Clear Sky Science · de
Fehlervorhersage von U-Bahn-Türen mithilfe von Stacking-Ensemble-Learning
Warum U-Bahn-Türen für Ihre tägliche Fahrt wichtig sind
Wer schon einmal auf einem Bahnsteig festsaß, weil sich eine Zugtür nicht schließen ließ, weiß, wie empfindlich ein reibungsloser U-Bahn-Betrieb sein kann. Türstörungen wirken vielleicht geringfügig, können aber lange Verzögerungen, Sicherheitsprobleme und überfüllte Stationen nach sich ziehen. Diese Studie stellt eine einfache, praxisorientierte Frage: Lassen sich mit intelligenten Datentools Türprobleme erkennen, bevor sie tatsächlich ausfallen, damit Wartungsteams rechtzeitig eingreifen und den Betrieb zuverlässig aufrechterhalten können?
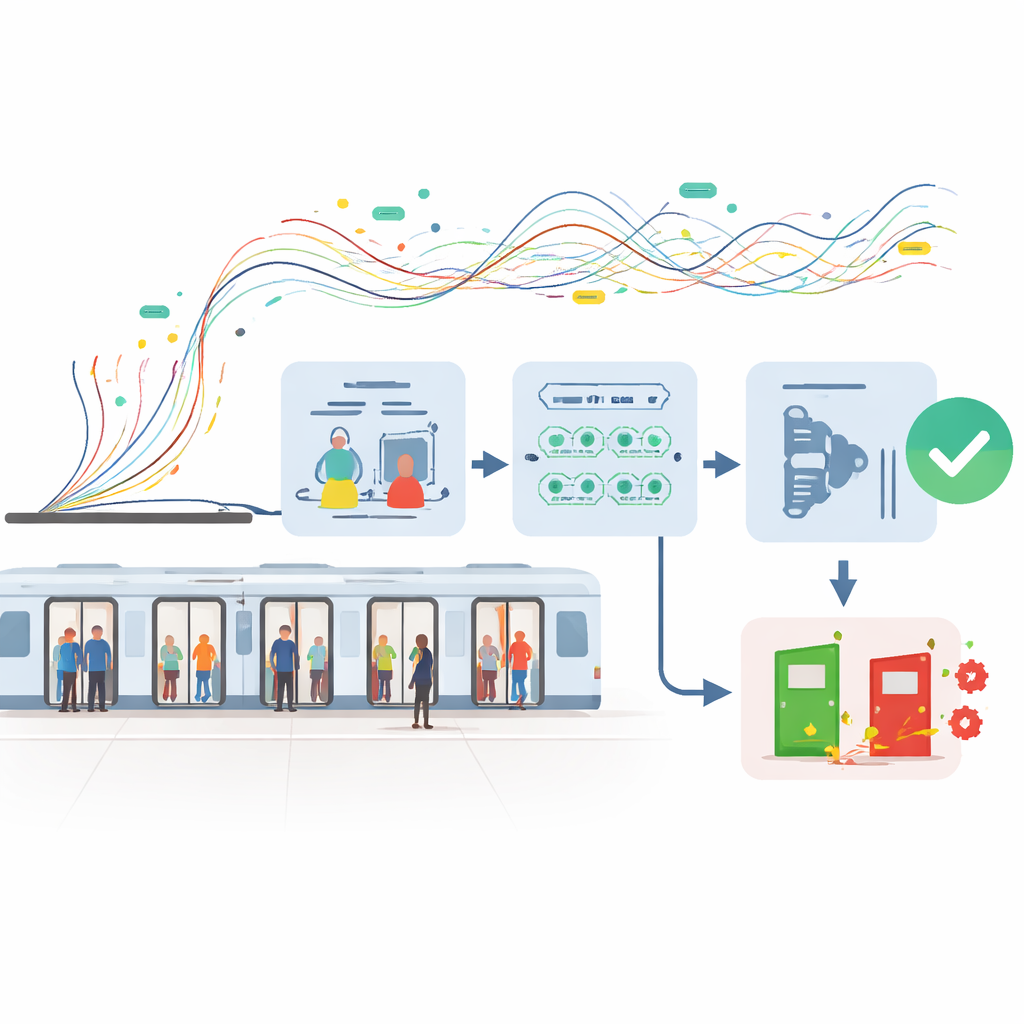
Die Herausforderung seltener, aber relevanter Ausfälle
Störungen an U-Bahn-Türen sind im Vergleich zu der riesigen Zahl normaler Öffnungs- und Schließzyklen, die täglich stattfinden, relativ selten. In dem hier untersuchten Datensatz übertrafen fehlerfreie Türvorgänge die Ausfälle um mehr als das Siebenfache. Dieses Ungleichgewicht schafft eine Schwäche für viele herkömmliche KI-Methoden, die dazu neigen, sich auf die häufigen Muster zu konzentrieren und die ungewöhnlichen zu übersehen. Hinzu kommt, dass das Türsystem eine eng gekoppeltes mechanisches System ist: Motorströme, Rotationswinkel und Zeitabläufe sind durch harte physikalische Grenzen verknüpft. Eine brauchbare Vorhersagemethode muss sehr kleine Frühwarnmuster erkennen, ohne unrealistisches Verhalten zu erfinden, das reale Türen niemals zeigen könnten.
„Realistische Vorstellungskraft" in die Daten bringen
Die Forschenden gingen zunächst das Problem zu wenige Fehlerbeispiele an. Statt auf Standardtricks zurückzugreifen, die seltene Samples einfach kopieren oder mischen, entwarfen sie ein datenaugmentationsverfahren mit physikalischen Beschränkungen. Einfach ausgedrückt erzeugen sie zusätzliche synthetische Fehlerfälle, zwingen aber jede neue Probe dazu, die bekannten Mechaniken der Tür zu erfüllen: Rotationswinkel müssen innerhalb der Konstruktionsgrenzen bleiben, Bewegungsabschnitte müssen sich zur Gesamthubweite addieren, und zeitliche Abweichungen müssen in realistischen Grenzen liegen. Sie variieren bestimmte Zählgrößen und kontinuierliche Bewegungsmaße um kleine, kontrolliert gesteuerte Beträge und filtern dann rigoros jede Probe heraus, die gegen die kinematischen Regeln der Tür verstoßen würde. Ein statistischer Test bestätigt, dass die angereicherten Fehlersdaten der ursprünglichen Fehlerverteilung nahekommen und zugleich physikalisch plausibel bleiben.
Verschiedene Modelle gemeinsam abstimmen lassen
Sobald sie einen stärkeren Trainingsdatensatz hatten, wandte sich das Team einer geschichteten „Kommission“ von Algorithmen zu, um Vorhersagen zu treffen. Zunächst reduzierten sie die ursprünglichen über 40 Sensormerkmale auf eine kompakte Menge von fünf physikalisch aussagekräftigen Variablen, wie etwa maximaler Rotationswinkel und Verzögerungszeit, die zusammen nahezu alle nutzbaren Informationen erfassen. Zwei verschiedene baumbasierte Modelle werden dann parallel trainiert: ein verbessertes Random Forest, das darauf abgestimmt ist, seltenen Fehlerfällen extra Aufmerksamkeit zu schenken und ein Überanpassen an verrauschte Details zu vermeiden, sowie ein XGBoost-Modell, das gut darin ist, aus subtilen Mustern kleine, aber beständige Leistungsgewinne herauszuholen. Anstatt diese Modelle durch einfache Mehrheitsentscheidung abstimmen zu lassen, sitzt eine logistische Regressionsebene obenauf und lernt, wie sich deren Wahrscheinlichkeitsausgaben zu einer einzelnen, gut kalibrierten Fehlerwahrscheinlichkeit kombinieren lassen.
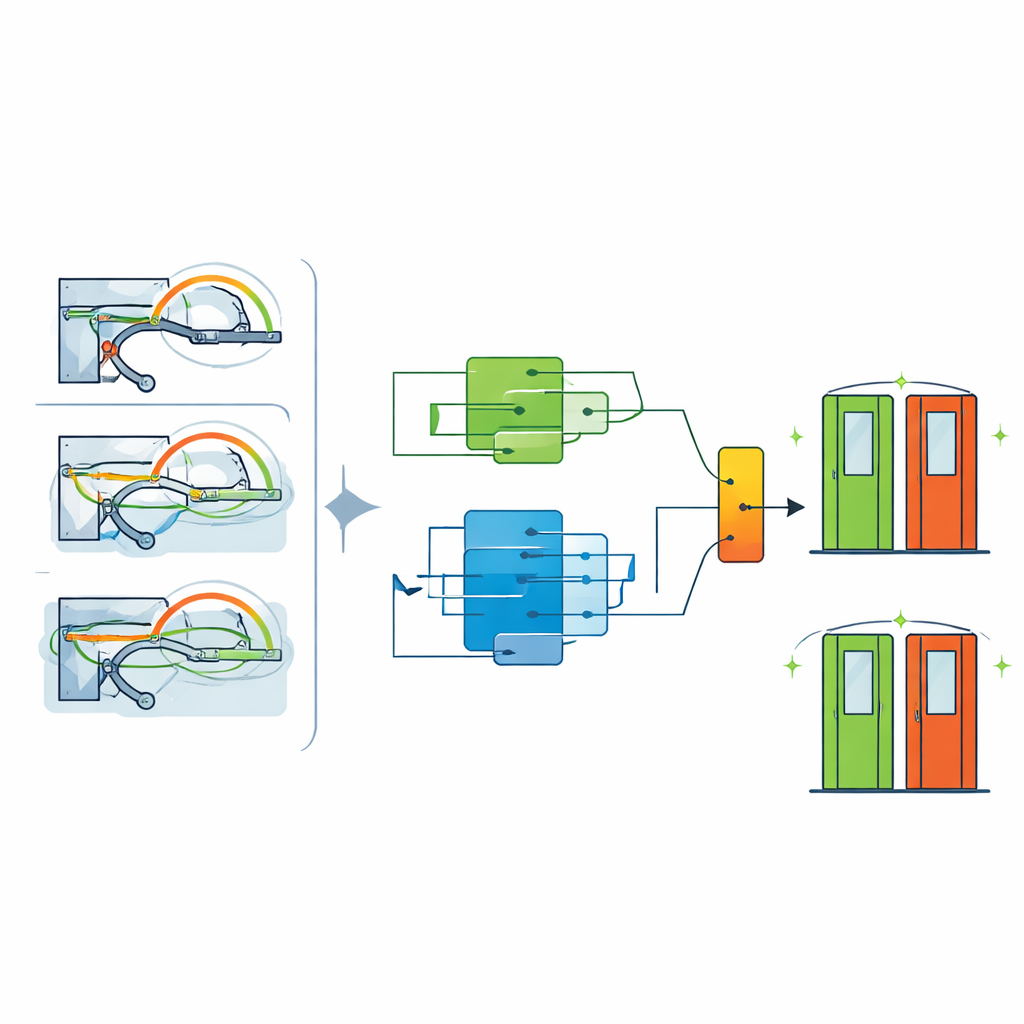
Abwägung zwischen verpassten und falschen Alarmen
Im realen U-Bahn-Betrieb kann das Übersehen eines echten Fehlers weitaus kostspieliger sein als das Senden einer Mannschaft zur Kontrolle einer Tür, die sich später als in Ordnung herausstellt. Die Forschenden vermeiden daher die übliche Regel „größer als 0,5 heißt Fehler“. Sie durchsuchen viele mögliche Grenzwerte auf der Skala der vorhergesagten Wahrscheinlichkeiten und wählen denjenigen aus, der die F1-Score maximiert — ein Maß, das abwägt, wie viele tatsächliche Fehler erfasst werden gegenüber wie viele Alarme korrekt sind. Diese optimierte Einstellung liefert eine starke Kombination aus Genauigkeit, Präzision und Trefferquote auf Testdaten und hervorragende Werte bei globalen Metriken, die für unausgewogene Probleme entwickelt wurden. Ebenso wichtig ist, dass die vorhergesagten Risikowerte selbst gut kalibriert sind, das heißt, dass eine gegebene Wahrscheinlichkeit tatsächlich der Häufigkeit entspricht, mit der auf diesem Niveau Fehler auftreten.
Was das für sicherere, reibungslosere Fahrten bedeutet
Für Laien lautet die Quintessenz: Dieser physikbewusste, mehrschichtige Ansatz verwandelt rohe Sensordaten von U-Bahn-Türen in verlässliche Frühwarnungen darüber, welche Türen wahrscheinlich Probleme bereiten. Indem er die zugrundeliegenden Mechaniken respektiert und gleichzeitig modernes Ensemble-Learning und intelligente Entscheidungsgrenzen nutzt, kann die Methode sowohl plötzliche Blockaden als auch subtile Verschleißerscheinungen mit hoher Sicherheit erkennen — selbst wenn echte Fehlerfälle selten sind. Bei Einsatz in realen Systemen könnte sie Betreiber dabei unterstützen, gezielte Wartungen zu planen, unerwartete Ausfälle zu reduzieren und tägliche Fahrten sicherer und verlässlicher zu machen, ohne das Personal mit falschen Alarmen zu überfrachten.
Zitation: Song, H., Tang, S., Xia, J. et al. Subway door fault prediction employing stacking ensemble learning. Sci Rep 16, 12876 (2026). https://doi.org/10.1038/s41598-026-43371-5
Schlüsselwörter: U-Bahn-Türen, vorausschauende Wartung, Fehlervorhersage, Ensemble-Learning, intelligenter Verkehr