Clear Sky Science · de
Interpretierbares Deep Learning zur Klassifizierung der Atomzahl von Platin-Nanoclustern in STEM-Bildern
Warum winzige Metallcluster wichtig sind
Platin ist ein Arbeitspferd in Technologien der sauberen Energie, von Brennstoffzellen bis zu Elektrolyseuren, doch es ist selten und teuer. Auf den kleinsten Skalen kann das Hinzufügen oder Entfernen nur eines einzigen Atoms in einem Platin-Cluster die Fähigkeit, chemische Reaktionen zu katalysieren, drastisch verändern. Um jedes Atom sinnvoll zu nutzen, benötigen Wissenschaftler eine verlässliche Methode, um direkt aus Mikroskopbildern abzuzählen, wie viele Atome in jedem nanoskaligen Klumpen sitzen. Diese Arbeit zeigt, wie eine sorgfältig gestaltete Form künstlicher Intelligenz lernen kann, diese Zählung aus Elektronenmikroskopbildern vorzunehmen und dabei zu erklären, worauf sie achtet — ein Schritt hin zu intelligenterem, effizienterem Katalysatordesign.
Atome mit einem Elektronenmikroskop sehen
Moderne abtastende Transmissions-Elektronenmikroskope (STEM) können einzelne Atome abbilden und zeigen, wie Metallnanocluster auf einer Trägeroberfläche sitzen. Grundsätzlich sollte das Forschern ermöglichen, abzulesen, wie viele Atome in jedem Cluster sind. In der Praxis ist die Aufgabe jedoch deutlich schwieriger. Helligkeit und Form eines Clusters im Bild hängen nicht nur von seiner Größe ab, sondern auch von seiner Orientierung, davon, wie der Strahl hindurchgeht, sowie von Rauschen und subtilen Kontraständerungen im Instrument. Traditionelle Analysemethoden messen den scheinbaren Durchmesser jedes Partikels und gehen davon aus, dass größer mehr Atome bedeutet. Für Platincluster mit einigen Dutzend bis etwa siebzig Atomen überlappen die Größendistributionen jedoch stark, sodass Cluster mit unterschiedlicher Atomzahl allein anhand des Durchmessers sehr ähnlich aussehen können — ein Ansatz, der sich damit als unzuverlässig erweist.
Aufbau einer vertrauenswürdigen Bildbibliothek
Um dieses Problem anzugehen, bauten die Autorinnen und Autoren zunächst einen ungewöhnlich sauberen und verlässlichen Datensatz auf. Sie nutzten ein spezialisiertes Ionenstrahlsystem, um Platincluster mit präzise ausgewählten Atomzahlen zu erzeugen: 19, 30, 41, 55 oder 70 Atome. Diese „größenselektierten" Cluster wurden dann bei sehr niedriger Energie schonend auf Elektronenmikroskopgitter aufgebracht, sodass sie haften blieben, ohne auseinanderzufallen oder sich neu anzuordnen. Diese sorgfältige Probenvorbereitung erzeugte hochtreue STEM-Bilder, bei denen die Atomzahl jedes Clusters im Voraus bekannt war. Ein solcher Datensatz, frei von vielen üblichen Unklarheiten, bot eine ideale Trainingsbasis für ein Deep-Learning-System, das die feinen visuellen Hinweise zur Atomzahl erlernen konnte statt nur grobe Größenmerkmale.
Ein neuronales Netzwerk darin schulen, Atome zu zählen
Das Team entwarf ein kompaktes Convolutional Neural Network, eine Form des Deep Learning, die besonders gut Muster in Bildern erkennt. Jeder Platincluster wurde in einen kleinen Bildausschnitt zugeschnitten und dem Netzwerk zugeführt, das lernte, ihn einer der fünf bekannten Atomzahlen zuzuordnen. Zwei Modellvarianten wurden verglichen. Eine nutzte die rohen STEM-Bilder als einzigen Eingabekanal. Die andere fügte einen zweiten Kanal hinzu, der dieselben Bilder durch eine lokale Kontrastnormalisierung schickte und so Kanten und lokale Variationen betonte. Trotz der sich überschneidenden Durchmesser unterschieden beide Modelle die fünf Atomzahlen deutlich besser als die reine Größenmessung, und die Zwei-Kanal-Version erreichte bei der Schätzung der Gesamtklassenverhältnisse einen Bestimmtheitskoeffizienten nahe 0,94 — ihre Vorhersagen stimmten also fast mit unabhängigen physikalischen Messungen überein, wie viele Cluster jeder Größe abgeschieden wurden.
Die Entscheidungsfindung der Maschine sichtbar machen
Über die reine Genauigkeit hinaus wollten die Autorinnen und Autoren verstehen, worauf das Modell tatsächlich achtet. Sie nutzten eine Visualisierungsmethode, die Bildbereiche hervorhebt, die für jede Entscheidung am wichtigsten sind, und erzeugten so Heatmaps über den Clustern. Diese Karten zeigten, dass das Netzwerk je nach Clustergröße unterschiedlich auf zentrale und Randbereiche fokussiert und dass die Roh- und der kontrast-normalisierte Kanal sich ergänzen. Bei kleineren Clustern leiteten die Rohbilder Entscheidungen hauptsächlich über das helle Zentrum, während der gefilterte Kanal die Aufmerksamkeit eher auf die äußere Kontur verteilte. Bei den größten Clustern kehrte sich dieses Verhältnis um. Außerdem projizierten sie die internen numerischen Beschreibungen jedes Partikels des Modells in zwei Dimensionen und zeigten dabei klar getrennte, farbcodierte Inseln, die den unterschiedlichen Atomzahlen entsprechen. Nach einem kurzen Fine-Tuning an neuen Bildern unter veränderten Mikroskopbedingungen wurden diese Inseln sauberer und stärker separiert, was sich in der wiederhergestellten Klassifikationsleistung widerspiegelte.
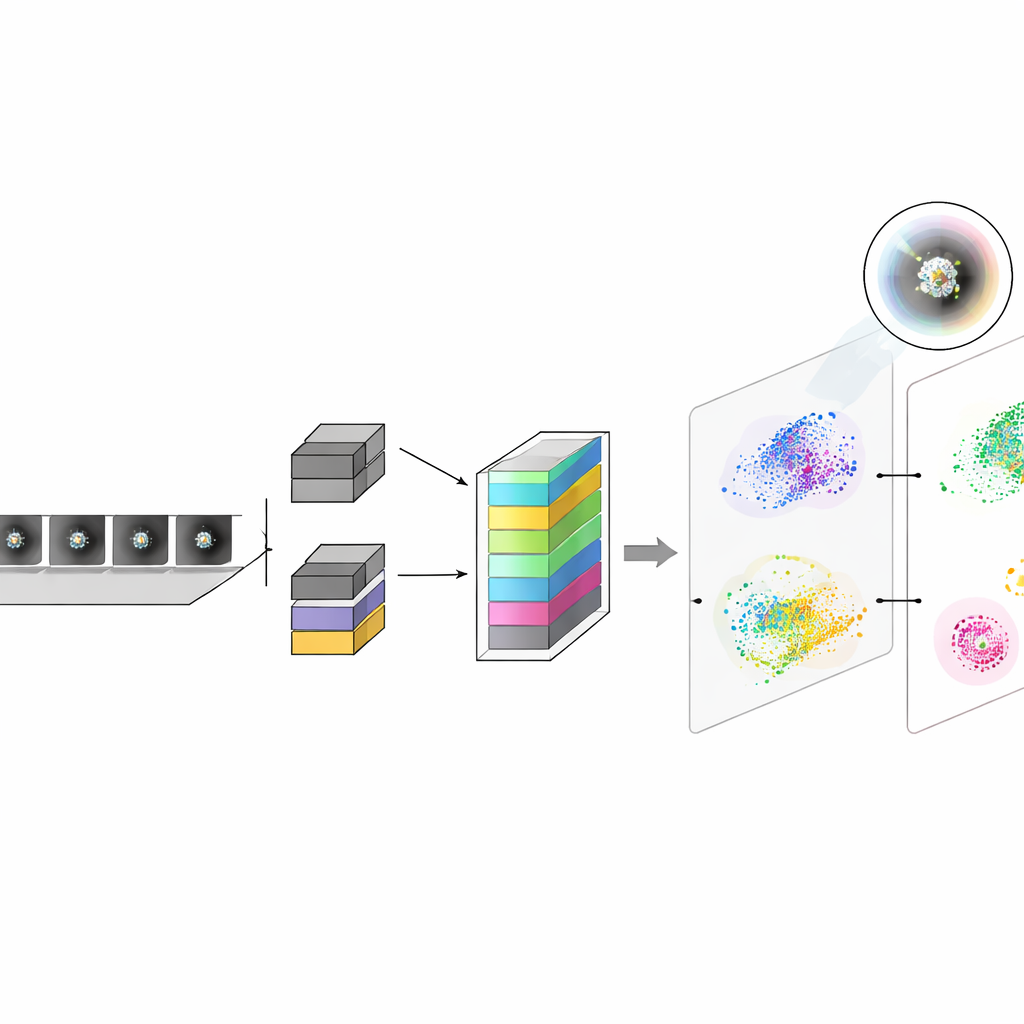
Anpassung an wechselnde Bildgebungsbedingungen
Reale Experimente laufen selten unter perfekt stabilen Bedingungen ab: Hintergrundstrukturen, Rauschen und Fokus können von Sitzung zu Sitzung driftieren. Die Autorinnen und Autoren zeigten, dass solche Verschiebungen ein unter einer Bedingung trainiertes Modell verwirren und dazu führen können, dass es eine falsche Klasse bevorzugt. Um dies ohne umfassendes Retraining zu beheben, führten sie einen schonenden Anpassungsschritt ein. Eine kleine Teilmenge von Clustern, deren Durchmesser in klar getrennten Bereichen liegen — wo die wahrscheinliche Atomzahl mit hoher Sicherheit bekannt ist — dient dazu, das Modell für jede neue Aufnahme sanft zu aktualisieren. Dieses Fine-Tuning, das in Sekunden ablaufen kann, zieht die Feature-Cluster im internen Raum des Modells wieder in Übereinstimmung und stellt genaue Vorhersagen wieder her, auch für gemischte Proben, auf denen mehrere Clustergrößen koexistieren.
Was das für zukünftige Katalysatoren bedeutet
Für Nicht-Spezialisten ist das wichtigste Ergebnis, dass die Autorinnen und Autoren atomauflösende Rohbilder in ein verlässliches, erklärbares Werkzeug verwandelt haben, mit dem sich die Atomzahl einzelner Platincluster bestimmen lässt — selbst dort, wo einfache Größenmessungen versagen. Durch die Kombination präziser Probenvorbereitung mit interpretierbarem Deep Learning zeigen sie, dass Maschinen strukturelle Details automatisch extrahieren und visualisieren können, die für die katalytische Leistung relevant sind. Diese Fähigkeit könnte direkt in Mikroskope integriert werden, um während Experimenten Echtzeit-Feedback zu liefern und das Design von Katalysatoren zu leiten, die kostbares Platin sparsamer und effizienter einsetzen. Dieselbe Strategie sollte sich auf andere Metalle und Legierungen übertragen lassen und Materialwissenschaftlern helfen, nanoskalige Struktur und Funktion datengetriebener und ressourceneffizienter zu verknüpfen.
Zitation: Tsukamoto, K., Hirata, N., Tona, M. et al. Interpretable deep learning for atomicity classification of platinum nanoclusters in STEM images. npj Comput Mater 12, 143 (2026). https://doi.org/10.1038/s41524-026-02014-z
Schlüsselwörter: Platin-Nanocluster, Elektronenmikroskopie, Deep Learning, Katalysatordesign, Materialinformatik