagt demonstriert die Studie, dass ein Computer sich selbst beibringen kann, atomare Defekte in Mikroskopbildern mit minimaler menschlicher Anleitung zu erkennen und zu gruppieren. Indem das System das normale Muster eines Kristalls lernt und sich auf die Abweichungen konzentriert, kann es große Bildsammlungen durchforsten, verschiedene Fehlerarten entdecken und das auf gewöhnlichen Laborrechnern. Diese Art von unüberwachter, automatischer Sortierung könnte Forschern helfen, schneller abzubilden, wie Defekte in einer Probe verteilt sind und wie sie mit Eigenschaften zusammenhängen, und so die Grundlage für autonomere, datengetriebene Entwurf- und Optimierungsprozesse für Materialien der nächsten Generation legen.
Zitation: Ayyubi, R.A.W., Sultanov, S., Buban, J.P. et al. Unsupervised defect clustering in atomic-resolution microscopy using a convolutional variational autoencoder. npj Comput Mater 12, 166 (2026). https://doi.org/10.1038/s41524-026-02024-x
Schlüsselwörter: atomare Defekte, Elektronenmikroskopie, unüberwachtes Lernen, Autoencoder, Materialcharakterisierung