Clear Sky Science · it
Un sistema biometrico multimodale sicuro e spiegabile che utilizza una fusione adattiva alla fiducia per volto e impronta digitale
Perché il tuo volto e la tua impronta hanno bisogno di una serratura più intelligente
I nostri telefoni, laptop e persino le porte degli uffici si affidano sempre più a impronte e scansioni del volto anziché alle password. Ma cosa succede se quelle “chiavi” biometriche vengono copiate o alterate — e come possiamo fidarci dei modelli informatici che decidono chi può entrare? Questo articolo presenta un nuovo modo di combinare dati di volto e impronta digitale che punta a essere più accurato, più rispettoso della privacy e più comprensibile per gli esseri umani, offrendo un’idea di come potrebbero funzionare le serrature digitali del futuro. 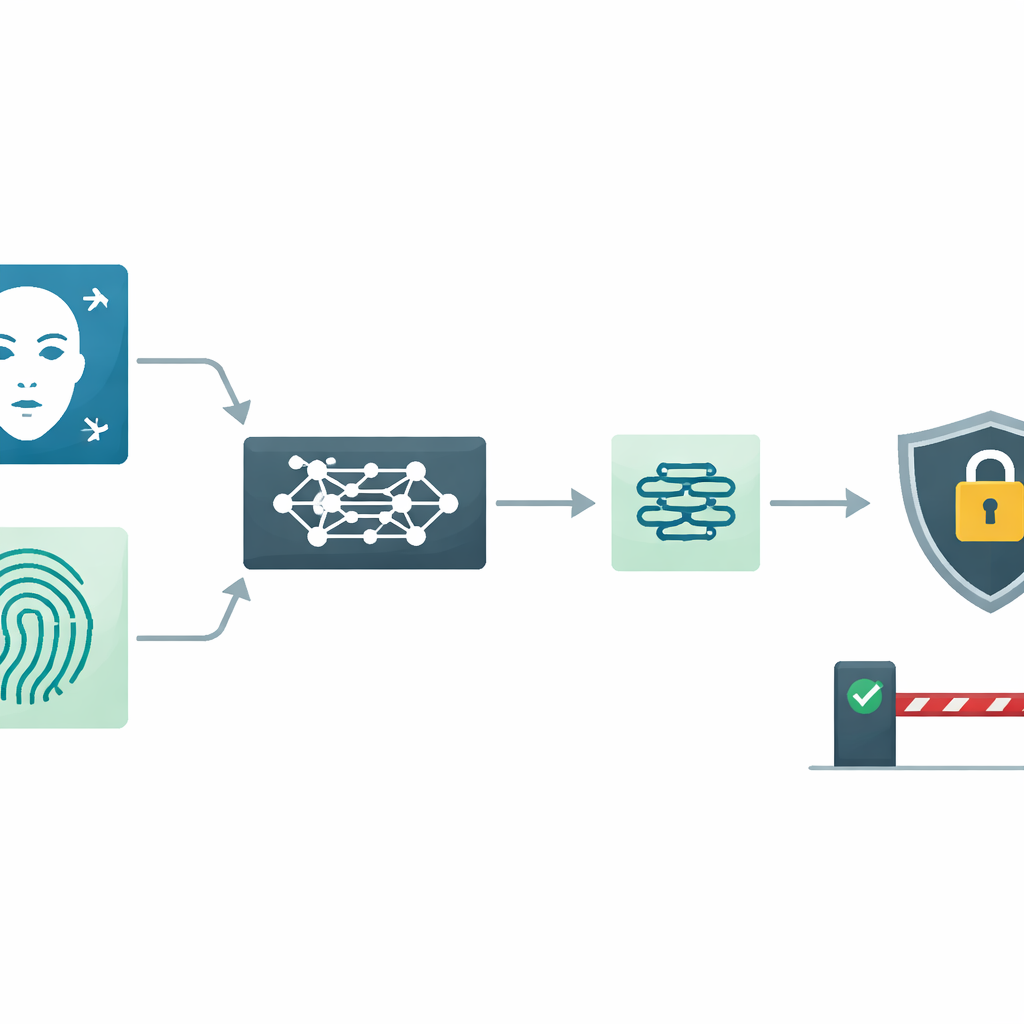
Usare due caratteristiche invece di una
I sistemi biometrici singoli, come gli scanner solo per impronte o solo per volti, possono avere difficoltà quando l’immagine è sfocata, mal illuminata o parzialmente coperta. Gli autori costruiscono un sistema multimodale che usa insieme volto e impronta digitale. Ogni immagine viene prima ripulita: i volti sono rilevati e allineati in modo che occhi, naso e bocca siano in una posizione standard, mentre le impronte vengono denoised, binarizzate e ritagliate sull’area centrale delle creste più informativa. Questa preparazione accurata rende i passi successivi più robusti rispetto a problemi quotidiani come variazioni di illuminazione, pressione del dito o rumore di fondo.
Insegnare un «senso» digitale compatto dell’identità
Invece di costruire manualmente caratteristiche come contorni o pattern di texture fatti a mano, il sistema usa un moderno modello di deep learning chiamato MobileNetV2, potenziato con un meccanismo di «channel attention». In termini semplici, questa rete impara quali parti di un’immagine sono più importanti per distinguere le persone e quali possono essere ignorate. Produce una breve impronta numerica — chiamata embedding — per ogni volto e per ogni impronta digitale. Questi riassunti compatti sono pensati per essere sufficientemente distintivi da separare gli individui, pur essendo efficienti da memorizzare e processare.
Lasciare che sia il sistema a decidere quale segnale fidarsi
I dati del mondo reale sono disordinati: un’impronta sbavata o un selfie poco illuminato possono fuorviare anche un modello potente. Per gestire ciò, gli autori introducono la Trust-Adaptive Fusion (TAF). Il sistema stima quanto è confidente in ciascuna modalità e converte questi livelli di confidenza in punteggi di fiducia. Piuttosto che limitarsi ad accodare le caratteristiche di volto e impronta, assegna più peso a quella più affidabile e meno a quella di qualità inferiore quando forma una rappresentazione combinata. Questa pesatura dinamica aiuta il sistema a rimanere accurato anche quando una fonte d’informazione è degradatasi o parzialmente assente. 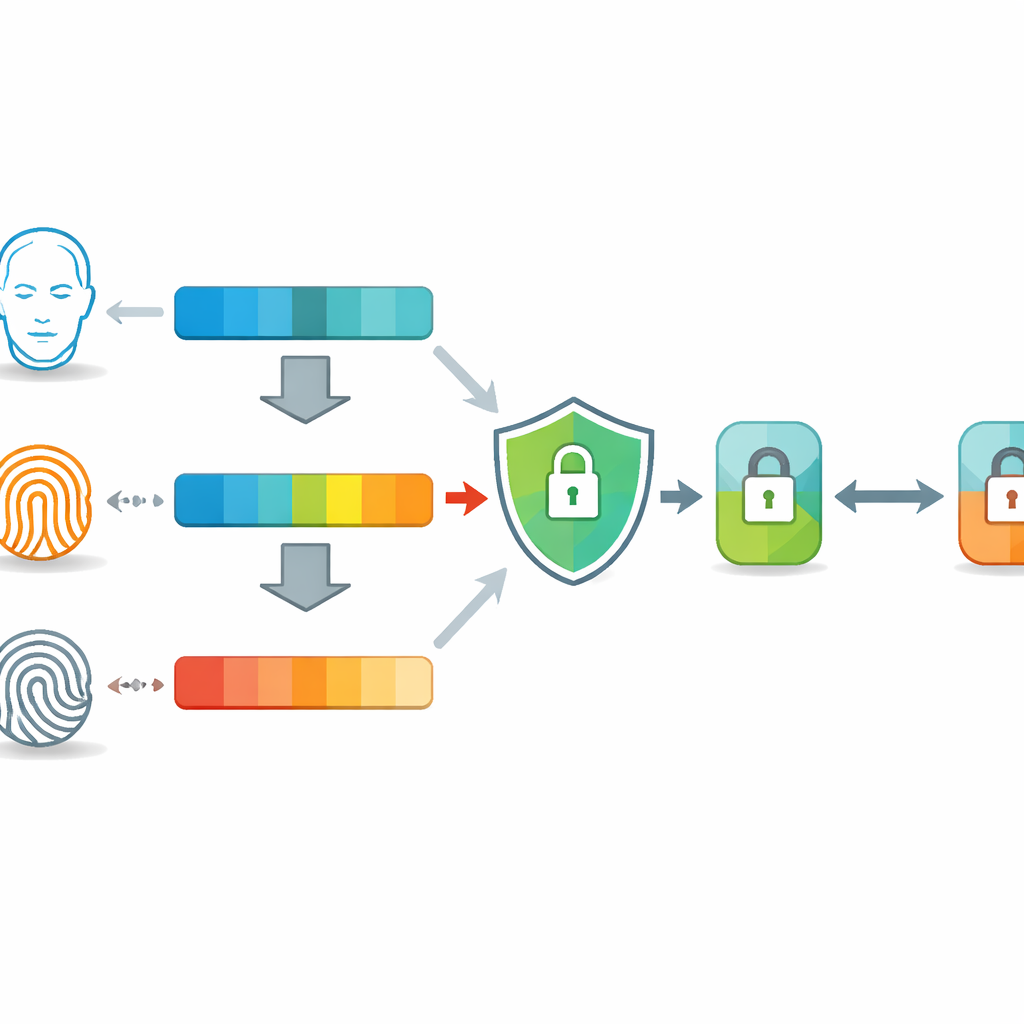
Proteggere i dati mentre si effettua ancora il calcolo
Poiché i tratti biometrici non possono essere cambiati come le password, proteggerli è fondamentale. Il sistema dunque non memorizza né confronta mai le caratteristiche grezze in chiaro. Invece cripta il vettore di caratteristiche fuso usando una tecnica specializzata nota come crittografia omomorfica. Questo metodo permette al server di effettuare il confronto — sostanzialmente misurare la similarità tra un template memorizzato e un nuovo tentativo di accesso — mentre i dati restano criptati. Solo il risultato finale di similarità viene decriptato, il che significa che il template biometrico sottostante resta nascosto anche al server che esegue l’operazione.
Aprire la scatola nera
I modelli di deep learning sono spesso criticati per la loro opacità. Per affrontare questo problema, gli autori integrano un metodo di visualizzazione chiamato Grad-CAM. Per una decisione data, Grad-CAM evidenzia le regioni dell’immagine del volto o dell’impronta che hanno maggiormente influenzato l’esito. Nelle immagini del volto, il sistema si concentra sulle aree attorno a occhi, naso e bocca, mentre nelle immagini di impronte si concentra su terminazioni di cresta e punti di biforcazione, non sullo sfondo rumoroso. Queste mappe di calore aiutano gli utenti e i progettisti del sistema a verificare che il modello si basi su indizi sensati anziché su artefatti casuali.
Quanto funziona bene e perché è importante
Il sistema proposto è testato su dataset pubblici standard per volti e impronte digitali e mostra tassi di errore estremamente bassi: raramente scambia un impostore per un utente autentico o respinge un utente legittimo. Crucialmente, questi risultati si mantengono anche quando tutto l’abbinamento viene effettuato nel dominio criptato, indicando che forti protezioni della privacy non indeboliscono significativamente le prestazioni. Per gli utenti quotidiani, la conclusione è che combinare più tratti biometrici, pesarli in base alla loro qualità e proteggerli con crittografie avanzate può rendere l’accesso digitale sia più sicuro sia più affidabile — senza richiederci di ricordare una singola password complessa.
Citazione: Chitrapu, P., Morampudi, M.K. & Kalluri, H.K. A secure and explainable multimodal biometric system using trust adaptive fusion for face and fingerprint. Sci Rep 16, 14244 (2026). https://doi.org/10.1038/s41598-026-43252-x
Parole chiave: autenticazione biometrica, volto e impronta digitale, sicurezza che preserva la privacy, deep learning, IA spiegabile