Clear Sky Science · it
Predizione dei guasti delle porte della metropolitana mediante apprendimento ensemble a stacking
Perché le porte della metropolitana contano per il tuo viaggio quotidiano
Chiunque sia rimasto bloccato su una banchina perché la porta di un treno non si chiudeva sa quanto possa essere fragile la regolarità del servizio metropolitano. I malfunzionamenti delle porte possono sembrare piccoli, ma si possono propagare in lunghi ritardi, problemi di sicurezza e stazioni affollate. Questo studio pone una domanda semplice e pratica: possiamo usare strumenti dati intelligenti per individuare i problemi delle porte della metropolitana prima che si guastino, così che le squadre di manutenzione possano intervenire in tempo e mantenere i treni affidabili?
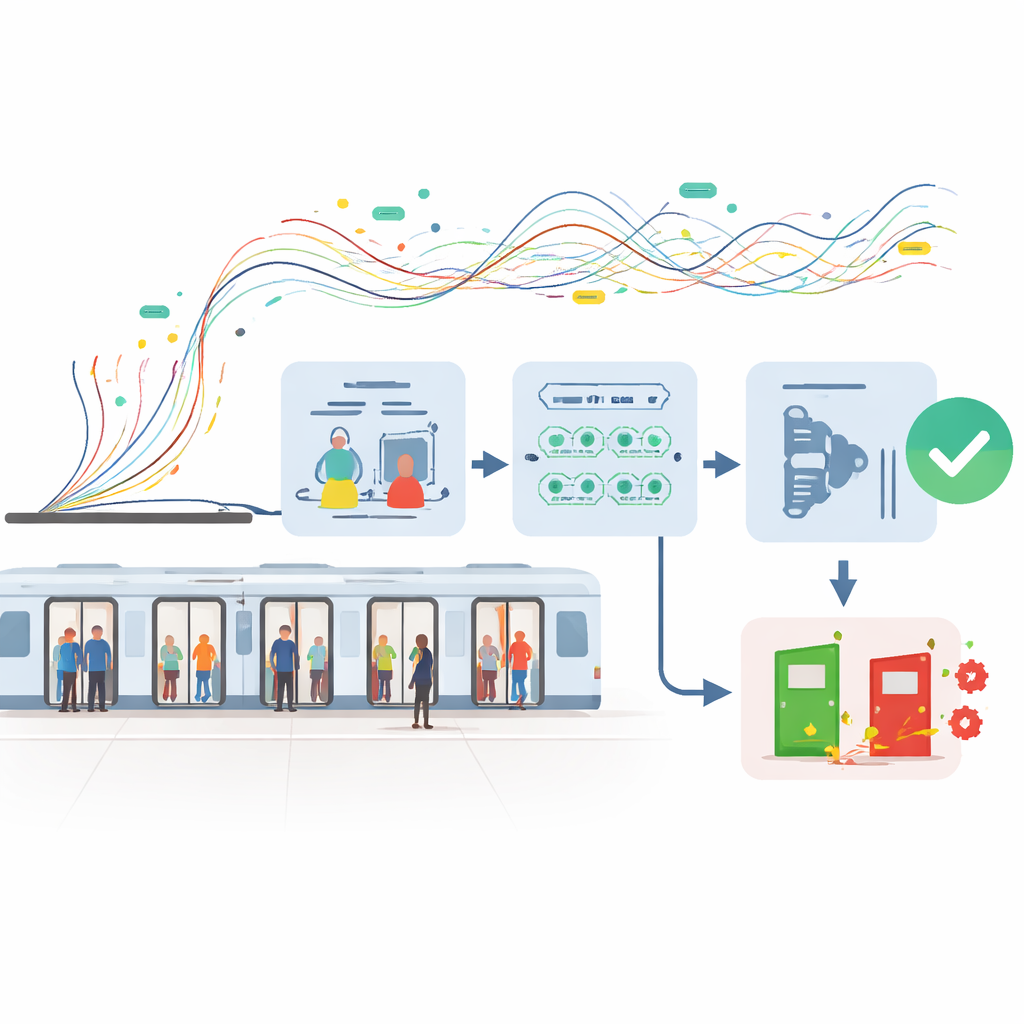
La sfida dei guasti rari ma importanti
I guasti alle porte della metropolitana sono eventi relativamente rari se confrontati con l’enorme numero di cicli di apertura e chiusura normali che avvengono ogni giorno. Nel dataset studiato qui, le operazioni di porte sane superavano i guasti di oltre sette a uno. Quel disequilibrio crea un punto cieco per molti metodi convenzionali di intelligenza artificiale, che tendono a concentrarsi sui pattern comuni e a trascurare quelli insoliti. Inoltre, il sistema delle porte è un apparato fortemente accoppiato: correnti del motore, angoli di rotazione e tempistiche sono legati da vincoli fisici rigidi. Qualsiasi metodo predittivo utile deve rilevare minuscoli segnali di allarme precoce senza inventare comportamenti irrealistici che porte reali non potrebbero mai mostrare.
Aggiungere una «immaginazione realistica» ai dati
I ricercatori hanno innanzitutto affrontato il problema del numero insufficiente di esempi di guasto. Invece di usare trucchi standard che semplicemente copiano o mescolano campioni rari, hanno progettato uno schema di aumentazione dei dati vincolato dalla fisica. In termini semplici, generano casi di guasto sintetici aggiuntivi ma costringono ogni nuovo campione a rispettare la meccanica nota della porta: gli angoli di rotazione devono rimanere entro i limiti di progetto, i segmenti di movimento devono sommare alla corsa totale e le derive temporali devono restare entro limiti realistici. Variazioni di alcuni conteggi e misure continue di movimento vengono fatte in piccoli intervalli accuratamente controllati, e poi si filtrano rigorosamente i campioni che violerebbero le regole cinematiche della porta. Un test statistico conferma che i dati di guasto arricchiti corrispondono strettamente alla distribuzione originale dei guasti pur rimanendo fisicamente plausibili.
Lasciare che modelli diversi votino insieme
Una volta ottenuto un set di addestramento più robusto, il team ha adottato un «comitato» stratificato di algoritmi per effettuare le predizioni. Hanno prima ridotto le oltre 40 caratteristiche dei sensori a un set compatto di cinque variabili di significato fisico, come l’angolo di rotazione massimo e il tempo di decelerazione, che insieme catturano quasi tutte le informazioni utili. Due modelli diversi basati su alberi vengono poi addestrati in parallelo: una foresta casuale potenziata, sintonizzata per prestare maggiore attenzione ai casi rari di guasto ed evitare l’overfitting su dettagli rumorosi, e un modello XGBoost capace di estrarre piccoli ma costanti miglioramenti da pattern sottili. Invece di far votare questi modelli con una semplice maggioranza, uno strato di regressione logistica sta sopra e apprende come combinare le loro uscite di probabilità in una singola stima del rischio di guasto ben calibrata.
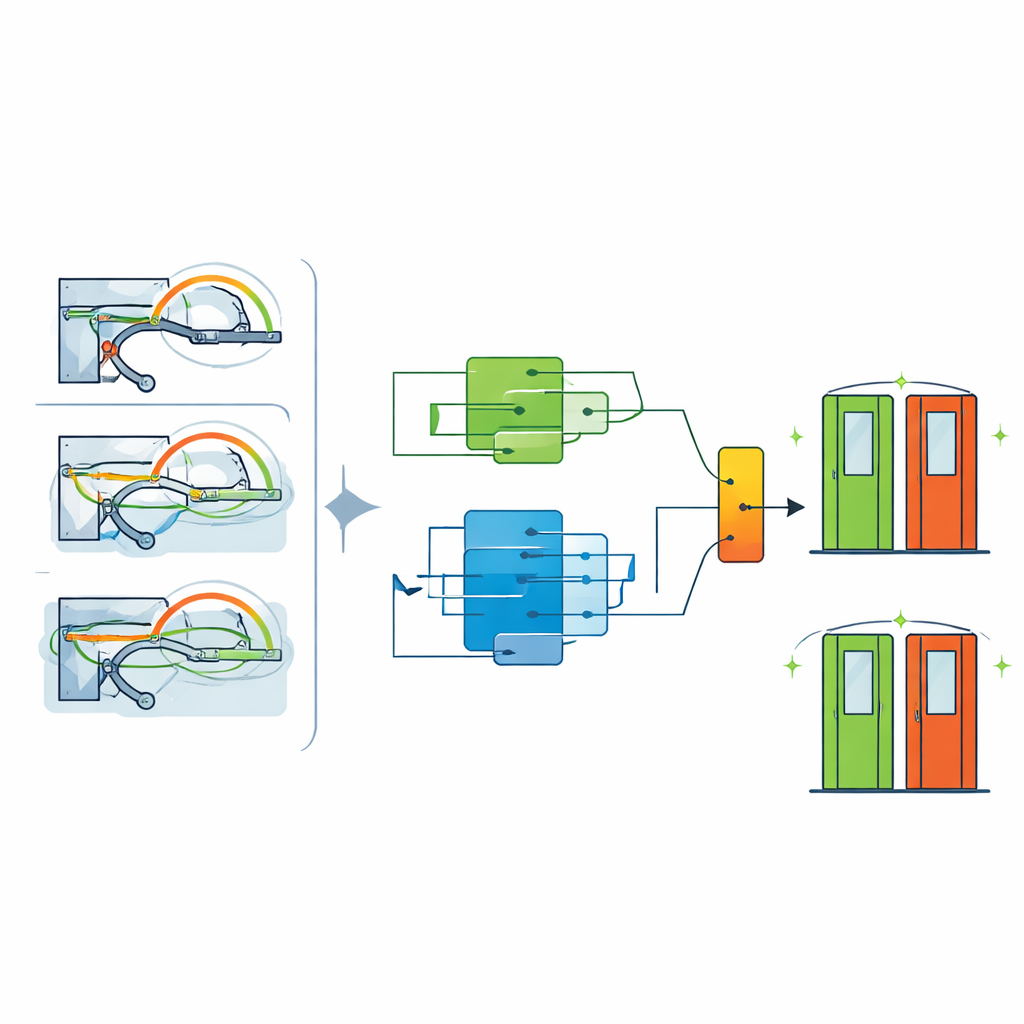
Bilanciare allarmi mancati e falsi allarmi
Nelle operazioni metropolitane reali, perdere un guasto vero può costare molto più che inviare una squadra a controllare una porta che si rivela a posto. I ricercatori quindi evitano la solita regola «maggiore di 0,5 significa guasto». Scorrono molti possibili punti di soglia sulla scala di probabilità predetta e selezionano quello che massimizza l’F1-score, una misura che bilancia quanti guasti reali vengono intercettati rispetto a quanti allarmi sono corretti. Questa impostazione ottimizzata produce un forte equilibrio di accuratezza, precisione e richiamo sui dati di test, con ottimi punteggi su misure globali pensate per problemi sbilanciati. Altrettanto importante, i valori di rischio predetti sono ben calibrati, il che significa che una certa probabilità corrisponde davvero a quanto spesso si verificano i guasti a quel livello.
Cosa significa per viaggi più sicuri e regolari
Per un non esperto, la conclusione è che questo approccio consapevole della fisica e multilivello trasforma le tracce grezze dei sensori delle porte della metropolitana in avvisi precoci affidabili su quali porte potrebbero dare problemi. Rispettando la meccanica sottostante e utilizzando al contempo ensemble moderni e soglie decisionali intelligenti, il metodo può individuare sia inceppamenti improvvisi sia usura sottile con alta confidenza, anche quando i casi reali di guasto sono scarsi. Se implementato nei sistemi reali, potrebbe aiutare gli operatori a programmare manutenzioni mirate, ridurre arresti imprevisti e rendere i viaggi quotidiani più sicuri e affidabili senza sommergere il personale di falsi allarmi.
Citazione: Song, H., Tang, S., Xia, J. et al. Subway door fault prediction employing stacking ensemble learning. Sci Rep 16, 12876 (2026). https://doi.org/10.1038/s41598-026-43371-5
Parole chiave: porte della metropolitana, manutenzione predittiva, predizione dei guasti, apprendimento ensemble, trasporto intelligente