Clear Sky Science · fr
Autoencodeur graphe spatio-temporel pour l’évaluation automatisée des actions humaines en 3D dans une formation immersive en réalité virtuelle pour archéologues
S’exercer à des travaux délicats sans quitter le laboratoire
Beaucoup de métiers exigent des mouvements corporels précis et sûrs, mais l’entraînement en conditions réelles peut être risqué, coûteux ou difficile à reproduire. Cette étude montre comment la réalité virtuelle et la technologie de suivi du mouvement peuvent s’associer à l’intelligence artificielle pour coacher des archéologues lorsqu’ils creusent, raclent et soulèvent, le tout dans un chantier d’excavation numérique. Les mêmes idées pourraient un jour servir à former des chirurgiens, des ouvriers d’usine ou des sportifs en transformant le mouvement d’un expert en un référentiel que chacun peut apprendre à reproduire.
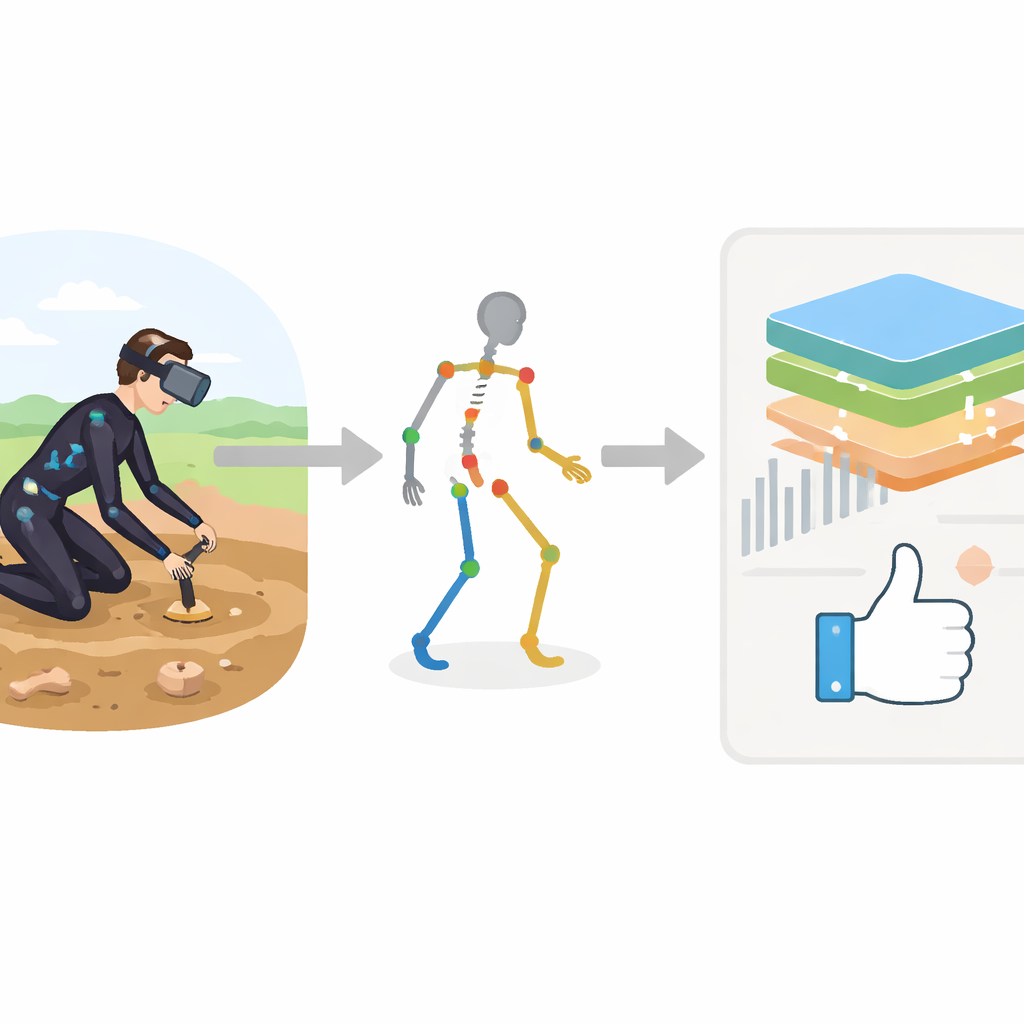
Entrer dans un site de fouille virtuel
Les chercheurs ont développé un système de formation immersif qui place l’archéologue dans une zone d’excavation virtuelle à l’aide d’un casque Meta Quest 3. En parallèle, une combinaison de capture de mouvement Xsens MVN Awinda, équipée de 17 petits capteurs, suit les déplacements de chaque partie du corps en trois dimensions. Plutôt que de se contenter de rejouer le mouvement, le système transforme chaque enregistrement en une description structurée du corps : tête, tronc, bras et jambes deviennent des points d’un squelette numérique, chacun accompagné de mesures détaillées comme la vitesse, l’accélération et les angles articulaires au fil du temps. Ce flux riche de données constitue la matière première d’un coach automatisé.
Apprendre à l’ordinateur ce qu’est un « bon mouvement »
Pour transformer le savoir-faire des experts en un standard d’entraînement, l’équipe a d’abord demandé à des archéologues professionnels d’exécuter des tâches typiques avec une truelle, une pioche et une pelle. Ces exemples d’experts servent de mouvements « idéaux ». Un modèle d’intelligence artificielle spécialisé, appelé AEforGraph, apprend alors à compresser chaque séquence de mouvement en un code interne compact qui conserve la manière dont les articulations se déplacent ensemble dans l’espace et dans le temps. Ce modèle accorde plus d’attention aux articulations les plus critiques — par exemple la main et l’avant-bras pour le travail fin à la truelle — de sorte que la sécurité et la précision dans les zones clés comptent davantage que les mouvements d’arrière-plan ailleurs.
Comment le système détecte les erreurs
Une fois le modèle entraîné à ces codes internes du mouvement, il regroupe les mouvements similaires en grappes, chacune centrée sur un motif de référence qui reflète une action idéale, comme un bon mouvement de pelle. Lorsqu’un stagiaire réalise un nouveau geste, le système l’encode, retrouve le motif de référence le plus proche, puis reconstruit ce que le stagiaire a réellement fait. En comparant la reconstruction du stagiaire avec l’idéal articulations par articulations et instant par instant, le système peut estimer à quel point chaque partie du corps s’est écartée de la posture d’expert. Ces différences peuvent être traduites en retours faciles à comprendre, par exemple quel segment de bras a bougé trop vite ou sous le mauvais angle.
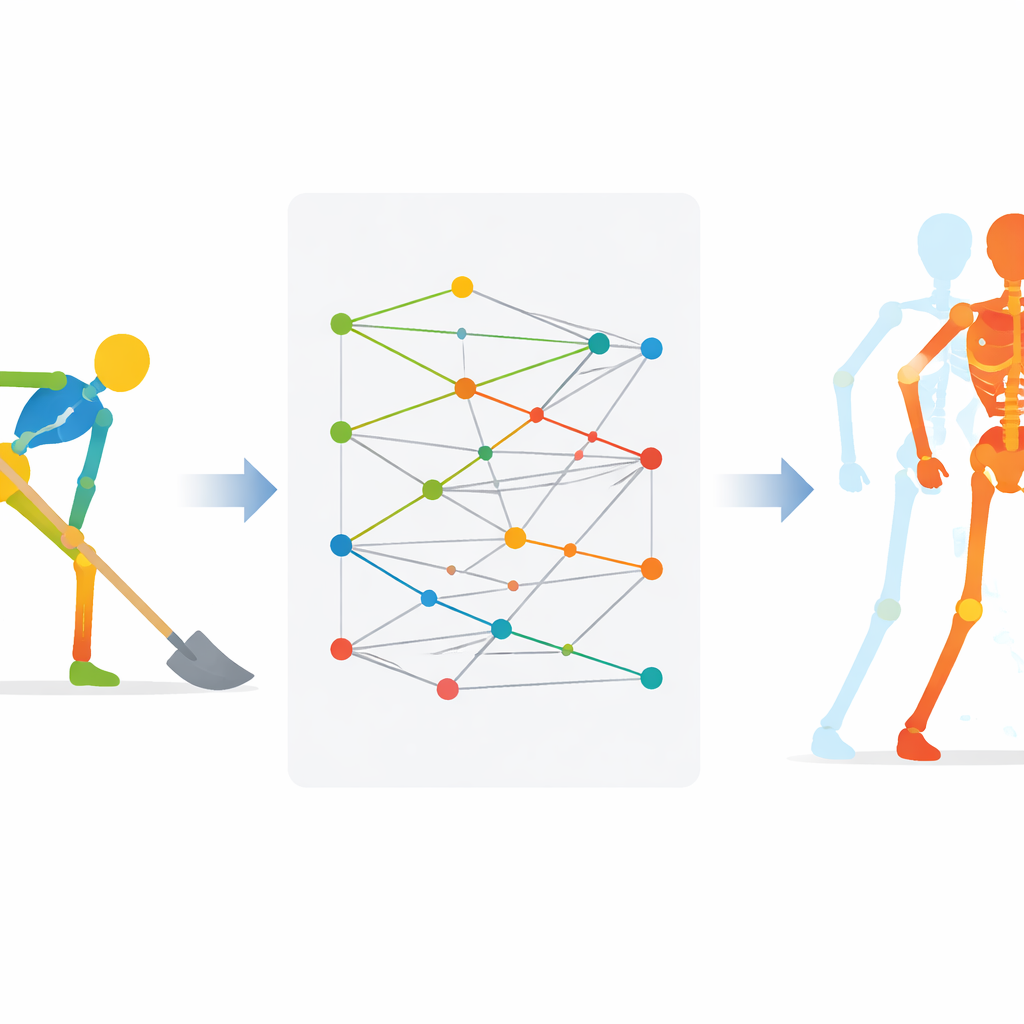
Mettre le coach virtuel à l’épreuve
L’équipe a enregistré 509 mouvements réels effectués par huit archéologues pour entraîner et évaluer le système. Leur autoencodeur, AEforGraph, a reproduit les données de mouvement avec une grande précision, conservant plus de quatre-vingt-dix pour cent de la variation originale tout en réduisant fortement sa complexité. Comparé à un modèle de base bien connu, il a mieux capturé la manière dont les mouvements se déroulent dans le temps. Utilisée pour classer les mouvements en trois groupes liés aux outils — truelle, pioche et pelle — la méthode de clustering semi-supervisée a correctement assigné plus de 97 % des échantillons. Lors des tests en réalité virtuelle avec tout le matériel en fonctionnement, le système fournissait généralement un retour environ une seconde après chaque action enregistrée et choisissait presque toujours la bonne grappe pour le mouvement réalisé.
Pourquoi cela dépasse l’archéologie
Pour un non-spécialiste, la principale réalisation est un plan opérationnel pour un coach numérique du mouvement : la réalité virtuelle offre un cadre sûr et réaliste ; les capteurs de capture de mouvement enregistrent le comportement corporel en détail ; et un modèle intelligent compare chaque essai à des exemples d’experts pour fournir un retour ciblé en temps réel. Bien que l’étude de cas se concentre sur les archéologues, le cadre est général. Avec des exemples et des données de mouvement appropriés, la même approche pourrait aider à perfectionner des tâches en médecine, en rééducation, dans l’industrie ou le sport, guidant les personnes vers des gestes plus sûrs et plus efficaces sans nécessiter la présence d’un instructeur à chaque répétition.
Citation: Pradisi, V., Marini, M.R., Castelli Gattinara Di Zubiena, F. et al. Spatio-temporal graph autoencoder for automated evaluation of human actions in 3D in immersive VR-based training for archaeologists. Sci Rep 16, 10568 (2026). https://doi.org/10.1038/s41598-026-46138-0
Mots-clés: formation en réalité virtuelle, capture de mouvement, archéologie, analyse du mouvement humain, réseaux de neurones graphiques