Clear Sky Science · en
Subway door fault prediction employing stacking ensemble learning
Why subway doors matter to your daily ride
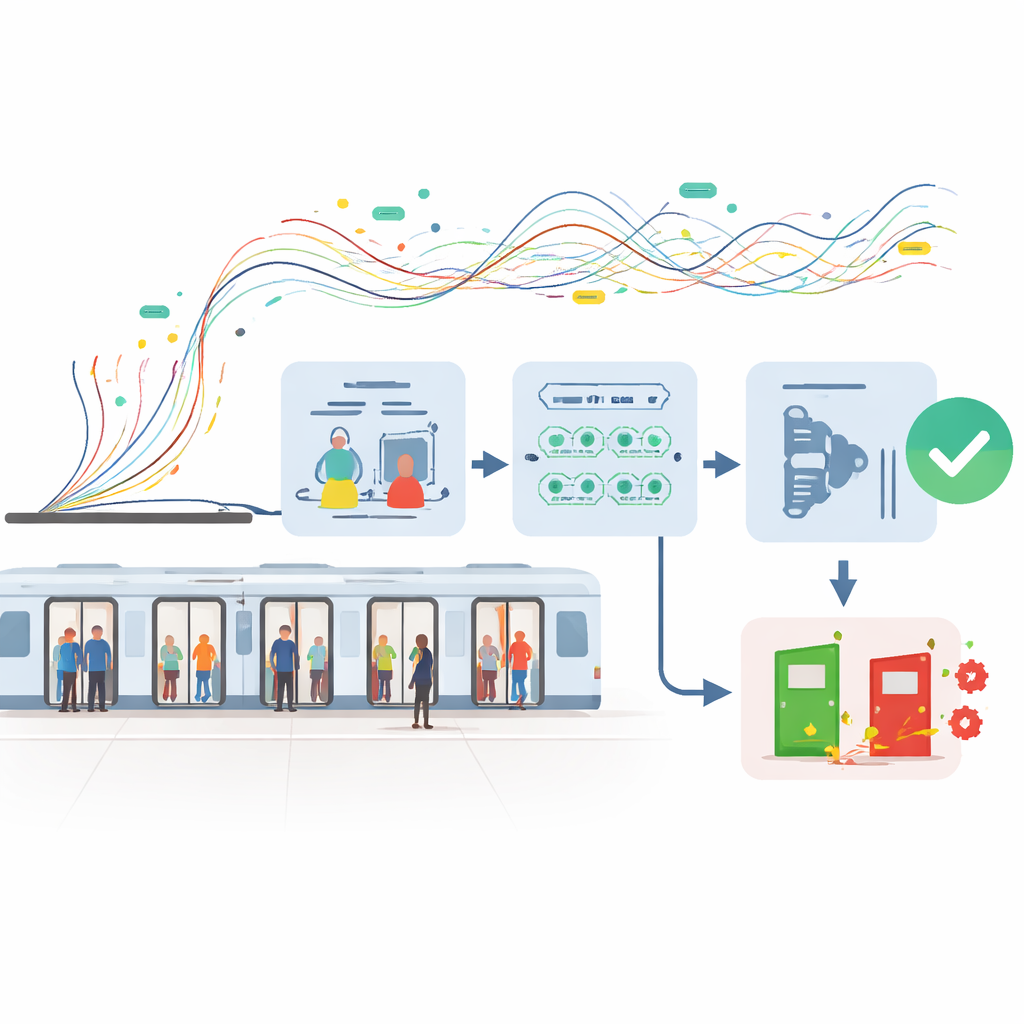
Anyone who has been stuck on a platform because a train door would not close knows how fragile smooth metro service can be. Door glitches may seem minor, but they can ripple into long delays, safety concerns, and crowded stations. This study asks a simple, practical question: can we use smart data tools to spot subway door problems before they actually fail, so that maintenance crews can fix them in time and keep trains running reliably?
The challenge of rare but important failures
Subway door breakdowns are relatively rare events compared with the huge number of normal opening and closing cycles that happen every day. In the dataset studied here, healthy door operations outnumbered faults by more than seven to one. That imbalance creates a blind spot for many conventional artificial intelligence methods, which tend to focus on the common patterns and overlook the unusual ones. On top of that, the door system is a tightly coupled piece of machinery: motor currents, rotation angles and timing are linked by hard physical limits. Any useful prediction method must detect tiny early-warning patterns without inventing unrealistic behavior that real doors could never show.
Adding “realistic imagination” to the data
The researchers first tackled the problem of having too few fault examples. Instead of using off-the-shelf tricks that simply copy or mix rare samples, they designed a physics-constrained data augmentation scheme. In plain terms, they generate additional synthetic fault cases but force every new sample to obey the known mechanics of the door: rotation angles must remain within design limits, motion segments must add up to the total stroke, and timing drifts must stay within realistic bounds. They vary certain counts and continuous motion measures by small, carefully controlled amounts, and then rigorously filter out any sample that would violate the door’s kinematic rules. A statistical test confirms that the enriched fault data closely match the original fault distribution while remaining physically plausible.
Letting different models vote together
Once they had a stronger training set, the team turned to a layered “committee” of algorithms to make predictions. They first trimmed the original 40-plus sensor features down to a compact set of five physically meaningful variables, such as maximum rotation angle and deceleration time, which together capture almost all of the useful information. Two different tree-based models are then trained in parallel: an enhanced random forest tuned to pay extra attention to the rare fault cases and to avoid overfitting on noisy details, and an XGBoost model that is good at squeezing out small but consistent gains from subtle patterns. Instead of letting these models vote by simple majority, a logistic regression layer sits on top and learns how to combine their probability outputs into a single, well-calibrated estimate of fault risk.
Balancing missed alarms and false alarms
In real metro operations, missing a true fault can be far more costly than sending a crew to check a door that turns out to be fine. The researchers therefore avoid the usual “greater than 0.5 means fault” rule. They scan through many possible cut-off points on the predicted probability scale and select the one that maximizes the F1-score, a measure that balances how many actual faults are caught against how many alarms are correct. This optimized setting yields a strong blend of accuracy, precision and recall on test data, with excellent scores on global measures that are designed for imbalanced problems. Just as important, the predicted risk values themselves are well calibrated, meaning that a given probability really does correspond to how often faults occur at that level.
What this means for safer, smoother rides
To a layperson, the bottom line is that this physics-aware, multi-layered approach turns raw sensor traces from subway doors into reliable early warnings about which doors are likely to cause trouble. By respecting the underlying mechanics while using modern ensemble learning and smart decision thresholds, the method can spot both sudden jams and subtle wear with high confidence, even when genuine fault cases are scarce. If deployed in real systems, it could help operators schedule targeted maintenance, reduce unexpected stoppages, and make daily commutes safer and more dependable without drowning staff in false alarms.
Citation: Song, H., Tang, S., Xia, J. et al. Subway door fault prediction employing stacking ensemble learning. Sci Rep 16, 12876 (2026). https://doi.org/10.1038/s41598-026-43371-5
Keywords: subway doors, predictive maintenance, fault prediction, ensemble learning, intelligent transportation