Clear Sky Science · fr
Un système biométrique multimodal sûr et explicable utilisant une fusion adaptative de confiance pour le visage et l’empreinte digitale
Pourquoi votre visage et votre empreinte digitale ont besoin d’un verrou plus intelligent
Nos téléphones, ordinateurs portables et même les portes de bureau s’appuient de plus en plus sur les empreintes digitales et les scans du visage plutôt que sur des mots de passe. Mais que se passe-t-il si ces « clés » biométriques sont copiées ou altérées — et comment pouvons-nous faire confiance aux modèles informatiques qui décident qui peut entrer ? Cet article présente une nouvelle manière de combiner les données de visage et d’empreinte digitale visant à être plus précise, plus respectueuse de la vie privée et plus compréhensible pour les humains, offrant un aperçu du fonctionnement possible des serrures numériques de demain. 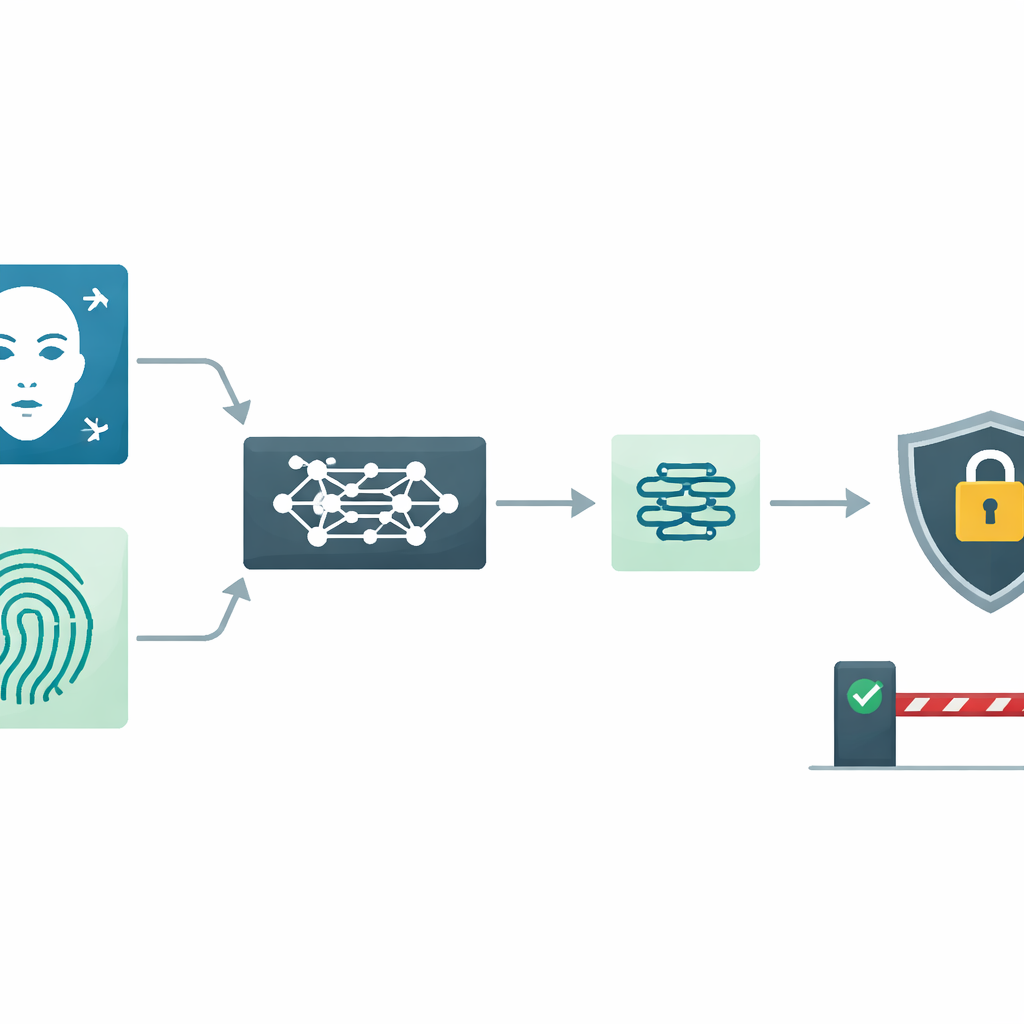
Utiliser deux traits plutôt qu’un
Les systèmes biométriques uniques, comme les lecteurs d’empreintes uniquement ou de visage uniquement, peuvent montrer leurs limites lorsque l’image est floue, mal éclairée ou partiellement couverte. Les auteurs construisent un système multimodal qui utilise à la fois le visage et l’empreinte digitale. Chaque image est d’abord nettoyée : les visages sont détectés et alignés pour que les yeux, le nez et la bouche soient dans une position standard, tandis que les empreintes digitales sont débruitées, binarisées et recadrées sur la zone centrale la plus informative des crêtes. Cette préparation soignée rend les étapes suivantes plus robustes face aux problèmes courants comme les variations d’éclairage, la pression du doigt ou l’encombrement de l’arrière-plan.
Enseigner un « sens » numérique compact de l’identité
Plutôt que de concevoir manuellement des caractéristiques comme des contours ou des motifs de texture faits à la main, le système utilise un modèle d’apprentissage profond moderne appelé MobileNetV2, renforcé par un mécanisme d’« attention de canal ». En termes simples, ce réseau apprend quelles parties d’une image importent le plus pour différencier les personnes et lesquelles peuvent être négligées en toute sécurité. Il produit un court « empreinte » numérique — appelée embedding — pour chaque visage et chaque empreinte digitale. Ces résumés compacts sont conçus pour être suffisamment distinctifs pour séparer les individus tout en restant efficaces à stocker et à traiter.
Laisser le système décider quel signal mérite confiance
Les données du monde réel sont désordonnées : une empreinte smudgée ou un selfie faiblement éclairé peut tromper même un modèle puissant. Pour y faire face, les auteurs introduisent la Fusion Adaptative de Confiance (Trust-Adaptive Fusion, TAF). Le système estime sa confiance dans chaque modalité et convertit ces niveaux de confiance en scores de confiance. Plutôt que d’empiler simplement les caractéristiques du visage et de l’empreinte, il pondère davantage la modalité la plus fiable et moins la modalité de moindre qualité lors de la formation d’une représentation combinée. Ce poids dynamique aide le système à rester précis même lorsqu’une source d’information est dégradée ou partiellement manquante. 
Verrouiller les données tout en effectuant les calculs
Parce que les traits biométriques ne peuvent pas être changés comme des mots de passe, leur protection est cruciale. Le système ne stocke ni ne compare donc jamais de caractéristiques brutes en clair. À la place, il chiffre le vecteur de caractéristiques fusionné en utilisant une technique spécialisée connue sous le nom de chiffrement homomorphe. Cette méthode permet au serveur d’effectuer la comparaison — essentiellement mesurer la similarité entre un modèle stocké et une tentative d’authentification — tandis que les données restent chiffrées. Seul le résultat final de similarité est déchiffré, ce qui signifie que le modèle biométrique sous-jacent demeure caché, même pour le serveur qui effectue le travail.
Ouvrir la boîte noire
Les modèles d’apprentissage profond sont souvent critiqués pour leur opacité. Pour y remédier, les auteurs intègrent une méthode de visualisation appelée Grad-CAM. Pour une décision donnée, Grad-CAM met en évidence les régions de l’image du visage ou de l’empreinte digitale qui ont le plus influencé le résultat. Sur les images de visage, le système se concentre sur les zones autour des yeux, du nez et de la bouche, tandis que sur les images d’empreintes il cible les terminaisons de crêtes et les points de bifurcation, et non les arrière-plans bruyants. Ces cartes de chaleur aident les utilisateurs et les concepteurs du système à vérifier que le modèle s’appuie sur des indices pertinents plutôt que sur des artefacts accidentels.
Performances et importance
Le système proposé est testé sur des jeux de données publics standards pour les visages et les empreintes digitales et affiche des taux d’erreur extrêmement faibles : il confond très rarement un imposteur avec un utilisateur genuine ou rejette un utilisateur légitime. Fait crucial, ces résultats se maintiennent même lorsque toutes les comparaisons sont effectuées dans le domaine chiffré, indiquant que de fortes protections de la vie privée n’affaiblissent pas significativement les performances. Pour l’utilisateur quotidien, la conclusion est que combiner plusieurs traits biométriques, les pondérer selon leur qualité et les protéger par un chiffrement avancé peut rendre l’accès numérique à la fois plus sûr et plus digne de confiance — sans nous obliger à nous souvenir d’un seul mot de passe complexe.
Citation: Chitrapu, P., Morampudi, M.K. & Kalluri, H.K. A secure and explainable multimodal biometric system using trust adaptive fusion for face and fingerprint. Sci Rep 16, 14244 (2026). https://doi.org/10.1038/s41598-026-43252-x
Mots-clés: authentification biométrique, visage et empreinte digitale, sécurité préservant la vie privée, apprentissage profond, IA explicable