Clear Sky Science · es
La evaluación por verosimilitud Usmile ofrece una valoración robusta sin umbral de modelos de clasificación binaria para conjuntos de datos balanceados e imbalanzados
Por qué importan mejores comprobaciones de modelo para decisiones cotidianas
Desde pruebas médicas hasta la evaluación crediticia, los ordenadores suelen responder preguntas de sí o no: ¿Tiene este paciente enfermedad cardíaca? ¿Será fraudulenta esta transacción? Sin embargo, las herramientas que usamos para juzgar la calidad de estos modelos pueden inducir a error, sobre todo cuando lo que buscamos es raro. Este artículo presenta una nueva forma de evaluar esos modelos que observa por separado cómo detectan los casos raros importantes y cómo evitan falsas alarmas, ofreciendo una imagen más clara para decisiones de alto impacto.
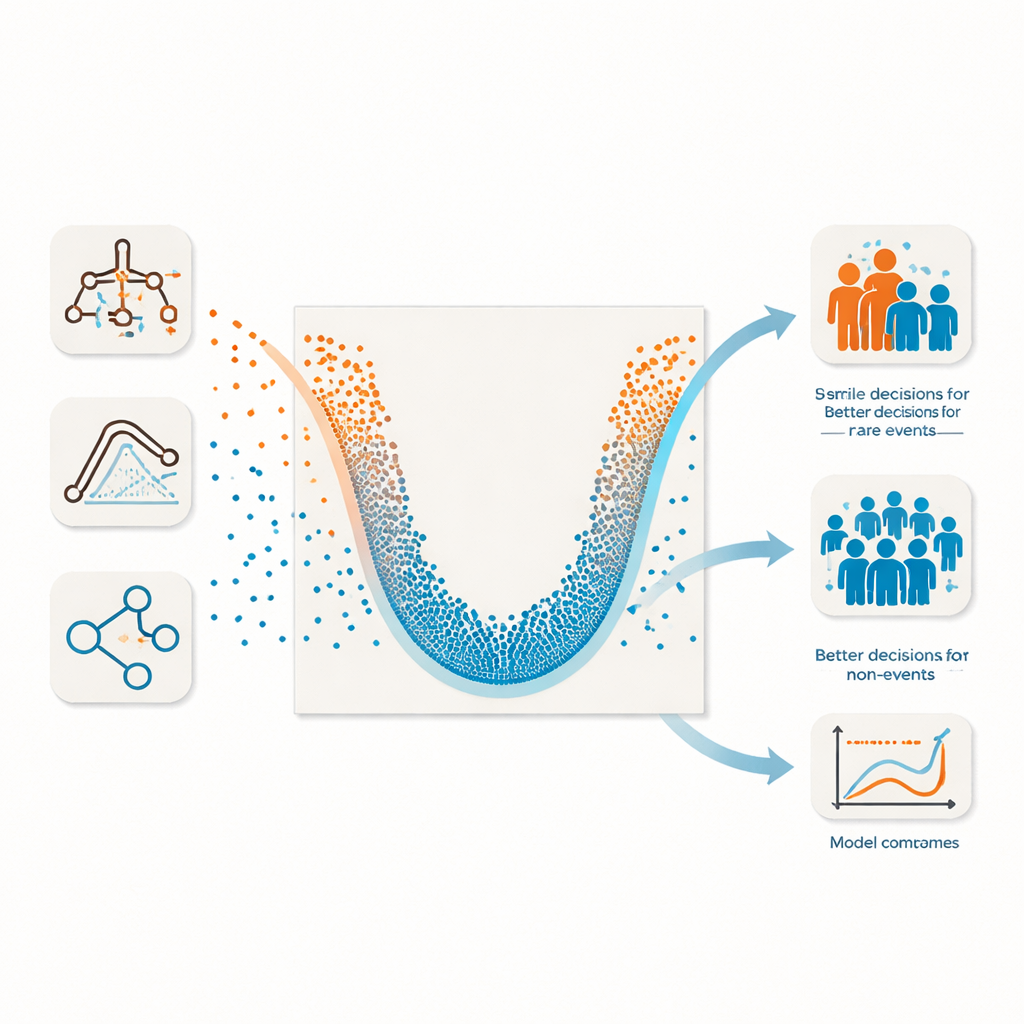
Límites de las calificaciones actuales de un solo número
La mayoría de las “calificaciones” actuales de modelos, como la popular curva ROC y su valor resumen, el área bajo la curva, reducen el rendimiento a un único número. Ese número mezcla el éxito en las personas que realmente tienen la condición (eventos) y en las que no la tienen (no‑eventos). En muchos problemas reales, como el diagnóstico médico o la detección de fraude, el grupo raro es precisamente el que más nos importa, y sus errores son mucho más costosos que los del grupo común. Con un fuerte desequilibrio—cuando hay muchos más no‑eventos que eventos—las medidas tradicionales pueden sugerir que un modelo funciona muy bien aunque rinda mal para los casos raros y críticos.
Una nueva visión «en forma de sonrisa» de la fortaleza del modelo
Los autores amplían su idea previa de visualización en forma de U hasta convertirla en un método completo llamado Evaluación por Verosimilitud U‑smile. En su núcleo está una nueva puntuación, la razón de verosimilitud relativa, que compara cuánto más probable son los datos bajo un modelo dado que bajo un modelo de referencia simple sin información útil. Esta puntuación es, por naturaleza, libre de umbral: usa las probabilidades predichas crudas en lugar de obligar al usuario a elegir un punto de corte. Crucialmente, se descompone en piezas separadas para los grupos de eventos y no‑eventos. En una gráfica en forma de U, las mejoras para cada grupo se muestran con puntos coloreados: una «sonrisa» profunda y simétrica significa que el modelo ayuda a ambos grupos; una forma desigual revela cuando solo un grupo se beneficia. El tamaño del punto refleja cuántos individuos están afectados, y el estilo de línea indica si la mejora es estadísticamente fiable.
Cómo se comporta el método en datos balanceados y sesgados
Para probar su enfoque, los investigadores crearon varios conjuntos de datos sintéticos que imitan distintos retos del mundo real: señales débiles y fuertes, así como situaciones fuertemente desbalanceadas donde solo uno de cada diez casos es un evento. También analizaron un conocido conjunto de datos sobre enfermedad cardíaca. Para cada escenario construyeron modelos paso a paso, añadiendo un predictor a la vez usando reglas tradicionales basadas en ROC o los nuevos criterios U‑smile. En situaciones balanceadas, todos los métodos eligieron predictores similares y alcanzaron un rendimiento casi idéntico, lo que sugiere que U‑smile es al menos tan bueno como las prácticas existentes cuando los datos están bien comportados. Las diferencias reales surgieron bajo el desequilibrio: allí, la selección guiada por U‑smile mejoró la detección de la clase minoritaria hasta en un 16% en el área precisión‑recuperación y un 21% en la puntuación F1 en comparación con la selección guiada por ROC, manteniendo al mismo tiempo un rendimiento sólido para la clase mayoritaria.

Ver lo que realmente aporta cada predictor
Dado que las gráficas U‑smile pueden trazarse tras cada paso de modelado, sirven también como un cuaderno visual de cómo crece un modelo. En los ejemplos desbalanceados, los predictores iniciales mejoraron principalmente el reconocimiento de casos evento, dando una sonrisa sesgada. Predictores posteriores restauraron el equilibrio, profundizando y simetrizando la curva. Versiones separadas del método pueden favorecer deliberadamente eventos o no‑eventos, permitiendo a los usuarios ajustar los modelos a objetivos específicos—por ejemplo, maximizar la detección de una enfermedad rara mientras otra versión enfatiza evitar alarmas innecesarias. Los autores también aplicaron el método a modelos de bosque aleatorio, que funcionan de forma muy distinta a la regresión logística clásica, y encontraron que los mismos patrones en forma de U seguían aportando ideas claras, mostrando que el enfoque funciona en muchos tipos de algoritmos.
Qué significa esto para decisiones de riesgo en el mundo real
En términos simples, el estudio ofrece una forma más clara y honesta de preguntar: “¿A quién está ayudando realmente este modelo?” En lugar de una única puntuación halagadora, la Evaluación por Verosimilitud U‑smile muestra, de un vistazo, si un modelo mejora realmente la detección de eventos raros pero importantes, cuánto beneficia a los casos comunes y qué predictores añadidos impulsan esos cambios. Para ámbitos como la medicina, el deporte, las finanzas y la seguridad industrial—donde perder un evento raro puede ser mucho más grave que provocar una falsa alarma ocasional—esta visión por clase puede guiar un mejor diseño de modelos y una comunicación más transparente sobre el riesgo.
Cita: Więckowska, B., Guzik, P. Usmile likelihood evaluation provides robust threshold free assessment of binary classification models for balanced and imbalanced datasets. Sci Rep 16, 10000 (2026). https://doi.org/10.1038/s41598-026-40545-z
Palabras clave: clasificación binaria, datos desbalanceados, evaluación de modelos, razón de verosimilitudes, aprendizaje automático explicable