Clear Sky Science · fr
L’apprentissage automatique appliqué à la détection monocellulaire pour une quantification sans étalon des acides per- et polyfluoroalkyles carboxyliques
Pourquoi cela compte pour la sécurité de l’eau au quotidien
Des produits chimiques industriels invisibles, connus sous le nom de PFAS, ont contaminé les rivières, l’eau potable et même notre sang. Parmi eux, les acides per- et polyfluoroalkyles carboxyliques (PFCA) sont particulièrement préoccupants, mais ils sont extrêmement difficiles à mesurer avec précision car des étalons de référence n’existent que pour une fraction infime des milliers de PFAS utilisés. Cette étude présente une nouvelle méthode pour « compter » les molécules de PFCA une par une lorsqu’elles traversent un minuscule trou biologique, en utilisant l’apprentissage automatique pour reconnaître leurs empreintes électriques — sans qu’il soit nécessaire d’avoir un étalon de laboratoire correspondant pour chaque composé.
Des produits chimiques cachés dans une famille complexe
Les PFAS forment une vaste famille de produits fluorés utilisés dans des articles allant des poêles antiadhésives aux mousses anti-incendie. Beaucoup ne diffèrent que par quelques atomes, mais ces légères modifications structurelles peuvent modifier considérablement leur comportement dans l’environnement, leur bioaccumulation ou leur impact sur la santé. Les techniques traditionnelles, comme la chromatographie liquide ou gazeuse couplée à la spectrométrie de masse, peuvent détecter de nombreux PFAS avec une grande sensibilité, mais elles exigent en général un étalon pur pour chaque composé afin de l’identifier et de le quantifier de manière fiable. À ce jour, des étalons commerciaux existent pour un peu plus d’une centaine de PFAS — moins d’un pour cent de ceux connus — laissant les régulateurs et les chercheurs largement dans l’incertitude pour le reste.
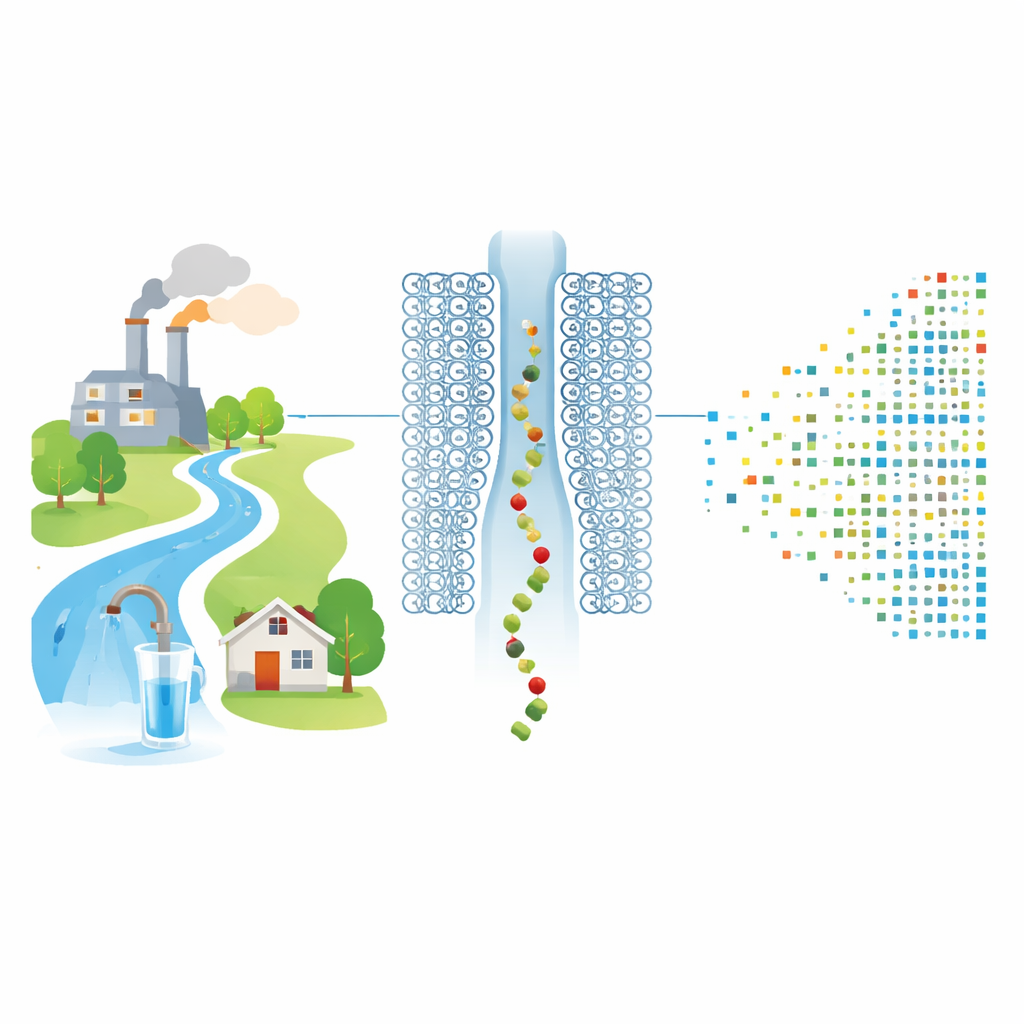
Compter des molécules individuelles au travers d’une porte minuscule
Les chercheurs comblent cette lacune en utilisant un nanopore protéique : une molécule en forme de beignet qui forme un unique trou dans une membrane lipidique. Lorsqu’une tension est appliquée, des ions traversent le pore et créent un courant électrique stable. L’équipe rattache chimiquement des molécules individuelles de PFCA à de courtes « séquences leader » peptidiques chargées positivement qui sont attirées dans le nanopore comme des perles sur un fil. À chaque fois qu’une paire PFCA–peptide entre et occupe le pore, elle bloque partiellement le flux d’ions, provoquant une brève baisse du courant dont l’amplitude et la durée dépendent de la taille et de la forme de la molécule dans le pore.
Transformer les signaux du pore en une règle de mesure moléculaire
Une percée clé de ce travail est que ces baisses de courant se comportent comme une règle de mesure précise. En combinant expériences et simulations moléculaires, les auteurs montrent que, pour une série de PFCA jusqu’à 14 carbones, la profondeur du blocage de courant augmente de manière presque parfaitement linéaire avec le volume de la molécule. Autrement dit, une fois le nanopore et le peptide choisis, le volume seul prédit l’intensité du blocage du courant. Cela a permis à l’équipe de prévoir la signature électrique d’autres PFCA plus complexes — comme ceux présentant des substitutions hydrogène ou chlore, des chaînes latérales ou des cycles aromatiques — et de confirmer expérimentalement que les prédictions correspondaient à la réalité dans la très faible marge d’erreur de mesure.
Apprentissage automatique pour repérer des polluants qui se ressemblent
Parce que de nombreux cousins des PFCA sont si proches en taille que leurs blocages se chevauchent, les scientifiques ont exploité la richesse complète du signal du nanopore. Ils ont extrait des dizaines de caractéristiques de chaque événement, incluant sa durée, son niveau de bruit, et la façon dont sa forme change lorsque le signal est filtré numériquement à différentes fréquences. En entraînant des modèles d’apprentissage automatique sur ces empreintes multidimensionnelles, ils ont atteint une précision d’identification quasi parfaite (environ 99,9 %) pour 13 types de PFCA, y compris des isomères très proches. En sélectionnant soigneusement les 21 caractéristiques les plus informatives, ils ont réduit la complexité du modèle tout en améliorant effectivement les performances, même lorsque la cible était enfouie dans des PFCA interférents à une concentration 100 fois plus élevée.
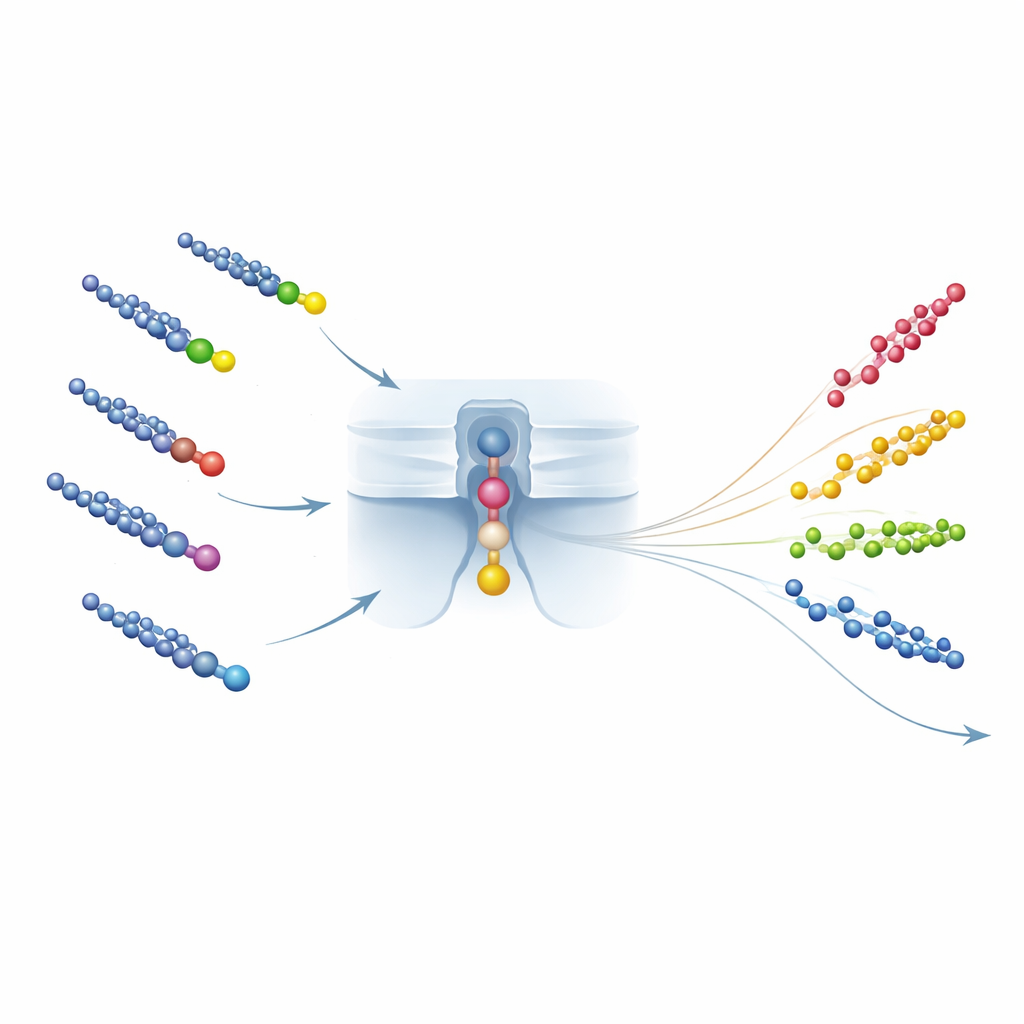
Des comptes monocellulaires aux tests d’eau en conditions réelles
Au-delà de l’identification, la méthode doit aussi mesurer la quantité de chaque PFCA présente. Ici, l’équipe exploite la vitesse à laquelle les paires PFCA–peptide sont capturées par le nanopore : le temps moyen entre les événements diminue lorsque la concentration augmente. Un design de peptide astucieux fait en sorte que ce taux de capture soit déterminé principalement par la charge du peptide et le paysage électrique du pore, et beaucoup moins par la nature du PFCA fixé. Cela signifie qu’une seule courbe d’étalonnage — reliant la fréquence des événements à la concentration — peut être partagée entre de nombreux PFCA, permettant ce que les auteurs appellent « une courbe d’étalonnage pour tous ». Ils valident cette universalité dans des mélanges et des échantillons complexes comme l’eau du robinet et le sérum, montrant des comptages précis même en présence de nombreux autres produits chimiques, et atteignant des limites de détection pour le PFCA très court trifluoroacétique comparables aux meilleures méthodes par spectrométrie de masse.
Une nouvelle voie pour suivre les PFAS sans étalons personnalisés
Ensemble, ces travaux dessinent une voie pour surveiller une large portion des polluants PFCA sans nécessiter d’étalon sur mesure pour chacun. Un nanopore et une sonde peptidique soigneusement conçus créent un lien linéaire simple entre la taille moléculaire et le signal, tandis que l’apprentissage automatique extrait des caractéristiques subtiles du signal pour distinguer même des isomères presque identiques. En ajustant plus avant les « barrières » d’entrée et de sortie du pore, les auteurs montrent, par expériences et simulations, comment la même stratégie pourrait être étendue aux PFCA à chaîne plus longue et potentiellement à l’univers plus large des PFAS. Pour le grand public, cela signifie une nouvelle voie prometteuse pour détecter et mesurer des produits chimiques qui sont demeurés largement invisibles dans notre eau et notre environnement.
Citation: Zuo, J., Li, HS., Tang, W. et al. Machine learning assisted single-molecule sensing towards standard-free quantification of per- and polyfluoroalkyl carboxylic acids. Nat Commun 17, 3923 (2026). https://doi.org/10.1038/s41467-026-70718-3
Mots-clés: PFAS, détection par nanopore, détection monocellulaire, apprentissage automatique, polluants de l’eau