Clear Sky Science · en
Spatio-temporal graph autoencoder for automated evaluation of human actions in 3D in immersive VR-based training for archaeologists
Practicing Delicate Work Without Leaving the Lab
Many jobs depend on precise, safe body movements, yet real-world practice can be risky, costly, or hard to repeat. This study shows how virtual reality and motion-tracking technology can team up with artificial intelligence to coach archaeologists as they dig, scrape, and lift, all inside a digital excavation site. The same ideas could one day help train surgeons, factory workers, or athletes by turning expert motion into a standard that anyone can learn to match.
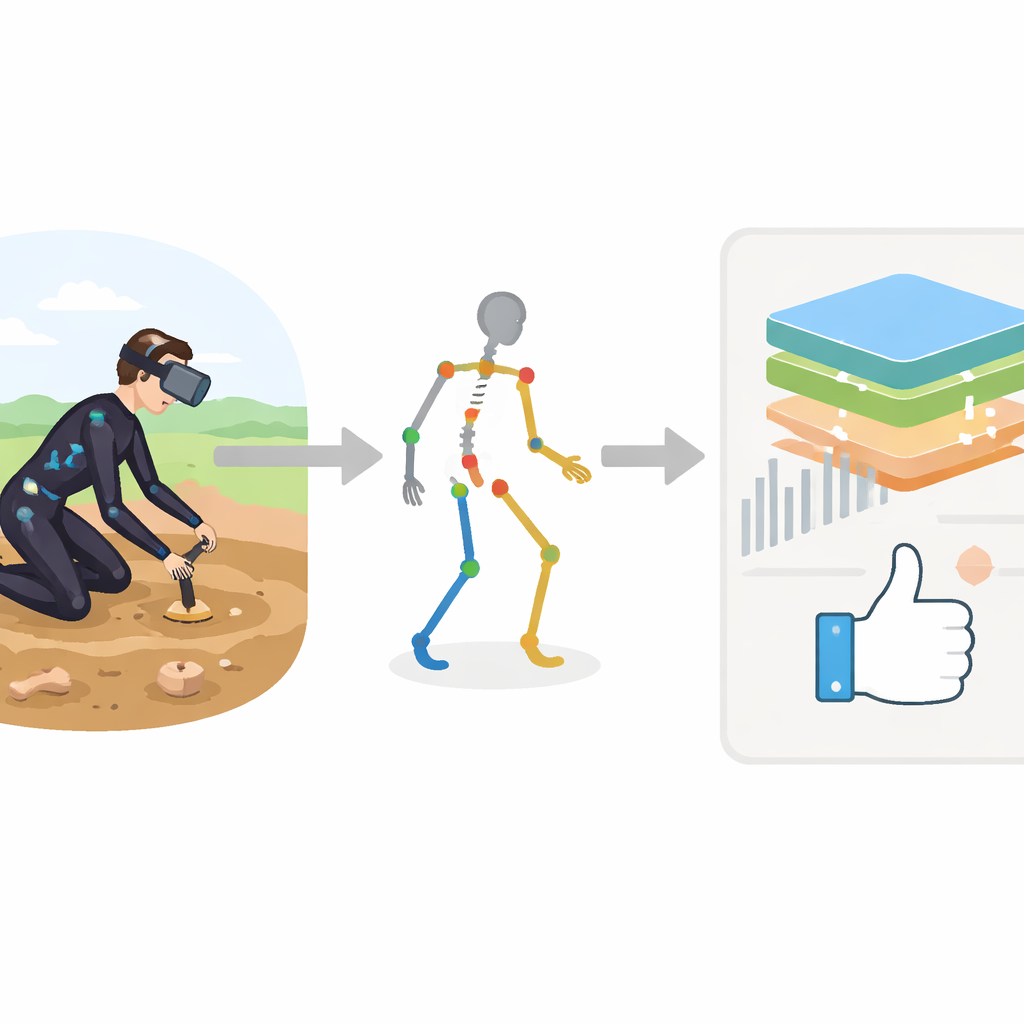
Stepping Into a Virtual Dig Site
The researchers built an immersive training system that places an archaeologist in a virtual excavation area using a Meta Quest 3 headset. At the same time, an Xsens MVN Awinda motion-capture suit, fitted with 17 small sensors, tracks how each part of the body moves in three dimensions. Instead of simply replaying the motion, the system transforms every recording into a structured description of the body: head, trunk, arms, and legs become points in a digital skeleton, each with detailed measurements like speed, acceleration, and joint angles over time. This rich stream of data becomes the raw material for an automated coach.
Teaching a Computer What “Good Movement” Looks Like
To turn expert know-how into a training standard, the team first asked professional archaeologists to perform typical tasks with a trowel, pickaxe, and shovel. These expert examples serve as “ideal” movements. A specialized artificial intelligence model, called AEforGraph, then learns to compress each motion sequence into a compact internal code that preserves how the body’s joints move together in space and time. This model pays more attention to the most critical joints—for example, the hand and forearm in fine trowel work—so that safety and precision in key areas matter more than background motion elsewhere.
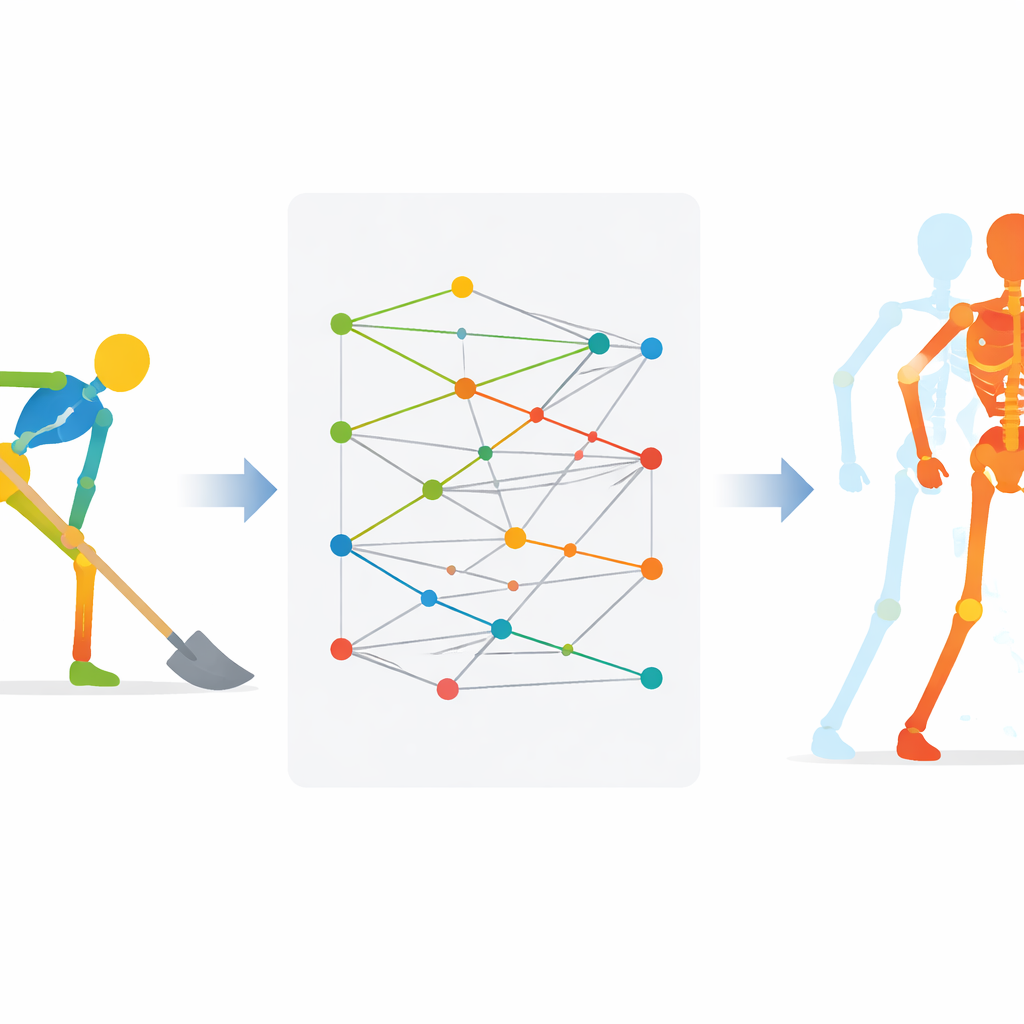
How the System Spots Mistakes
Once the model has learned these internal motion codes, it groups similar movements into clusters, each centered on a reference pattern that reflects one ideal action, such as a correct shovel swing. When a trainee performs a new motion, the system encodes it, finds the closest reference pattern, and then reconstructs what the trainee actually did. By comparing the trainee’s reconstruction with the ideal one joint by joint and instant by instant, the system can estimate how far each body part strayed from expert form. These differences can be translated into easy-to-understand feedback, such as which arm segment moved too fast or at the wrong angle.
Putting the Virtual Coach to the Test
The team recorded 509 real movements from eight archaeologists to train and evaluate the system. Their autoencoder, AEforGraph, reproduced motion data very accurately, keeping more than ninety percent of the original variation while greatly reducing its complexity. Compared with a well-known baseline model, it did a better job of capturing how movements unfold over time. When used to sort motions into three tool-related groups—trowel, pickaxe, and shovel—the semi-supervised clustering method correctly assigned over 97 percent of the samples. In live VR tests with all hardware running, the system usually returned feedback in about a second after each recorded action and almost always chose the right cluster for the performed movement.
Why This Matters Beyond Archaeology
From a layperson’s perspective, the main achievement is a working blueprint for a digital movement coach: virtual reality provides a safe, realistic setting; motion-capture sensors record detailed body behavior; and an intelligent model compares each attempt with expert examples to deliver targeted feedback in real time. Although the case study focuses on archaeologists, the framework is general. With suitable examples and motion data, the same approach could help refine tasks in medicine, rehabilitation, manufacturing, or sports, guiding people toward safer and more efficient movements without needing an instructor at their side for every repetition.
Citation: Pradisi, V., Marini, M.R., Castelli Gattinara Di Zubiena, F. et al. Spatio-temporal graph autoencoder for automated evaluation of human actions in 3D in immersive VR-based training for archaeologists. Sci Rep 16, 10568 (2026). https://doi.org/10.1038/s41598-026-46138-0
Keywords: virtual reality training, motion capture, archaeology, human movement analysis, graph neural networks