Clear Sky Science · nl
Interpreteerbare deep learning voor atoomklassificatie van platina-nanoclusters in STEM-beelden
Waarom kleine metaalclusters ertoe doen
Platina is een veelgebruikt metaal in schone-energietechnologieën, van brandstofcellen tot elektrolyzers, maar het is zeldzaam en duur. Op de allerkleinste schaal kan het toevoegen of wegnemen van slechts één atoom van een platina-cluster de effectiviteit van chemische reacties drastisch veranderen. Om elk atoom verstandig te gebruiken, hebben wetenschappers een betrouwbare manier nodig om direct uit microscoopbeelden te tellen hoeveel atomen in elk nanoschaal-klompje zitten. Dit artikel laat zien hoe een zorgvuldig ontworpen vorm van kunstmatige intelligentie kan leren die telling te doen op basis van elektronenmicroscoopbeelden, en zelfs kan verklaren waarnaar het kijkt, wat de weg vrijmaakt naar slimmer en efficiënter katalysatorontwerp.
Atomen zien met een elektronenmicroscoop
Moderne scanning transmission elektronenmicroscopen (STEM) kunnen individuele atomen in beeld brengen en tonen hoe metaal-nanoclusters op een dragervlak liggen. In principe zou dit onderzoekers in staat moeten stellen af te lezen hoeveel atomen elk cluster bevat. In de praktijk is die taak veel moeilijker. De helderheid en vorm van een cluster in een beeld hangen niet alleen af van de grootte, maar ook van de oriëntatie, de manier waarop de bundel erdoorheen gaat, en van ruis en subtiele contrastveranderingen in het instrument. Traditionele analysemethoden vertrouwen op het meten van de schijnbare diameter van elke deeltje en veronderstellen dat groter betekent meer atomen. Maar voor platina-clusters met enkele tientallen tot ongeveer zeventig atomen overlappen de groottedistributies sterk, zodat clusters met verschillende aantallen atomen er bij eenvoudige diametermeting bijna hetzelfde uit kunnen zien, waardoor die aanpak onbetrouwbaar is.
Een vertrouwde beeldbibliotheek opbouwen
Om dit aan te pakken bouwden de auteurs eerst een uitzonderlijk schone en betrouwbare dataset. Ze gebruikten een gespecialiseerd ionenbundelsysteem om platina-clusters te bereiden waarvan het aantal atomen precies was geselecteerd: 19, 30, 41, 55 of 70 atomen. Deze "grootte-geselecteerde" clusters werden vervolgens voorzichtig op elektronenmicroscoop-roosters neergezet met zeer lage energie, zodat ze vastplakten zonder uiteen te vallen of zich te herschikken. Deze zorgvuldige preparatie leverde STEM-beelden van hoge kwaliteit op waarbij het aantal atomen per cluster van tevoren bekend was. Zo’n dataset, vrij van veel gebruikelijke ambiguïteiten, bood een ideaal trainingsveld voor een deep learning-systeem dat de subtiele visuele aanwijzingen koppelde aan atomaire aantallen in plaats van slechts aan grove grootte.
Een neuraal netwerk leren atomen te tellen
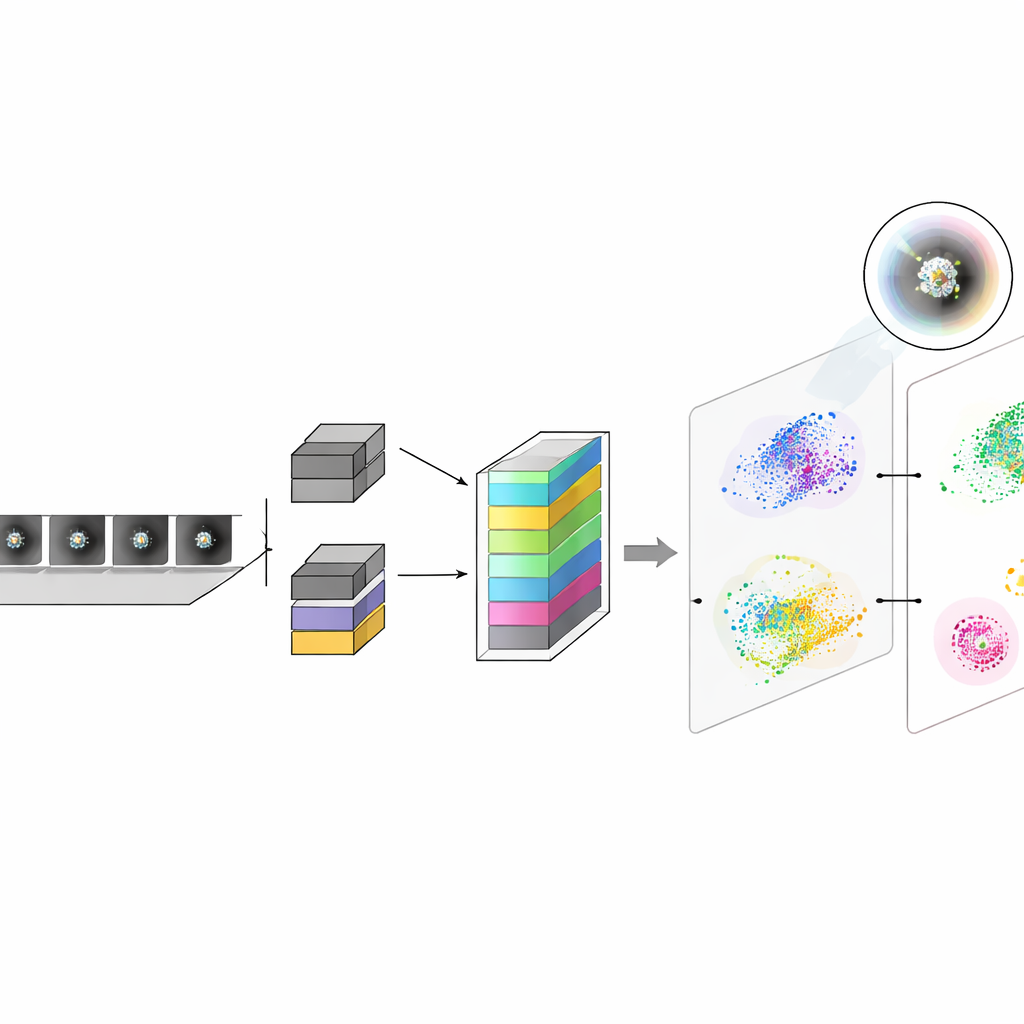
Het team ontwierp een compact convolutioneel neuraal netwerk, een type deep learning-model dat uitblinkt in het herkennen van patronen in beelden. Elk platina-cluster werd bijgesneden tot een klein beeldfragment en aan het netwerk aangeboden, dat leerde het toe te wijzen aan een van de vijf bekende atoomaantallen. Twee versies van het model werden vergeleken. De ene gebruikte de ruwe STEM-beelden als enkel inputkanaal. De andere voegde een tweede kanaal toe dat dezelfde beelden door een lokale contrastnormalisatiefilter liet lopen, waardoor randen en lokale variaties werden benadrukt. Ondanks de overlappende diameters van de clusters onderscheidden beide modellen de vijf atomaire aantallen veel beter dan diameter alleen, en de dual-channel versie behaalde een determinatiecoëfficiënt dicht bij 0,94 bij het schatten van de algehele klasseverhoudingen, wat betekent dat de voorspellingen vrijwel overeenkwamen met onafhankelijke fysieke metingen van hoeveel clusters van elke grootte zijn afgezet.
De redenering van de machine zichtbaar maken
Naast ruwe nauwkeurigheid wilden de auteurs begrijpen waar het model daadwerkelijk op lette. Ze gebruikten een visualisatiemethode die beeldregio’s markeert die het meest verantwoordelijk zijn voor elke beslissing, en produceerden zo warmtekaarten over de clusters. Deze kaarten toonden dat het netwerk verschillend focust op centrale en randregio’s afhankelijk van de clustergrootte, en dat het ruwe kanaal en het contrast-genormaliseerde kanaal elkaar aanvullen. Voor kleinere clusters werden beslissingen vooral geleid door het felle centrum in de ruwe beelden, terwijl het gefilterde kanaal de aandacht naar de buitencontour verplaatste. Voor de grootste clusters keerde dit evenwicht om. Ze projecteerden ook de interne numerieke beschrijvingen van elk deeltje van het model in twee dimensies, waarbij onderscheidbare, kleurgecodeerde eilanden verschenen die overeenkwamen met verschillende atoomaantallen. Na een korte fijn-afstemmingsstap op nieuwe beelden onder andere microscoopcondities werden deze eilanden schoner en beter gescheiden, hetgeen de herstelde classificatieprestaties weerspiegelde.
Aanpassen aan veranderende beeldomstandigheden
In echte experimenten heersen zelden perfect stabiele condities: achtergrondtexturen, ruis en scherpte kunnen van de ene sessie naar de andere verschuiven. De auteurs toonden aan dat zulke verschuivingen een model dat onder één set condities is getraind kunnen verwarren, waardoor het de verkeerde klasse ging bevoordelen. Om dit te verhelpen zonder uitputtend opnieuw te trainen, introduceerden ze een lichte aanpassingsstap. Een kleine subset van clusters waarvan de diameters in duidelijk gescheiden bereiken vallen—waarbij het waarschijnlijke atoomaantal met hoge zekerheid bekend is—wordt gebruikt om het model zachtjes bij te werken voor elk nieuw beeld. Deze fijn-afstemming, die in seconden kan verlopen, trekt de feature-clusters in de interne ruimte van het model weer in lijn en herstelt accurate voorspellingen, zelfs voor gemengde monsters waar meerdere clustergroottes tegelijk op hetzelfde rooster aanwezig zijn.
Wat dit betekent voor toekomstige katalysatoren
Voor niet-specialisten is de kernboodschap dat de auteurs ruwe atoomresolutiebeelden hebben omgezet in een betrouwbare, verklaarbare tool om atomen in individuele platina-clusters te tellen, zelfs wanneer eenvoudige grometingen tekortschieten. Door precieze monsterpreparatie te combineren met interpreteerbare deep learning laten ze zien dat machines automatisch structurele details kunnen extraheren en visualiseren die van belang zijn voor katalytische prestaties. Deze capaciteit kan direct in microscopen worden ingebouwd, waardoor realtime feedback tijdens experimenten mogelijk wordt en het ontwerp van katalysatoren die kostbaar platina spaarzamer en effectiever gebruiken, wordt gestuurd. Dezelfde strategie zou moeten toepasbaar zijn op andere metalen en legeringen, en materialenwetenschappers helpen de koppeling tussen nanoschaalstructuur en functie meer datagedreven en hulpbron-efficiënt te maken.
Bronvermelding: Tsukamoto, K., Hirata, N., Tona, M. et al. Interpretable deep learning for atomicity classification of platinum nanoclusters in STEM images. npj Comput Mater 12, 143 (2026). https://doi.org/10.1038/s41524-026-02014-z
Trefwoorden: platina-nanoclusters, elektronenmicroscopie, deep learning, katalysatorontwerp, materialen-informatica