Clear Sky Science · es
Modelos de redes neuronales convolucionales describen el subespacio de codificación de circuitos locales en la corteza auditiva
Cómo las máquinas pueden ayudarnos a escuchar el mundo
La vida cotidiana está llena de sonidos superpuestos: voces, música, pasos y tráfico invaden nuestros oídos a la vez. Nuestro cerebro desconjunta este enredo con aparente facilidad, pero los mecanismos exactos que utiliza la corteza auditiva siguen siendo confusos. Este estudio muestra cómo herramientas modernas de aprendizaje profundo, similares a las empleadas en el reconocimiento de voz e imágenes, pueden analizarse para revelar las características sonoras que interesan a las neuronas —y cómo esas características se organizan en pequeños circuitos locales.
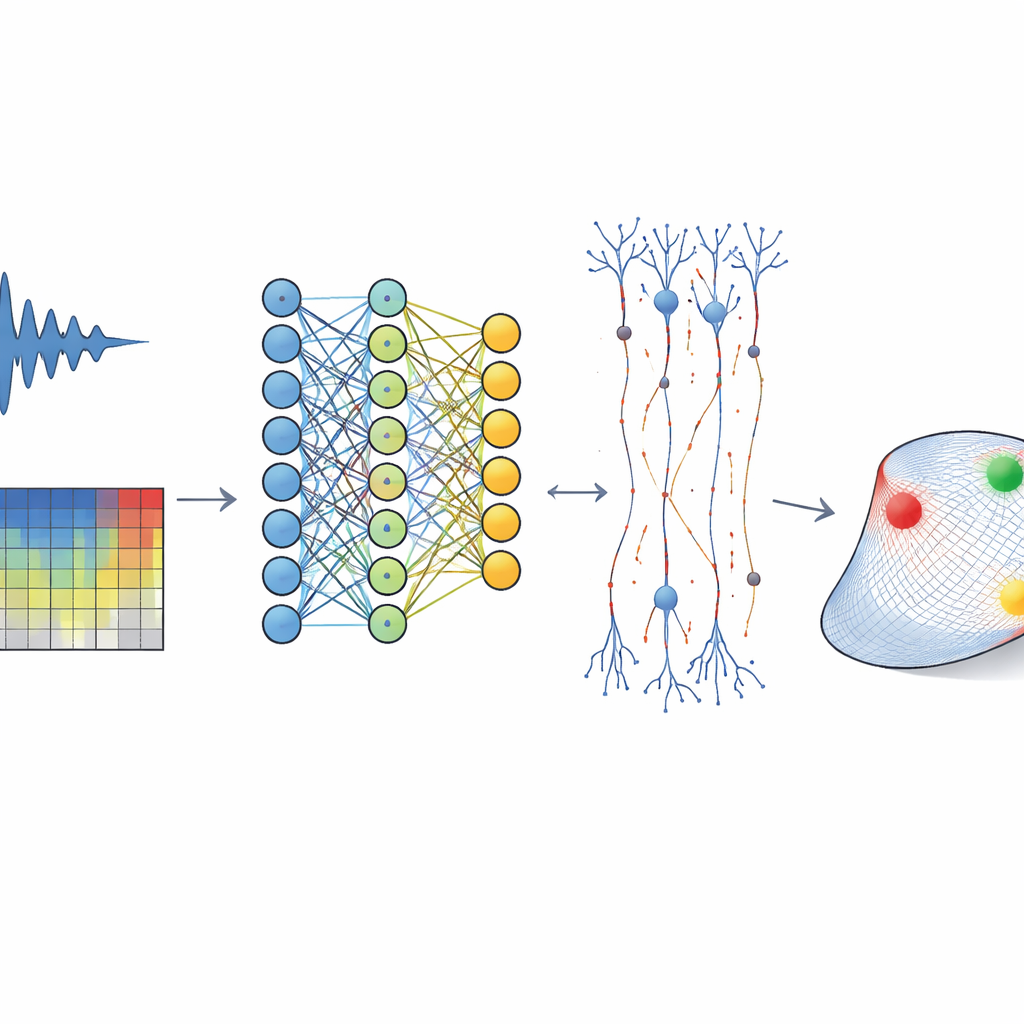
De paisajes sonoros naturales a actividad cerebral
Los investigadores registraron la actividad eléctrica de miles de neuronas individuales en la corteza auditiva de hurones despiertos mientras los animales escuchaban una vasta biblioteca de sonidos naturales: fragmentos de habla, música, ruidos ambientales y llamados animales. En lugar de usar tonos simples, el equipo eligió esta rica dieta sonora para aproximarse mejor a la complejidad de la audición cotidiana. Convirtieron cada sonido en un espectrograma, una imagen tiempo‑frecuencia de cómo se distribuye la energía entre las frecuencias a lo largo del tiempo, y entrenaron una red neuronal convolucional (CNN) para predecir, milisegundo a milisegundo, cómo dispararía cada neurona. Como ocurre en otras áreas sensoriales, esta red profunda superó a los modelos lineales clásicos que asumen que cada neurona escucha mediante un único “filtro” fijo.
Aplanar una red profunda hacia un espacio sonoro simple
Las CNNs de alto rendimiento suelen criticarse como cajas negras: encajan los datos pero son difíciles de interpretar. Para abordar esto, los autores desarrollaron un método para “aplanar” el modelo profundo en un espacio sonoro simple y de baja dimensión para cada neurona. Primero calcularon un campo receptivo dinámico en cada instante preguntando cómo cambiaría la salida de la CNN para esa neurona ante una pequeña variación del espectrograma de entrada. Esto produjo una gran colección de filtros momento a momento que capturan cómo la predicción del modelo depende del sonido reciente. Luego emplearon una técnica estadística para resumir esos múltiples filtros en unas pocas componentes principales—típicamente entre 3 y 13—que en conjunto definen el subespacio de afinidad de la neurona: el pequeño conjunto de patrones sonoros que realmente influyen en su actividad.

Leer respuestas no lineales en este espacio compartido
Una vez que los sonidos se proyectaron en el subespacio de afinidad de una neurona, el equipo midió cómo variaba la tasa de disparo según la posición en este espacio reducido, formando lo que denominaron campos receptivos de subespacio. Estas superficies a menudo eran curvas y con múltiples picos, revelando un comportamiento no lineal rico que los modelos simples pasan por alto: algunas neuronas respondían con fuerza a varios patrones sonoros distintos, otras a desviaciones tanto positivas como negativas a lo largo de una dimensión, y muchas mostraban bolsillos de sensibilidad aguda rodeados por zonas de supresión. De forma crucial, un nuevo modelo que usaba únicamente la proyección al subespacio más una lectura no lineal modesta predijo la actividad neuronal casi tan bien como la CNN original, capturando más del 95 % de la varianza explicada. Esto muestra que la complejidad del modelo profundo puede destilarse en una descripción compacta e interpretable de lo que cada neurona “escucha”.
Cómo los vecinos comparten y dividen el trabajo
Puesto que los registros abarcaron muchas neuronas a lo largo de la misma columna cortical, los autores pudieron preguntar cómo las poblaciones locales comparten la tarea de codificar el sonido. Encontraron que las neuronas en un mismo sitio habitan en gran medida el mismo subespacio de afinidad: sus patrones sonoros preferidos provienen de un conjunto común de características de baja dimensión, probablemente reflejando entradas compartidas de etapas anteriores. Sin embargo, dentro de ese espacio compartido, la región de alta actividad de cada neurona ocupa solo un parche pequeño, y estos parches se solapan a lo sumo tanto como lo harían si estuvieran distribuidos al azar. En otras palabras, las neuronas cercanas escuchan tipos similares de sonidos pero responden con fuerza a combinaciones específicas distintas, formando un mosaico disperso del espacio. Esta organización explica por qué las células vecinas a menudo disparan de manera muy diferente ante el mismo sonido natural, a pesar de compartir preferencias generales como la frecuencia preferida.
Diferentes tipos celulares, distintos roles
El equipo también aprovechó diferencias en la forma de los picos y la profundidad de registro para separar neuronas putativas excitadoras e inhibitorias y asignarlas a capas corticales. Las células inhibitorias, identificadas por sus picos estrechos, tendieron a tener campos receptivos de subespacio más amplios, lo que significa que responden a regiones mayores del espacio sonoro compartido. Su afinidad no lineal era más proclive a formar formas en cuenco en las que las respuestas fuertes ocurren por grandes fluctuaciones en cualquiera de las direcciones a lo largo de una dimensión. Las células excitadoras, en cambio, mostraron con más frecuencia afinaciones con picos, en forma de colinas, confinadas a un rango más estrecho de entradas. En conjunto, estos patrones respaldan un panorama en el que las neuronas inhibitorias de afinación amplia ayudan a esculpir un código disperso y selectivo entre sus vecinas excitadoras de afinación más estrecha, con el equilibrio de estos efectos cambiando entre capas corticales.
Por qué importa este marco
Este trabajo demuestra que las redes neuronales profundas entrenadas directamente con datos cerebrales pueden traducirse en mapas intuitivos de lo que codifican las neuronas sensoriales y de cómo se organizan los circuitos locales. Al mostrar que un pequeño conjunto de características sonoras compartidas subyace a las respuestas de muchas neuronas cercanas, mientras que las células individuales se reservan nichos distintos dentro de ese espacio, el estudio proporciona un marco concreto para pensar sobre la codificación dispersa, el control de ganancia y la invariancia en la corteza auditiva. Más ampliamente, la misma estrategia de “aplanamiento” puede aplicarse en otras áreas del cerebro, convirtiendo modelos profundos poderosos pero opacos en hipótesis claras sobre los cálculos que realizan los circuitos neuronales naturales.
Cita: Wingert, J.C., Parida, S., Norman-Haignere, S.V. et al. Convolutional neural network models describe the encoding subspace of local circuits in auditory cortex. Nat Neurosci 29, 876–887 (2026). https://doi.org/10.1038/s41593-026-02216-0
Palabras clave: corteza auditiva, redes neuronales convolucionales, codificación neuronal, codificación dispersa, subespacio sensorial