Clear Sky Science · de
Räumlich-zeitlicher Graph-Autoencoder zur automatisierten Bewertung menschlicher Aktionen in 3D in immersivem VR-Training für Archäologen
Feinmotorik üben, ohne das Labor zu verlassen
Viele Tätigkeiten erfordern präzise, sichere Körperbewegungen, doch echtes Üben kann riskant, teuer oder schwer wiederholbar sein. Diese Studie zeigt, wie Virtual-Reality- und Bewegungserfassungstechnologie mit künstlicher Intelligenz kombiniert werden können, um Archäologen beim Graben, Schaben und Heben in einer digitalen Ausgrabungsstätte zu coachen. Dieselben Konzepte könnten eines Tages Chirurgen, Fabrikarbeiter oder Sportler trainieren, indem Expertenbewegungen als Norm festgelegt werden, die jeder erlernen kann.
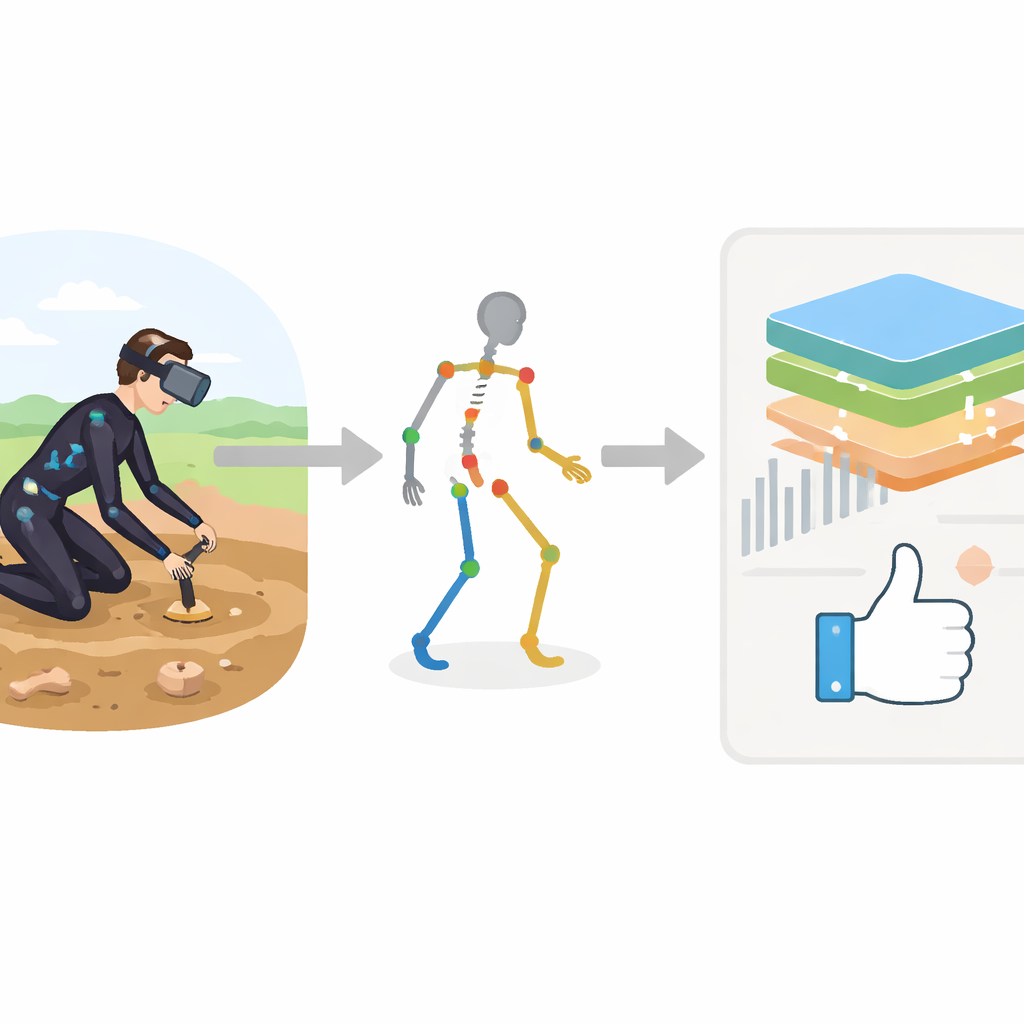
Eintauchen in eine virtuelle Ausgrabungsstätte
Die Forschenden entwickelten ein immersives Trainingssystem, das einen Archäologen mithilfe eines Meta Quest 3-Headsets in ein virtuelles Grabungsareal versetzt. Gleichzeitig zeichnet ein Xsens MVN Awinda-Bewegungsanzug mit 17 kleinen Sensoren jede Körperbewegung in drei Dimensionen nach. Anstatt die Bewegung nur abzuspielen, wandelt das System jede Aufnahme in eine strukturierte Beschreibung des Körpers um: Kopf, Rumpf, Arme und Beine werden zu Punkten in einem digitalen Skelett, jeweils mit detaillierten Messgrößen wie Geschwindigkeit, Beschleunigung und Gelenkwinkeln über die Zeit. Dieser reichhaltige Datenstrom dient als Rohmaterial für einen automatisierten Coach.
Dem Computer beibringen, wie „gute Bewegung“ aussieht
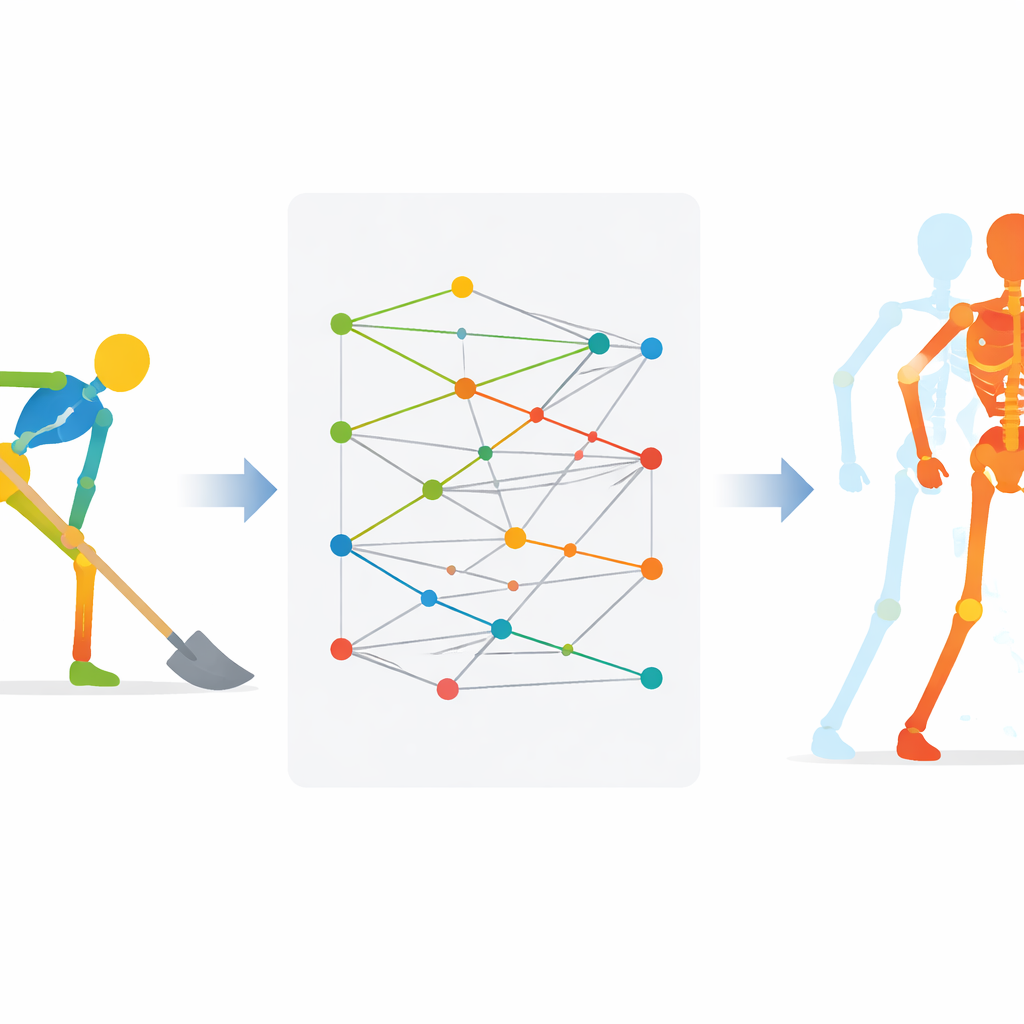
Um Expertenwissen in einen Trainingsstandard zu überführen, baten die Forschenden zunächst professionelle Archäologen, typische Aufgaben mit Kelle, Spitzhacke und Schaufel auszuführen. Diese Expertenbeispiele dienen als „ideale“ Bewegungen. Ein spezialisiertes KI-Modell mit dem Namen AEforGraph lernt dann, jede Bewegungssequenz in einen kompakten internen Code zu komprimieren, der bewahrt, wie Gelenke räumlich und zeitlich zusammenwirken. Das Modell legt mehr Gewicht auf die kritischsten Gelenke—beispielsweise Hand und Unterarm bei feiner Kellenarbeit—sodass Sicherheit und Präzision in Schlüsselbereichen stärker zählen als Hintergrundbewegung an anderen Stellen.
Wie das System Fehler erkennt
Sobald das Modell diese internen Bewegungscodes gelernt hat, gruppiert es ähnliche Bewegungen in Cluster, von denen jedes ein Referenzmuster repräsentiert, das eine ideale Aktion widerspiegelt, etwa einen korrekten Schaufelschwung. Wenn ein Lernender eine neue Bewegung ausführt, kodiert das System diese, findet das nächstgelegene Referenzmuster und rekonstruiert anschließend, was der Lernende tatsächlich getan hat. Durch den Vergleich der Rekonstruktion des Lernenden mit der idealen Version Gelenk für Gelenk und Moment für Moment kann das System abschätzen, wie weit sich einzelne Körperteile von der Expertenform entfernt haben. Diese Abweichungen lassen sich in leicht verständliches Feedback übersetzen, etwa welche Armmuskelsegmente zu schnell oder im falschen Winkel bewegt wurden.
Der virtuelle Coach im Praxistest
Das Team nahm 509 reale Bewegungen von acht Archäologen auf, um das System zu trainieren und zu evaluieren. Ihr Autoencoder AEforGraph reproduzierte die Bewegungsdaten sehr genau und bewahrte mehr als neunzig Prozent der ursprünglichen Variation, während die Komplexität stark reduziert wurde. Im Vergleich zu einem bekannten Basismodell gelang ihm eine bessere Erfassung des zeitlichen Ablaufs von Bewegungen. Bei der Einteilung der Bewegungen in drei werkzeugspezifische Gruppen—Kelle, Spitzhacke und Schaufel—ordnete die semi-supervised Cluster-Methode über 97 Prozent der Proben korrekt zu. In Live-VR-Tests mit laufender Hardware gab das System in der Regel etwa eine Sekunde nach jeder aufgezeichneten Aktion Feedback zurück und wählte fast immer das richtige Cluster für die ausgeführte Bewegung.
Warum das über die Archäologie hinaus wichtig ist
Für Laien ist die wichtigste Errungenschaft ein funktionsfähiger Bauplan für einen digitalen Bewegungscoach: Virtual Reality bietet ein sicheres, realistisches Umfeld; Bewegungssensoren zeichnen detailliertes Körperverhalten auf; und ein intelligentes Modell vergleicht jeden Versuch mit Expertenbeispielen, um gezieltes Feedback in Echtzeit zu liefern. Obwohl die Fallstudie auf Archäologen fokussiert ist, ist das Konzept allgemein anwendbar. Mit geeigneten Beispielen und Bewegungsdaten könnte derselbe Ansatz Aufgaben in Medizin, Rehabilitation, Fertigung oder Sport verfeinern und Menschen zu sichereren und effizienteren Bewegungen führen, ohne dass bei jeder Wiederholung ein Ausbilder anwesend sein muss.
Zitation: Pradisi, V., Marini, M.R., Castelli Gattinara Di Zubiena, F. et al. Spatio-temporal graph autoencoder for automated evaluation of human actions in 3D in immersive VR-based training for archaeologists. Sci Rep 16, 10568 (2026). https://doi.org/10.1038/s41598-026-46138-0
Schlüsselwörter: Virtual-Reality-Training, Bewegungserfassung, Archäologie, Analyse menschlicher Bewegung, Graphneuronale Netze