Clear Sky Science · fr
Une méthode de classification basée sur l’apprentissage automatique pour les défauts des SynRM
Pourquoi la santé des moteurs doit devenir plus intelligente
Les moteurs électriques font tourner en silence des usines, des trains et une multitude de machines, et lorsqu’ils lâchent sans prévenir, cela peut entraîner des arrêts coûteux voire des accidents dangereux. Un type de moteur récent, le moteur à réluctance synchrone, promet une grande efficacité sans recourir aux terres rares, ce qui le rend attractif pour un avenir bas carbone. Mais les mêmes caractéristiques qui rendent ces moteurs intéressants compliquent la lecture des signes précurseurs de panne. Cette étude montre comment un apprentissage automatique soigneusement conçu peut surveiller le « battement électrique » du moteur et détecter rapidement et de manière fiable plusieurs types de dommages, ouvrant la voie à des entraînements plus sûrs, plus verts et plus fiables.
Un nouveau type de moteur, un nouveau type de problème
Les moteurs à réluctance synchrone diffèrent à l’intérieur des moteurs d’induction ou à aimants : ils n’ont ni enroulements de rotor ni aimants permanents, et leurs chemins magnétiques sont fortement directionnels. Cette structure interne modifie la façon dont les défauts électriques se manifestent dans le courant du moteur. Les méthodes qui fonctionnent bien pour d’autres moteurs échouent souvent ici, surtout dans des usines réelles où les charges varient et où le bruit s’immisce dans les mesures. Jusqu’à présent, la plupart des travaux ont soit simulé des défauts uniques, testé un seul algorithme, soit négligé la manière dont une solution pourrait fonctionner en temps réel sur du matériel pratique. Les auteurs ont cherché à construire un banc d’essai complet, équitable et reproductible, spécifiquement centré sur ce type de moteur et sur des combinaisons de défauts, pas seulement un défaut à la fois.
Créer des défauts réels et virtuels pour apprendre
Pour apprendre aux ordinateurs à reconnaître les signes de panne, l’équipe a créé à la fois des dommages physiques et simulés. En laboratoire, ils ont utilisé un moteur de 2,2 kilowatts et introduit volontairement deux problèmes courants et dangereux : des spires court‑circuitées dans les enroulements du stator et des défauts sur la piste intérieure des roulements. Ils ont fait tourner le moteur à vide, à mi‑charge et à pleine charge, enregistrant à de nombreuses reprises les signaux de courant triphasé pour chaque condition afin d’assurer la reproductibilité. Un troisième type de défaut — un entrefer inégal entre rotor et stator, appelé excentricité — a été modélisé par des simulations électromagnétiques détaillées, puis « bruité » et mis à l’échelle de manière à ce que ses motifs de courant ressemblent à ceux mesurés en laboratoire. Tous les signaux, expérimentaux ou simulés, ont été traités de la même manière afin que les algorithmes d’apprentissage se concentrent sur les motifs physiques des défauts plutôt que sur des artefacts liés à la génération des données.
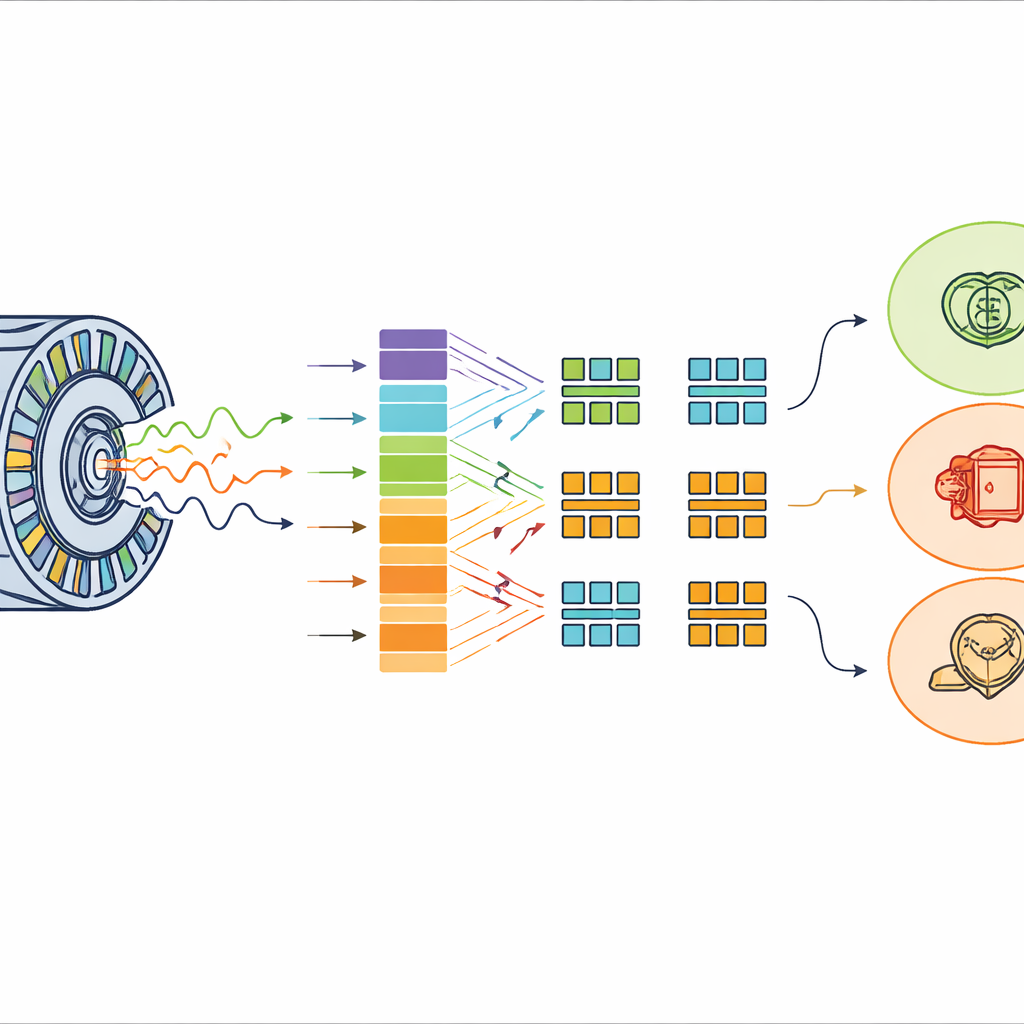
Écouter le courant dans le temps et en fréquence
Parce que le courant d’un moteur défectueux évolue dans le temps et sur une large gamme de fréquences, les auteurs ont utilisé un outil appelé transformée en ondelettes discrète. Plutôt que de produire un simple spectre, cette méthode décompose le courant en plusieurs bandes qui captent à la fois les ondulations lentes et basses fréquences et les pointes nettes à haute fréquence. À partir de chaque court segment de courant — d’environ un dixième de seconde — ils ont extrait un ensemble compact de 12 nombres décrivant la répartition de l’énergie et de l’aléa entre ces bandes. Ces nombres forment l’empreinte de l’état du moteur. En faisant glisser la fenêtre d’analyse sur de longues acquisitions et en équilibrant les échantillons, ils ont construit de grands jeux de données bien contrôlés avec 10 000 « empreintes » par classe, couvrant le fonctionnement sain et chaque scénario de défaut, seul ou en combinaison.
Tester équitablement des modèles d’apprentissage automatique
Munis de ce jeu de données, les chercheurs ont comparé huit méthodes d’apprentissage automatique populaires, des schémas linéaires simples à des ensembles sophistiqués d’arbres de décision. Ils ont suivi des règles strictes pour éviter les écueils courants : toutes les fenêtres d’une même série ont été conservées intégralement soit dans les ensembles d’entraînement soit dans ceux de test pour prévenir les fuites d’information, les paramètres ont été ajustés via des recherches en grille systématiques avec validation croisée, et les performances ont été évaluées par la précision, la précision positive et — surtout — le rappel, qui mesure la fréquence à laquelle les défauts réels sont correctement détectés. Pour les défauts uniques dans les enroulements et les roulements, les forêts aléatoires — un ensemble de nombreux arbres peu profonds — se sont distinguées, atteignant environ 99,98 % de précision sans défauts manqués. Pour l’excentricité, des méthodes de boosting telles qu’AdaBoost et XGBoost ont atteint une précision parfaite avec beaucoup moins de temps d’entraînement que les machines à vecteurs de support, qui présentaient des performances similaires mais se scalaient mal avec la taille des données.
De la précision en laboratoire à la protection en temps réel
Le test le plus exigeant était une tâche à 16 classes reflétant de nombreuses combinaisons possibles de défauts. Ici, une méthode d’ensemble plus récente appelée CatBoost a offert le meilleur compromis, identifiant correctement plus de 99,9 % des cas et maintenant les défauts non détectés exceptionnellement rares. Bien que ce modèle consomme plus de mémoire que d’autres, son temps de réponse restait de l’ordre de quelques dizaines de microsecondes — suffisamment rapide pour les normes de protection industrielles qui exigent le découplage des moteurs en millisecondes lorsqu’un problème survient. Dans l’ensemble des tests, l’étude montre que les ensembles d’arbres, choisis et ajustés avec soin, peuvent transformer des mesures de courant bruyantes en un système d’alerte précoce très fiable. En termes simples, le travail démontre qu’avec le bon type de données et de modèles, les fabricants peuvent surveiller ces moteurs efficaces en temps réel et détecter de petits problèmes avant qu’ils ne deviennent des pannes coûteuses ou dangereuses.
Citation: Rajini, V., Nagarajan, V.S., Gulbarga, M.I. et al. A machine learning-based classification method for SynRM faults. Sci Rep 16, 13790 (2026). https://doi.org/10.1038/s41598-026-42396-0
Mots-clés: moteur à réluctance synchrone, diagnostic de défaut, analyse du courant moteur, apprentissage automatique, surveillance d’état