Clear Sky Science · fr
Les modèles de réseaux neuronaux convolutionnels décrivent le sous-espace de codage des circuits locaux dans le cortex auditif
Comment les ordinateurs peuvent nous aider à entendre le monde
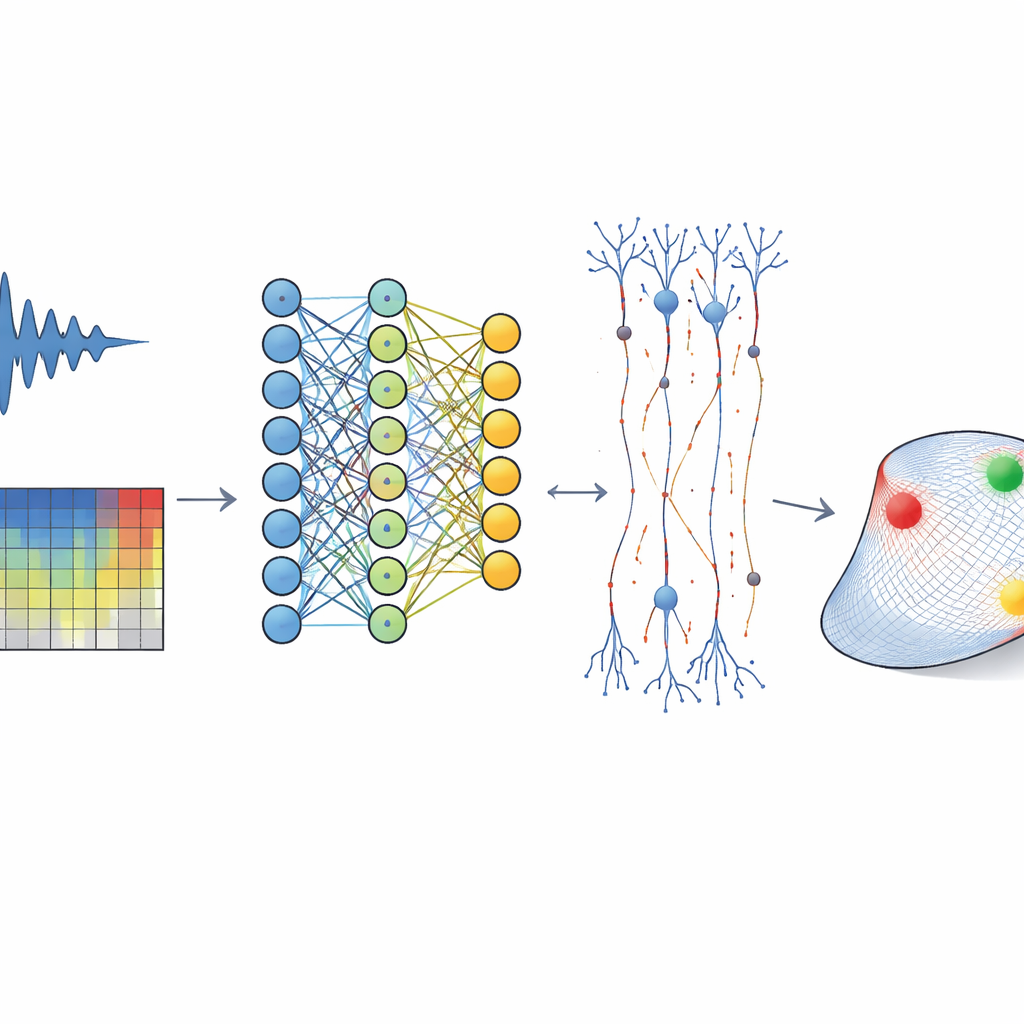
La vie quotidienne est pleine de sons qui se chevauchent : voix, musique, pas et circulation envahissent simultanément nos oreilles. Notre cerveau démêle cette cacophonie avec aisance, mais les mécanismes exacts utilisés par le cortex auditif restent flous. Cette étude montre comment des outils modernes d’apprentissage profond, similaires à ceux employés pour la reconnaissance vocale et d’images, peuvent être ouverts pour révéler les caractéristiques sonores qui intéressent les cellules nerveuses — et comment ces caractéristiques sont organisées dans de petits circuits locaux.
Des paysages sonores naturels à l’activité cérébrale
Les chercheurs ont enregistré l’activité électrique de milliers de neurones individuels du cortex auditif de jeunes furets éveillés pendant que les animaux écoutaient une vaste bibliothèque de sons naturels : extraits de parole, musique, bruits d’environnement et cris d’animaux. Plutôt que d’utiliser des tons simples, l’équipe a choisi ce régime sonore riche pour mieux refléter la complexité de l’audition quotidienne. Ils ont converti chaque son en spectrogramme, une représentation temps–fréquence montrant comment l’énergie se répartit selon les hauteurs au fil du temps, puis ont entraîné un réseau neuronal convolutionnel (CNN) pour prédire, milliseconde par milliseconde, comment chaque neurone allait s’activer. Comme dans d’autres modalités sensorielles, ce réseau profond surpassait les modèles linéaires classiques qui supposent que chaque neurone écoute via un seul « filtre » fixe.
Aplatir un réseau profond en un simple espace sonore
Les CNN performants sont souvent critiqués comme des boîtes noires : ils ajustent les données mais sont difficiles à interpréter. Pour résoudre cela, les auteurs ont développé une méthode pour « aplatir » le modèle profond en un espace sonore simple et de faible dimension pour chaque neurone. D’abord, ils ont calculé un champ récepteur dynamique à chaque instant en demandant comment une petite modification du spectrogramme d’entrée modifierait la sortie du CNN pour ce neurone. Cela a produit une grande collection de filtres instantanés capturant la dépendance de la prédiction du modèle aux sons récents. Ils ont ensuite utilisé une technique statistique pour résumer ces nombreux filtres en une poignée de composantes principales — typiquement seulement 3 à 13 — qui définissent ensemble le sous-espace d’accordage d’un neurone : le petit ensemble de motifs sonores qui influencent réellement son activité.

Lire des réponses non linéaires dans cet espace partagé
Une fois les sons projetés dans le sous-espace d’accordage d’un neurone, l’équipe a mesuré comment le taux de décharge variait selon les positions dans cet espace réduit, formant ce qu’ils appellent des champs récepteurs de sous-espace. Ces surfaces étaient souvent courbées et multimodales, révélant un riche comportement non linéaire que les modèles simples manquent : certains neurones répondaient fortement à plusieurs motifs sonores distincts, d’autres à des déviations positives et négatives le long d’une dimension, et beaucoup présentaient des poches de sensibilité nettes entourées de zones de suppression. Crucialement, un nouveau modèle utilisant uniquement la projection dans le sous-espace et une lecture non linéaire modeste prédisait l’activité neuronale presque aussi bien que le CNN original, capturant plus de 95 % de sa variance expliquée. Cela montre que la complexité du modèle profond peut être distillée en une description compacte et interprétable de ce que chaque neurone « écoute ».
Comment les voisins partagent et répartissent le travail
Parce que les enregistrements couvraient de nombreux neurones le long d’une même colonne corticale, les auteurs ont pu examiner comment les populations locales se partagent la tâche de coder les sons. Ils ont constaté que les neurones d’un même site occupent majoritairement le même sous-espace d’accordage : leurs motifs sonores préférés proviennent d’un ensemble commun de caractéristiques de faible dimension, probablement en raison d’entrées partagées provenant de stades antérieurs. Pourtant, au sein de cet espace partagé, la région d’activité élevée de chaque neurone occupe seulement une petite parcelle, et ces parcelles se chevauchent au plus comme si elles étaient dispersées au hasard. Autrement dit, les neurones proches écoutent des types de sons similaires mais répondent fortement à des combinaisons spécifiques différentes, formant une mosaïque parcimonieuse de l’espace. Cette organisation explique pourquoi des cellules voisines réagissent souvent très différemment au même son naturel, malgré des préférences larges communes comme la fréquence optimale.
Différents types cellulaires, rôles différents
L’équipe a également exploité des différences de forme d’impulsion et de profondeur d’enregistrement pour séparer des neurones putatifs excitateurs et inhibiteurs et pour les affecter à des couches corticales. Les cellules inhibitrices, identifiées par leurs pointes étroites, avaient tendance à posséder des champs récepteurs de sous-espace plus larges, c’est‑à‑dire qu’elles répondent sur des régions plus étendues de l’espace sonore partagé. Leur accordage non linéaire formait davantage des formes en cuvette où de fortes réponses apparaissent pour de grandes fluctuations dans l’une ou l’autre direction le long d’une dimension. Les cellules excitatrices, en revanche, présentaient plus souvent un accordage en pics, de type colline, confiné à une plage d’entrées plus étroite. Ensemble, ces motifs soutiennent l’idée que des neurones inhibiteurs à large tuning aident à sculpter un code parcimonieux et sélectif parmi leurs voisins excitateurs plus finement accordés, l’équilibre de ces effets variant selon les couches corticales.
Pourquoi ce cadre est important
Ce travail démontre que des réseaux neuronaux profonds entraînés directement sur des données cérébrales peuvent être traduits en cartes intuitives de ce que codent les neurones sensoriels et de la manière dont les circuits locaux sont organisés. En montrant qu’un petit ensemble de caractéristiques sonores partagées sous-tend les réponses de nombreux neurones voisins, tandis que les cellules individuelles se taillent des niches distinctes dans cet espace, l’étude fournit un cadre concret pour penser le codage parcimonieux, le contrôle du gain et l’invariance dans le cortex auditif. Plus généralement, la même stratégie d’« aplatissement » peut être appliquée à d’autres régions cérébrales, transformant des modèles d’apprentissage profond puissants mais opaques en hypothèses claires sur les calculs que réalisent les circuits neuronaux naturels.
Citation: Wingert, J.C., Parida, S., Norman-Haignere, S.V. et al. Convolutional neural network models describe the encoding subspace of local circuits in auditory cortex. Nat Neurosci 29, 876–887 (2026). https://doi.org/10.1038/s41593-026-02216-0
Mots-clés: cortex auditif, réseaux neuronaux convolutionnels, codage neuronal, codage parcimonieux, sous-espace sensoriel