Clear Sky Science · it
Impatto delle previsioni di carico accurate sulla stabilità del mercato elettrico in Giappone usando metodi classici di serie temporali e di deep learning
Perché la bolletta di domani inizia con la previsione di oggi
Ogni ora, le compagnie elettriche giapponesi cercano di prevedere quanta elettricità verrà consumata il giorno successivo. Se stimano troppo, si spreca denaro per energia non necessaria. Se stimano troppo poco, le forniture scarseggiano e i prezzi possono impennarsi. Questo studio analizza come diversi metodi di «previsione» — dalla statistica tradizionale al moderno deep learning — si comportano nelle nove regioni molto diverse del Giappone, e quanto denaro e stabilità si possono guadagnare quando queste previsioni diventano più accurate.
Un sistema elettrico a macchia di leopardo con bisogni molto diversi
Il sistema elettrico giapponese è singolare. È diviso in nove mercati regionali che non condividono liberamente l’energia e funzionano persino a due frequenze differenti, 50 e 60 Hz. Aree settentrionali come Hokkaido e Tohoku presentano forti picchi invernali per il riscaldamento, mentre regioni meridionali come Kyushu registrano impennate estive quando accendono i condizionatori. Centri industriali, città dense e zone rurali consumano energia con ritmi propri. Poiché ogni regione determina i propri prezzi, una previsione unica per tutti può non cogliere questi ritmi locali, generando sia tensioni tecniche sia rischi finanziari.
Tre modi diversi per prevedere il futuro
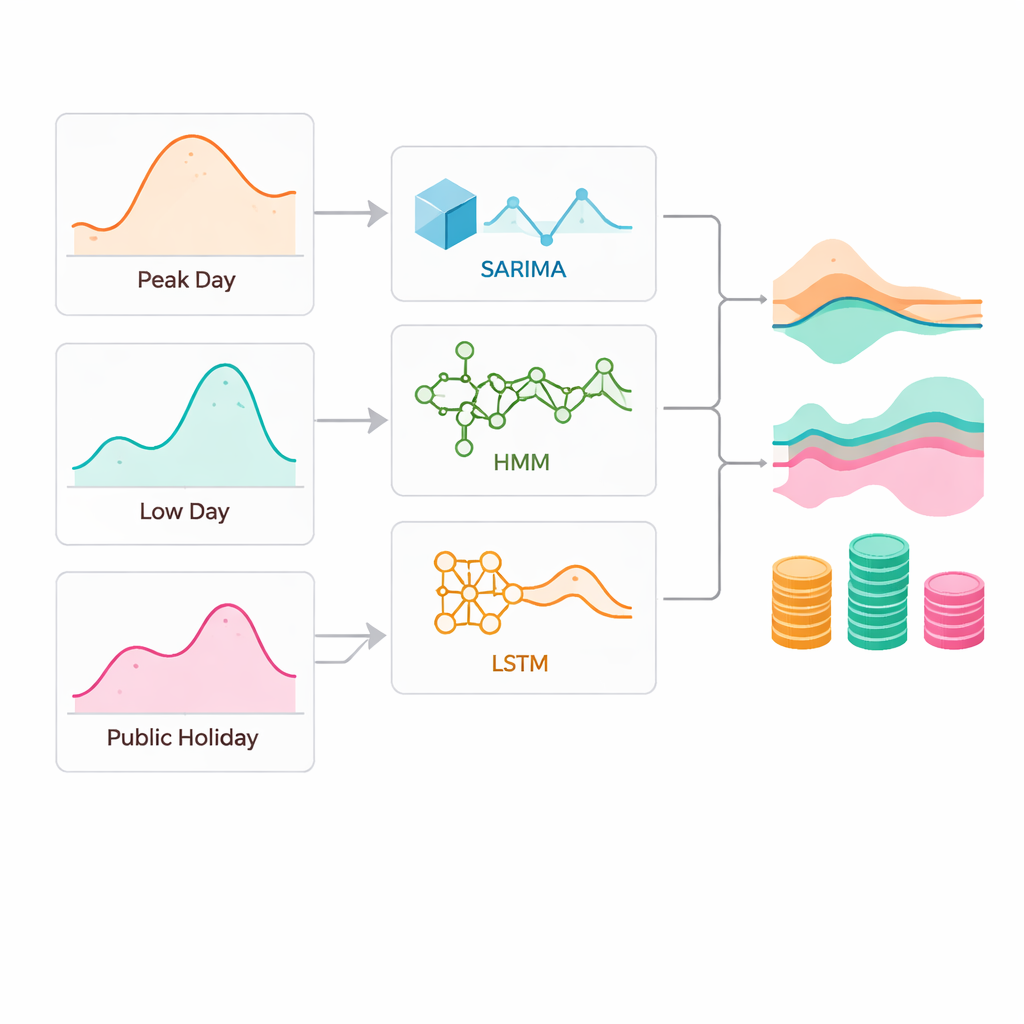
I ricercatori hanno confrontato tre famiglie di strumenti di previsione usando dati orari dal 2019 al 2022 per tutte e nove le regioni. Un modello statistico classico (chiamato SARIMA) ricerca schemi giornalieri e stagionali ripetuti e li estende nel futuro. Un modello probabilistico (un modello di Markov nascosto) tratta la domanda come un passaggio tra «stati» nascosti, come giorni lavorativi o festivi, e stima la probabilità di ciascuno. Una rete di deep learning (LSTM) apprende relazioni complesse e non lineari da grandi volumi di dati storici, catturando la memoria a lungo termine dell’evoluzione della domanda. A tutti e tre è stato chiesto di prevedere la domanda con un’ora di anticipo e con un giorno di anticipo, in condizioni normali e sotto stress: il giorno di massima domanda, il giorno di minima domanda e una grande festività nazionale.
Regioni diverse, vincitori diversi
I risultati mostrano che non esiste un vincitore universale. Nelle regioni urbane affollate con domanda altamente variabile, il modello di deep learning in genere ha dato i risultati migliori, specialmente nei giorni di picco stressanti. Ad esempio, nel giorno di massima domanda di Tokyo l’LSTM ha superato nettamente il modello classico SARIMA. Tuttavia, nelle regioni industriali più stabili con andamenti più regolari, il più semplice SARIMA spesso ha eguagliato o battuto il deep learning, in particolare nelle giornate tranquille di bassa domanda dove dominano i cicli abituali. Il modello probabilistico basato sugli stati ha raramente vinto in condizioni normali, ma ha dimostrato il suo valore nei giorni insoliti. In una festività pubblica in Tohoku, quando le routine si sono discostate nettamente dalla norma dei giorni feriali, il modello di Markov nascosto è risultato il più accurato.
Dagli errori di previsione al denaro reale
Per collegare le statistiche alle conseguenze quotidiane, il team ha tradotto gli errori di previsione in termini finanziari usando i prezzi reali dei mercati regionali. Anche differenze minime in accuratezza si sono sommate. Nella regione di Chugoku, un margine di accuratezza di appena 0,08 punti percentuali ha significato evitare circa 5,4 milioni di yen di costi extra in un singolo giorno di picco. A Tokyo, un divario di errore maggiore in un giorno di alta domanda si è tradotto in un onere finanziario aggiuntivo di circa 642 milioni di yen. In Tohoku, scegliere il modello sbagliato in una festività pubblica avrebbe potuto costare più di 100 milioni di yen. Lo studio ha inoltre quantificato le bande di incertezza attorno alle previsioni, mostrando che il deep learning tendeva a produrre gli intervalli più stretti e affidabili, mentre il modello probabilistico presentava il rischio più ampio in molte regioni.
Scelte più intelligenti per una rete più stabile
Per il lettore non specialista, il messaggio chiave è semplice: previsioni meglio calibrate rendono il sistema elettrico più economico e più sicuro da gestire. Le regioni del Giappone si comportano in modo troppo diverso perché un solo metodo sia il migliore ovunque e sempre. Il deep learning brilla dove la domanda è complessa e cambia rapidamente; la statistica classica funziona bene dove i pattern sono regolari; i modelli basati sugli stati aiutano quando i comportamenti cambiano all’improvviso, come durante le festività. Scegliendo lo strumento giusto per ogni luogo e situazione, le utility possono ridurre i costi di decine fino a centinaia di milioni di yen al giorno, limitare i picchi di prezzo e gestire la rete con maggiore sicurezza mentre il Giappone si dirige verso un sistema energetico più flessibile e a basse emissioni di carbonio.
Citazione: Rabie, D., Moradi, M., Xuan, W. et al. Impact of accurate load forecasting on electricity market stability in Japan using classical time-series and deep-learning methods. Sci Rep 16, 11781 (2026). https://doi.org/10.1038/s41598-026-46859-2
Parole chiave: previsione della domanda elettrica, mercato dell’energia in Giappone, deep learning energia, modellizzazione delle serie temporali, rischio del mercato energetico