Clear Sky Science · it
Ottimizzazione di un assorbitore metamateriale broadband mediante la tecnica di reinforcement learning Twin Delayed Deep Deterministic Policy Gradient
Materiale didattico per domare le onde
I collegamenti wireless moderni, la TV satellitare e i radar dipendono tutti dalla modellazione di onde invisibili in modi molto precisi. Gli ingegneri oggi progettano “metamateriali” – superfici microstrutturate – che possono assorbire segnali indesiderati o ruotarne la polarizzazione per comunicazioni più chiare e capacità di occultamento. Questo articolo mostra come una forma di intelligenza artificiale, il reinforcement learning, possa scoprire automaticamente progetti ad alte prestazioni per queste strutture complesse, impiegando ore per compiti che altrimenti richiederebbero settimane di tentativi ed errori da parte di esperti.
Perché modellare le onde è importante
I metamateriali sono superfici ingegnerizzate composte da motivi microscopici ripetuti che interagiscono con le onde elettromagnetiche in modi non convenzionali. Regolando le forme e le distanze di questi motivi, i ricercatori possono creare assorbitori ultra‑sottili che catturano quasi tutta la radiazione incidente, o convertitori che ribaltano la polarizzazione di un'onda—trasformando, per esempio, un segnale orizzontale in uno verticale. Tali dispositivi sono fondamentali per ridurre la firma radar, diminuire le interferenze tra canali e aumentare la quantità di informazioni trasmissibili nelle bande di frequenza affollate usate dai sistemi satellitari e wireless.
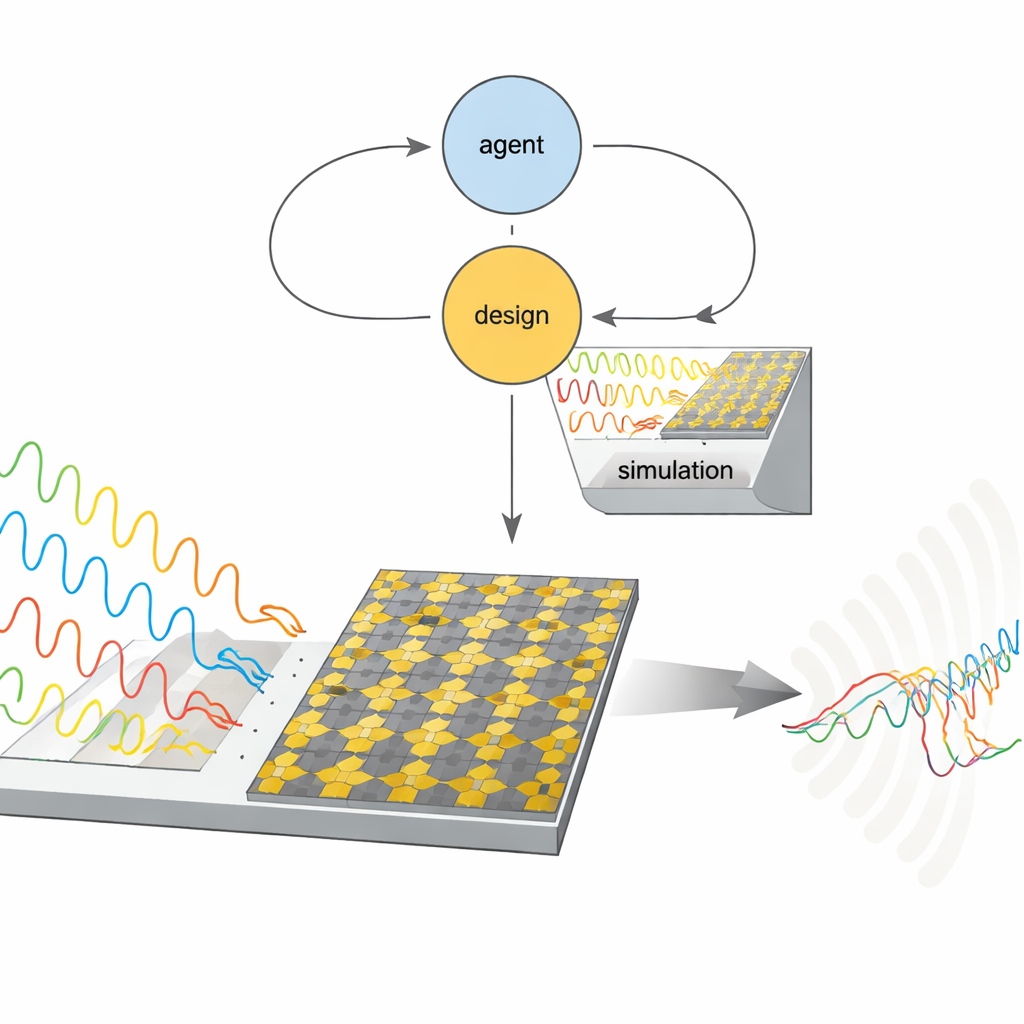
Lasciare che un algoritmo faccia il progetto
Tradizionalmente, gli ingegneri ottimizzano i progetti dei metamateriali con esplorazioni manuali dei parametri o metodi euristici come gli algoritmi genetici. Questi approcci possono essere lenti, dispendiosi in termini di calcolo e sensibili alle ipotesi iniziali, soprattutto quando ci sono molti gradi di libertà geometrici da regolare. Gli autori invece ricorrono a un metodo di reinforcement learning chiamato Twin Delayed Deep Deterministic Policy Gradient (TD3). In questo schema, un “agente” artificiale propone un insieme di dimensioni geometriche per la cella metamateriale, un simulatore fisico valuta quanto bene quel progetto assorbe o converte le onde su una banda di frequenza target, e l'agente riceve un punteggio di ricompensa. Iterando questo ciclo di proposta e valutazione, l'agente apprende gradualmente quali pattern funzionano meglio, senza bisogno di formule esplicite o modelli surrogati preaddestrati.
Costruire una spugna d'onda migliore
Il primo banco di prova è un assorbitore a microonde ultra‑sottile costruito con tracce in rame a forma di L sopra un piano metallico di supporto, separate da un comune materiale per circuiti stampati. L'obiettivo è un'elevata assorbimento—superiore al 90 percento—su una gamma di frequenze il più ampia possibile nelle bande Ku e K usate per i collegamenti satellitari e i radar. L'agente TD3 controlla quattro caratteristiche geometriche chiave del motivo e interagisce direttamente con un simulatore elettromagnetico commerciale. In modo notevole, in sole 23 iterazioni l'algoritmo converge su un progetto che assorbe più del 90 percento delle onde incidenti da 12,2 a 22,4 gigahertz, una banda più ampia rispetto a versioni ottimizzate a mano o algoritmicamente usando lo stesso layout di base. Test aggiuntivi su un differente assorbitore ottico completamente dielettrico mostrano che lo stesso framework di apprendimento può migliorare anche le prestazioni in quel dominio, ampliando la banda utile e aumentando l'assorbimento medio.
Invertire la polarizzazione
Gli autori mettono poi alla prova il metodo con un compito più complesso: progettare una superficie che rifletta le onde incidenti richiedendone però la conversione di polarizzazione su un'ampia gamma di frequenze. Partono da un motivo a singolo strato che combina tracce in rame a L con un triangolo centrale sopra lo stesso sottile substrato e piano metallico di supporto. Anche in questo caso l'agente TD3 regola i dettagli geometrici. Dopo circa 81 iterazioni trova una configurazione che converte più del 90 percento della potenza riflessa nella polarizzazione ortogonale da 11,8 a 24,2 gigahertz—coprendo l'intera banda Ku e la maggior parte della banda K. Le simulazioni mostrano inoltre che questa elevata conversione sopravvive per onde che colpiscono la superficie con angoli fino a 50 gradi, una caratteristica desiderabile per antenne reali e rivestimenti stealth.
Dalla simulazione al banco di laboratorio
Per verificare che questi progetti scoperti dall'IA siano praticabili, il team fabbrica la superficie convertitrice di polarizzazione usando la fotolitografia standard su un array 40×40 di celle unitarie. Misurazioni con antenne a corno e un analizzatore vettoriale di reti confermano una forte riflessione cross‑polarizzata su una banda quasi sovrapponibile a quella prevista dalle simulazioni, con solo modeste differenze dovute alle tolleranze di fabbricazione e alle dimensioni finite del campione. Rispetto ad altri dispositivi riportati, questa struttura a singolo strato ottiene una larghezza di banda e un'efficienza comparabili o migliori rimanendo compatta e priva di componenti circuitali aggiuntivi.
Cosa significa per il futuro
Dimostrando che un agente di reinforcement learning TD3 può rapidamente convergere su progetti metamateriali ad alte prestazioni e pronti per la fabbricazione, questo lavoro indica una nuova modalità per ingegnerizzare dispositivi che controllano luce e onde radio. Invece di esplorare faticosamente gli spazi di progetto a mano, i ricercatori possono definire un obiettivo—come assorbimento broadband o conversione di polarizzazione robusta—e lasciare che l'algoritmo di apprendimento esplori il vasto paesaggio delle possibilità. L'approccio è sufficientemente generale da estendersi oltre assorbitori e polarizzatori a molti altri componenti fotonici e a microonde, accelerando potenzialmente l'innovazione in tutto, dalle antenne a basso profilo ai sensori ottici e alle superfici per la raccolta di energia.
Citazione: Mahmoud, B.E., Ali, T.A., Obayya, S.S.A. et al. Optimization of broadband metamaterial absorber using twin delayed deep deterministic policy gradient reinforcement learning technique. Sci Rep 16, 12745 (2026). https://doi.org/10.1038/s41598-026-41716-8
Parole chiave: assorbitore metamateriale, convertitore di polarizzazione, progettazione con reinforcement learning, dispositivi a microonde broadband, ottimizzazione fotonica