Clear Sky Science · de
Auswirkungen genauer Lastprognosen auf die Stabilität des Elektrizitätsmarkts in Japan mit klassischen Zeitreihen- und Deep‑Learning-Methoden
Warum die Stromrechnung von morgen mit der Schätzung von heute beginnt
Stündlich versuchen Japans Energieversorger vorherzusagen, wie viel Strom am nächsten Tag verbraucht wird. Liegt die Schätzung zu hoch, wird Geld für unnötige Erzeugung verschwendet. Liegt sie zu niedrig, drohen Versorgungsengpässe und Preisexplosionen. Diese Studie untersucht, wie verschiedene „Schätzverfahren“ – von traditionellen statistischen Modellen bis zu modernen Deep‑Learning‑Ansätzen – in Japans neun sehr unterschiedlichen Regionen abschneiden und welche finanziellen und stabilitätsbezogenen Gewinne durch genauere Vorhersagen möglich sind.
Ein Flickenteppich von Energiesystemen mit sehr unterschiedlichen Bedürfnissen
Das japanische Stromsystem ist ungewöhnlich. Es ist in neun regionale Märkte aufgeteilt, die nicht frei Strom untereinander austauschen, und arbeitet sogar mit zwei unterschiedlichen Frequenzen, 50 und 60 Hz. Nördliche Gebiete wie Hokkaido und Tohoku erleben starke Winterheizspitzen, während in südlichen Regionen wie Kyushu im Sommer die Klimaanlagen den Verbrauch in die Höhe treiben. Industrielle Zentren, dicht besiedelte Städte und ländliche Gebiete weisen jeweils eigene Verbrauchsmuster auf. Da jede Region ihre Preise separat ermittelt, kann eine einheitliche Prognose diese lokalen Rhythmen verfehlen und sowohl technische Belastungen als auch finanzielle Risiken erzeugen.
Drei verschiedene Blickwinkel auf die Zukunft
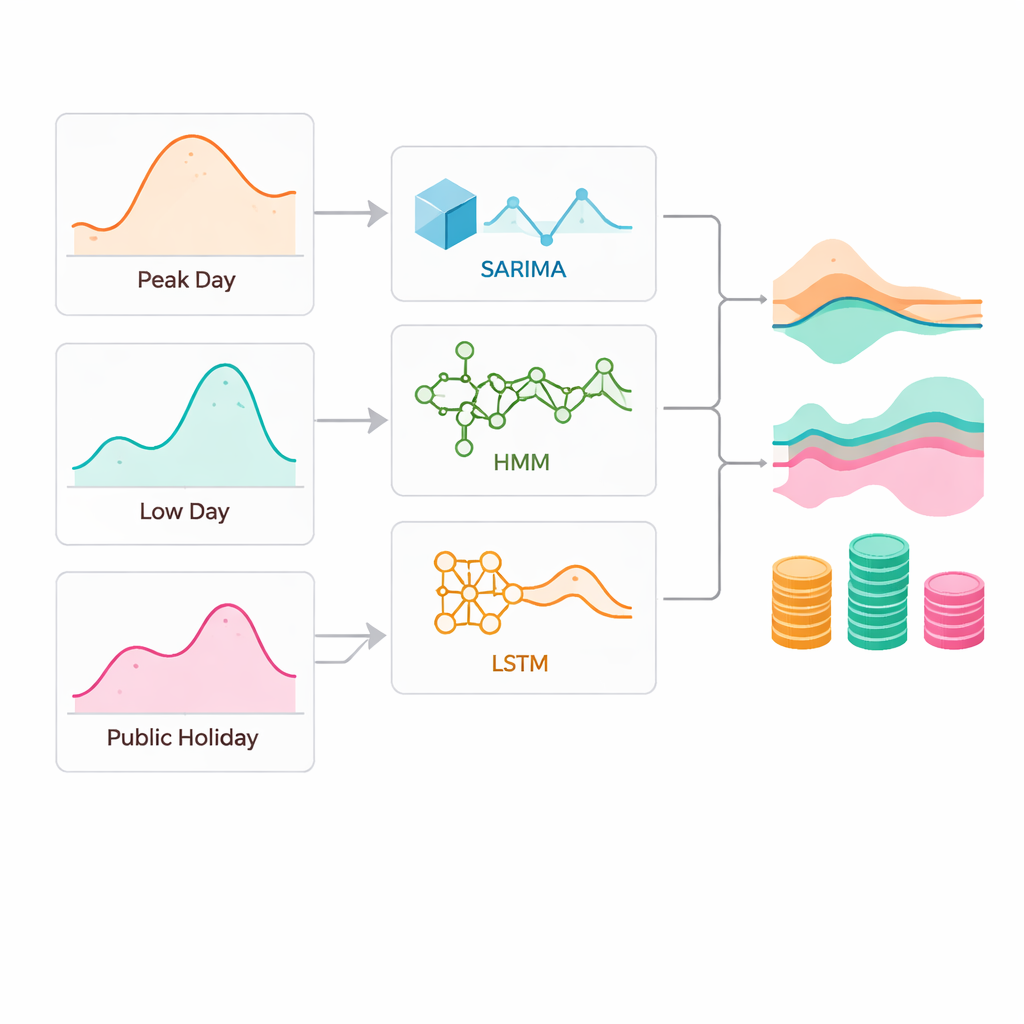
Die Forschenden verglichen drei Familien von Prognosewerkzeugen anhand stündlicher Daten von 2019 bis 2022 für alle neun Regionen. Ein klassisches statistisches Modell (SARIMA) sucht nach wiederkehrenden Tages‑ und Jahressaisonalitäten und projiziert diese in die Zukunft. Ein probabilistisches Modell (Hidden‑Markov‑Modell) behandelt die Nachfrage als Wechsel zwischen verborgenen „Zuständen“, etwa Arbeitstagen oder Feiertagen, und schätzt die Wahrscheinlichkeiten für diese Zustände. Ein Deep‑Learning‑Netzwerk (LSTM) lernt komplexe, nichtlineare Zusammenhänge aus großen Mengen historischer Daten und erfasst Langzeitgedächtnis in der Nachfrageentwicklung. Alle drei Modelle sollten eine Stunde und einen Tag im Voraus prognostizieren, sowohl unter normalen Bedingungen als auch unter Belastung: am Tag mit der höchsten Nachfrage, am Tag mit der niedrigsten Nachfrage und an einem großen Feiertag.
Unterschiedliche Regionen, unterschiedliche Gewinner
Die Ergebnisse zeigen, dass es keinen universellen Sieger gibt. In stark frequentierten urbanen Regionen mit sehr variabler Nachfrage schnitt das Deep‑Learning‑Modell meist am besten ab, insbesondere an stressreichen Spitzentagen. So übertraf das LSTM etwa am Tag der höchsten Nachfrage in Tokio deutlich das klassische SARIMA‑Modell. In stabileren Industriegebieten mit gleichmäßigeren Mustern konnte das einfachere SARIMA‑Modell jedoch oft mithalten oder das Deep Learning übertreffen, vor allem an ruhigen Tagen mit geringer Nachfrage, wenn reguläre Zyklen dominieren. Das zustandsbasierte probabilistische Modell gewann selten unter normalen Bedingungen, spielte aber an ungewöhnlichen Tagen seine Stärken aus. An einem Feiertag in Tohoku, als sich die Tagesabläufe deutlich vom Wochentagsmuster lösten, war das Hidden‑Markov‑Modell am genauesten.
Von Prognosefehlern zu echtem Geld
Um Statistik in greifbare Folgen zu übersetzen, rechnete das Team Prognosefehler in finanzielle Größen um, unter Verwendung tatsächlicher regionaler Marktpreise. Selbst kleinste Genauigkeitsunterschiede summierten sich. In der Chugoku‑Region bedeutete ein Vorsprung von nur 0,08 Prozentpunkten in der Genauigkeit, an einem einzigen Spitzentag rund 5,4 Millionen Yen an Zusatzkosten zu vermeiden. In Tokio entsprach eine größere Fehlerschere an einem Tag hoher Nachfrage einer zusätzlichen finanziellen Belastung von etwa 642 Millionen Yen. In Tohoku hätte die Wahl des falschen Modells an einem Feiertag mehr als 100 Millionen Yen gekostet. Die Studie quantifizierte außerdem Unsicherheitsbereiche der Vorhersagen: Deep Learning tendierte dazu, die engsten und zuverlässigsten Bereiche zu liefern, während das probabilistische Modell in vielen Regionen die breitesten Risiken aufwies.
Klügere Entscheidungen für ein stabileres Netz
Die Kernbotschaft ist für Laien klar: Besser zugeschnittene Prognosen machen das Stromsystem günstiger und sicherer im Betrieb. Japans Regionen verhalten sich zu unterschiedlich, als dass eine einzelne Methode überall und jederzeit die beste wäre. Deep Learning glänzt dort, wo die Nachfrage komplex und schnell veränderlich ist; klassische Statistik funktioniert gut, wo die Muster regelmäßig sind; zustandsbasierte Modelle sind nützlich, wenn sich das Verhalten plötzlich ändert, etwa an Feiertagen. Durch die Wahl des jeweils passenden Werkzeugs für Ort und Situation können Versorger Kosten um Zehnerbis Hunderte Millionen Yen pro Tag senken, Preisspitzen reduzieren und das Netz mit größerer Zuversicht betreiben, während Japan auf ein flexibleres und kohlenstoffärmeres Energiesystem zusteuert.
Zitation: Rabie, D., Moradi, M., Xuan, W. et al. Impact of accurate load forecasting on electricity market stability in Japan using classical time-series and deep-learning methods. Sci Rep 16, 11781 (2026). https://doi.org/10.1038/s41598-026-46859-2
Schlüsselwörter: Strombedarfsvorhersage, japanischer Energiemarkt, Deep Learning Energie, Zeitreihenmodellierung, Risiko auf Energiemärkten