Clear Sky Science · he
SVDHLA: אוטומט למידה היברידי סימטרי בעומק משתנה ויישומו
להדריך מכונות מתי להפסיק לנסות
מערכות למידה מודרניות נתקלות לעתים קרובות בדילמה פשוטה אך קריטית: כמה זמן כדאי להמשיך לבחור באותה אפשרות לפני שעוברים למשהו חדש? מאמר זה עוסק בשאלה עבור מודל קבלת החלטות קלאסי ומראה כיצד מתן יכולת למערכת להתאים בעצמה את מידת ההתמדה שלה יכול להפוך אותה למהירה יותר, אמינה יותר, ואפילו מועילה בהכשרת רשתות עצביות טובות יותר.

מדוע ניסוי וטעיה קלאסי לא מספיק
העבודה מתבססת על רעיון ותיק הנקרא אוטומט למידה, מודל פשוט שבוחר שוב ושוב בין מספר אפשרויות ולומד מתגמולים ועונשים. גרסה נפוצה, הידועה כ-LK,N,K, מייצגת כל אפשרות כסולם פנימי קצר של מצבים. ככל שהסולם עמוק יותר, כך דרוש יותר עונש לפני שהאוטומט מוותר על אותה אפשרות. עומק קטן גורם למערכת לשנות את דעתה במהירות, מעודד חקירה, בעוד עומק גדול הופך אותה לעקשנית, ומעדיף ניצול של מה שנדמה שעובד. הבעיה היא שעומק זה חייב להיות נקבע מראש, למרות שהבחירה הטובה ביותר תלויה במידה רבה בבעיה ויכולה להשתנות עם הזמן. בסביבות סטטיות בחירה לקויה מאטה את הלמידה; בסביבות משתנות היא עלולה ללכוד את המערכת בהתנהגות מיושנת או לגרום לה להיות רוטטת ולא יציבה.
תחושת התמדה המתכווננת בעצמה
כדי להתגבר על הנוקשות הזו, המחברים מציגים את SVDHLA, קיצור של Symmetric Variable Depth Hybrid Learning Automaton. במקום לקבע את העומק מראש, SVDHLA מחברת את האוטומט הקלאסי המבוסס סולמות לאחד נוסף, קטן יותר, שתפקידו היחיד הוא לכוונן עד כמה הסולמות יהיו עמוקים. העוזר הזה בוחר בין שלוש פעולות פשוטות עבור כל המערכת: להעמיק את כל האפשרויות באחד, לקצר את כל העומקים באחד, או לעצור ולשמור על העומק הנוכחי. הוא מקבל החלטותיו על בסיס עד כמה האוטומט הראשי התפקד לאחרונה, מסוכם על ידי כמה פעמים הוא מגיע למצבים הפנימיים המועדפים ביותר לעומת כמה פעמים הוא נאלץ לעבור אפשרות. עם הזמן נוצרת לולאת משוב: אם המערכת משנה בחירה לעתים קרובות מדי, העוזר נוטה להגדיל עומק ולהפוך לסבלני יותר; אם היא נאחזת באפשרויות גרועות, הוא נוטה לצמצם עומק ולהגיב מהר יותר.
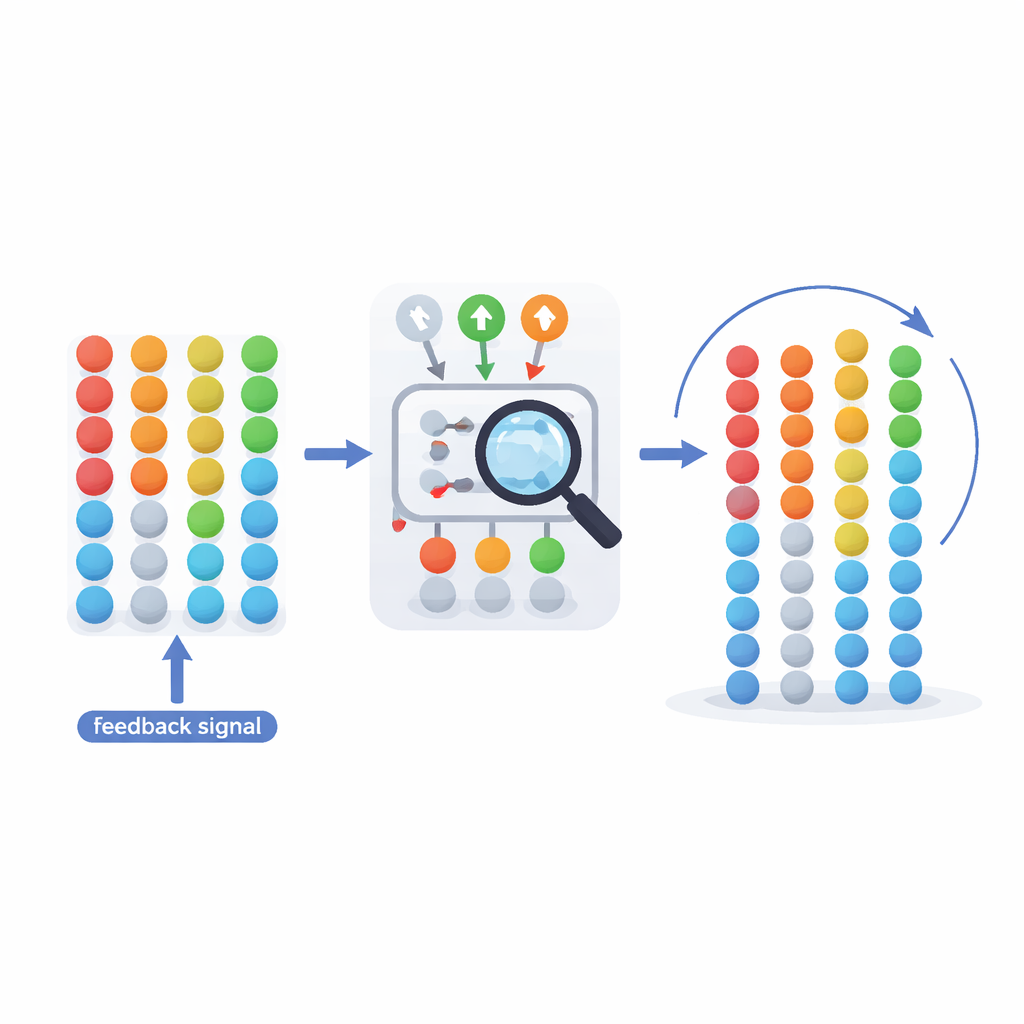
מבחן על הלומד החדש
החוקרים בדקו את SVDHLA במגוון עולמות מדומים במחשב. חלקם היו בעלי דפוסי תגמול קבועים; אחרים השתנו באופן לא צפוי עם הזמן או הענישו בחירות שחוזרות תדיר. בכל התסריטים הגישה החדשה צברה באופן עקבי יותר תגמול כולל וסבלה פחות מצערת — כלומר, מההפסד בהזדמנות בהשוואה לקבלת החלטות אידיאלית — מאשר גם המודל המקורי וגם גרסה היברידית חדשה יותר. היתרון המרכזי הוא ש-SVDHLA יכולה לגלות בעצמה אם עליה להתנהג בזהירות או באומץ, ולכוונן את עמדתה כשהתנאים משתנים. אפילו במקרים מאתגרים עם הרבה פעולות אפשריות ורק אחת או שתיים טובות, המערכת התייצבה במהירות בטווח שימושי של עומקים במקום להמשיך להתעסק בפעולות מבניות ללא סוף.
מתורי תורים ותנועה ועד רשתות עצביות
כדי להראות שזו אינה רק שיפור צעצועי, המחברים יישמו את SVDHLA בשני בעיות מעשיות. ראשית, השתמשו בה כדי להכריע איזו תור השרת צריך לטפל בו בהדמיית מערכת מחשב שבה משימות מגיעות ונגמרות בקצבים לא אחידים. כאן, העומק האדפטיבי עזר למערכת התזמון לשמור על זמני המתנה ממוצעים נמוכים יותר מאשר גם אוטומטים לומדים מסורתיים וגם אלגוריתמים בסגנון רצועת-ידיות פופולריים כמו סופטמקס, גבולות ביטחון עליונות ו-Thompson sampling. שנית, השתמשו ב-SVDHLA כבקר להפלות באימון רשת עצבית — הטכניקה של ניתוק יחידות באופן אקראי במהלך האימון כדי למנוע התאמה יתרה. במקום להשתמש בשיעור הפלה קבוע, SVDHLA למדה, אצווה אחרי אצווה, האם להעלות, להוריד או לשמור את רמת ההפלה על סמך השינויים באיבוד. הפלה אדפטיבית זו הניבה דיוק מעט גבוה יותר ותוצאות יציבות יותר במשימת זיהוי ספרות MNIST מאשר בקר מבוסס אוטומט למידה קודם.
מה משמעות הדבר עבור מערכות למידה חכמות
במונחים יומיומיים, SVDHLA נותנת ללומד בניסיון וטעיה תחושת כוונון עצמי לגבי כמה עקשן עליו להיות. במקום להסתמך על מהנדס אדם לנחש את האיזון הנכון בין ניסיון אופציות חדשות להיצמדות לישנות, המערכת מודדת את הצלחותיה וכישלונותיה ומתאימה את התמדה שלה בהתאם. המחקר מראה ששכבת התאמה נוספת פשוטה זו יכולה לשפר ביצועים בסביבות סטטיות ומשתנות גם יחד, וניתן לשלב אותה במערכות גדולות יותר כגון מנהלי תורים ורשתות עצביות. מבט קדימה, רעיונות דומים יכולים לעזור לשיטות למידה רבות אחרות לכייל אוטומטית כמה מהר הן משנות את דעתן, מה שהופך מקבלי החלטות מלאכותיים לעמידים יותר וקלים יותר לפריסה.
ציטוט: Nikhalat-Jahromi, A., Saghiri, A.M. & Meybodi, M.R. SVDHLA: symmetric variable depth hybrid learning automaton and its application. Sci Rep 16, 14336 (2026). https://doi.org/10.1038/s41598-026-43271-8
מילות מפתח: אוטומטים לומדים, למידת חיזוק, חקירה ניצול, הפלה אדפטיבית, רצועת ידיות מרובה