Clear Sky Science · es
Detección de DCL a partir de pruebas de dibujo manuscrito usando un transformador de visión residual
Por qué dibujos sencillos pueden revelar problemas de memoria ocultos
Imagine que un médico pudiera detectar señales tempranas de demencia simplemente observando cómo dibuja usted un reloj, un cubo o una serie de círculos conectados. Estos bocetos rápidos ya se usan en las clínicas, pero se puntúan a mano y dependen en gran medida del criterio del profesional. Este artículo muestra cómo un sistema de inteligencia artificial (IA) llamado ResViT puede “leer” estos dibujos automáticamente, convirtiendo los trazos en una alerta temprana de deterioro cognitivo leve (DCL), una etapa intermedia entre el envejecimiento normal y la demencia en la que el tratamiento y la planificación aún pueden marcar una gran diferencia.
De las pruebas en papel a la detección inteligente
El deterioro cognitivo leve suele manifestarse primero en tareas cotidianas que requieren planificación, atención y sentido del espacio, precisamente lo que las pruebas de dibujo están diseñadas para evaluar. Los médicos suelen pedir a los pacientes que dibujen un reloj que marque una hora concreta, que copien un cubo tridimensional o que conecten números y letras dispersos en secuencia. Antes, cada dibujo debía calificarse a simple vista, lo que es lento y puede variar entre clínicos. Los autores se propusieron construir un sistema más objetivo que analice los tres dibujos a la vez, usando un ordenador para detectar patrones que incluso ojos entrenados podrían pasar por alto. Su objetivo no es sustituir a los médicos, sino ofrecerles una segunda opinión rápida y consistente.
Combinando dos maneras de ver: los detalles y la visión global
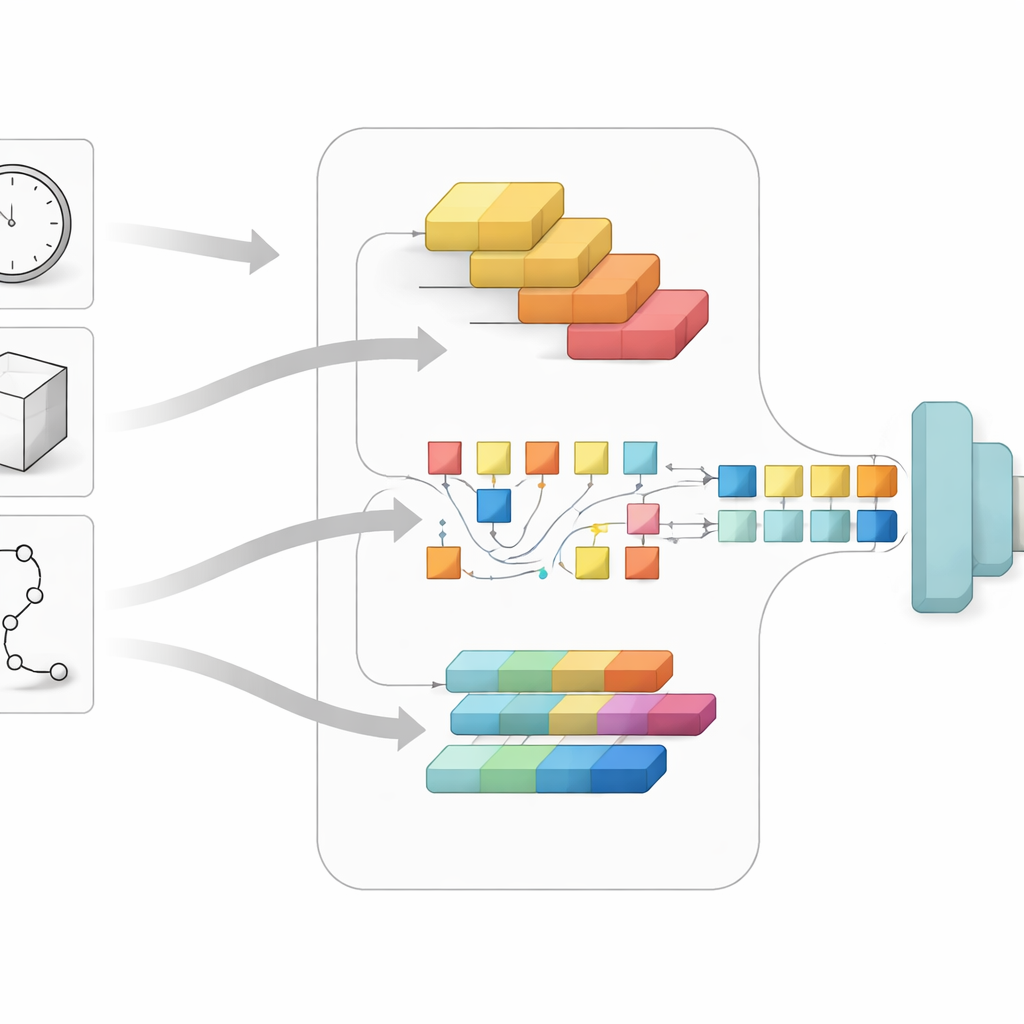
El núcleo del estudio es un modelo híbrido de IA llamado ResViT, diseñado para combinar dos estilos complementarios de análisis de imágenes. Una parte, basada en una técnica conocida como ResNet, es especialmente buena detectando detalles finos como bordes, esquinas y pequeñas distorsiones en las líneas de un dibujo. La otra parte, un Vision Transformer, sobresale en comprender la disposición general: cómo encajan las piezas de un reloj, un cubo o un recorrido en la página. En lugar de alimentar los dibujos a través de estos componentes de forma secuencial, el sistema los ejecuta en paralelo y luego fusiona las dos corrientes de información en una imagen única y más rica del estado cognitivo de la persona.
Cómo aprende el sistema a partir de dibujos reales de pacientes
Para probar su idea, los investigadores usaron una colección pública de dibujos de 918 personas, cada una de las cuales había completado las tareas del reloj, el cubo y el trazado de caminos. El estado cognitivo de cada persona ya había sido evaluado con una prueba clínica estándar, proporcionando una etiqueta de referencia de “sano” o “DCL”. El equipo convirtió los dibujos en imágenes en escala de grises, las redimensionó y aplicó ajustes simples como rotaciones y cambios de brillo para hacer el modelo más robusto. Durante el entrenamiento, ResViT comparó repetidamente sus predicciones con las etiquetas conocidas y ajustó sus parámetros internos, con salvaguardas como parada temprana y dropout para evitar memorizar los datos de entrenamiento en lugar de aprender reglas generales.
Qué tan bien funciona y qué revela
Al evaluarlo con personas que no había visto antes, ResViT distinguió correctamente entre individuos sanos y con DCL en aproximadamente tres cuartas partes de los casos, con una precisión del 74,09% y una puntuación F1 equilibrada alrededor de 0,67. Esto superó a varias alternativas sólidas, incluidas versiones que usaban solo la parte ResNet, solo el Vision Transformer o otra red popular llamada EfficientNet. El enfoque híbrido, con aproximadamente un tercio de los parámetros internos de un transformador grande independiente, demostró ser especialmente bueno equilibrando la sensibilidad a la enfermedad con la evitación de falsas alarmas. Mediante visualizaciones tipo mapa de calor, los autores también mostraron que el modelo tiende a centrarse en regiones clínicamente significativas —como los dígitos del reloj, los bordes del cubo y los puntos de ramificación en los trazados—, lo que sugiere que presta atención a señales parecidas a las de los expertos humanos.
Límites actuales y posibilidades futuras
Los autores subrayan que su sistema aún no está listo para ser una herramienta de cribado universal. El conjunto de datos es de tamaño moderado, está sesgado hacia adultos mayores y carece de información de contexto importante como el nivel educativo y las diferencias culturales, factores que pueden influir en cómo dibuja la gente. El modelo también puede exigir mucha capacidad computacional para dispositivos de baja potencia. Aun así, dado que ResViT puede adaptarse con relativamente pocos ejemplos nuevos, podría ampliarse a otros trastornos cognitivos o nuevas tareas de dibujo a medida que se disponga de más datos. Integrar conjuntos de datos más grandes y diversos, y crear versiones más ligeras del modelo, serán pasos cruciales hacia su uso cotidiano.
Qué significa esto para pacientes y familias
En términos sencillos, este trabajo demuestra que una IA bien diseñada puede convertir bocetos simples en papel en una herramienta práctica para detectar signos tempranos de problemas de memoria y pensamiento. Aunque una tasa de precisión del 74% no es perfecta, resulta prometedora como primera línea de defensa: barata, rápida y fácil de repetir con el tiempo. En el futuro, un dibujo escaneado en la clínica, o incluso en una tableta en casa, podría señalar discretamente cambios sutiles mucho antes de que sean evidentes en la vida diaria, dando a médicos y familias más tiempo para actuar. En lugar de reemplazar el juicio humano, sistemas como ResViT podrían hacerlo más consistente y oportuno, acercando ayuda temprana a las personas en riesgo de demencia.
Cita: Sirshar, M., Matloob, I., Tayyabah, A. et al. MCI detection from handwritten drawing test using residual vision transformer. Sci Rep 16, 10334 (2026). https://doi.org/10.1038/s41598-026-40716-y
Palabras clave: deterioro cognitivo leve, pruebas de dibujo, aprendizaje profundo, vision transformer, detección temprana de demencia