Clear Sky Science · de
Usmile-Wahrscheinlichkeitsbewertung liefert robuste, schwellenwertfreie Beurteilung binärer Klassifikationsmodelle für ausgeglichene und unausgewogene Datensätze
Warum bessere Modellprüfungen für Alltagsentscheidungen wichtig sind
Von medizinischen Tests bis zur Kreditvergabe beantworten Computer häufig Ja‑oder‑Nein‑Fragen: Hat diese Patientin Herzkrankheiten? Ist diese Transaktion betrügerisch? Die Werkzeuge, mit denen wir die Qualität solcher Modelle beurteilen, können jedoch irreführend sein, besonders wenn das Gesuchte selten ist. Dieses Papier stellt eine neue Prüfmethode vor, die getrennt bewertet, wie gut Modelle wichtige, seltene Fälle erkennen und wie gut sie Fehlalarme vermeiden, und so ein klareres Bild für Entscheidungen mit hohen Einsätzen liefert.
Grenzen der heutigen Ein‑Zahlen‑Berichte
Die meisten heutigen Modell‑„Zeugnisse“, etwa die verbreitete ROC‑Kurve und ihr zusammenfassender Wert, die Fläche unter der Kurve, reduzieren die Leistung auf eine einzige Zahl. Diese Zahl vermengt Erfolge bei tatsächlich Betroffenen (Ereignissen) und bei Nicht‑Betroffenen (Nicht‑Ereignissen). In vielen realen Problemen, wie der medizinischen Diagnostik oder Betrugserkennung, ist die seltene Gruppe gerade die, die uns am meisten interessiert, und ihre Fehler sind deutlich teurer als Fehler in der häufigen Gruppe. Bei starker Ungleichverteilung — wenn es viel mehr Nicht‑Ereignisse als Ereignisse gibt — können traditionelle Maße suggerieren, ein Modell sehe sehr gut aus, obwohl es bei den seltenen, kritischen Fällen schlecht abschneidet.
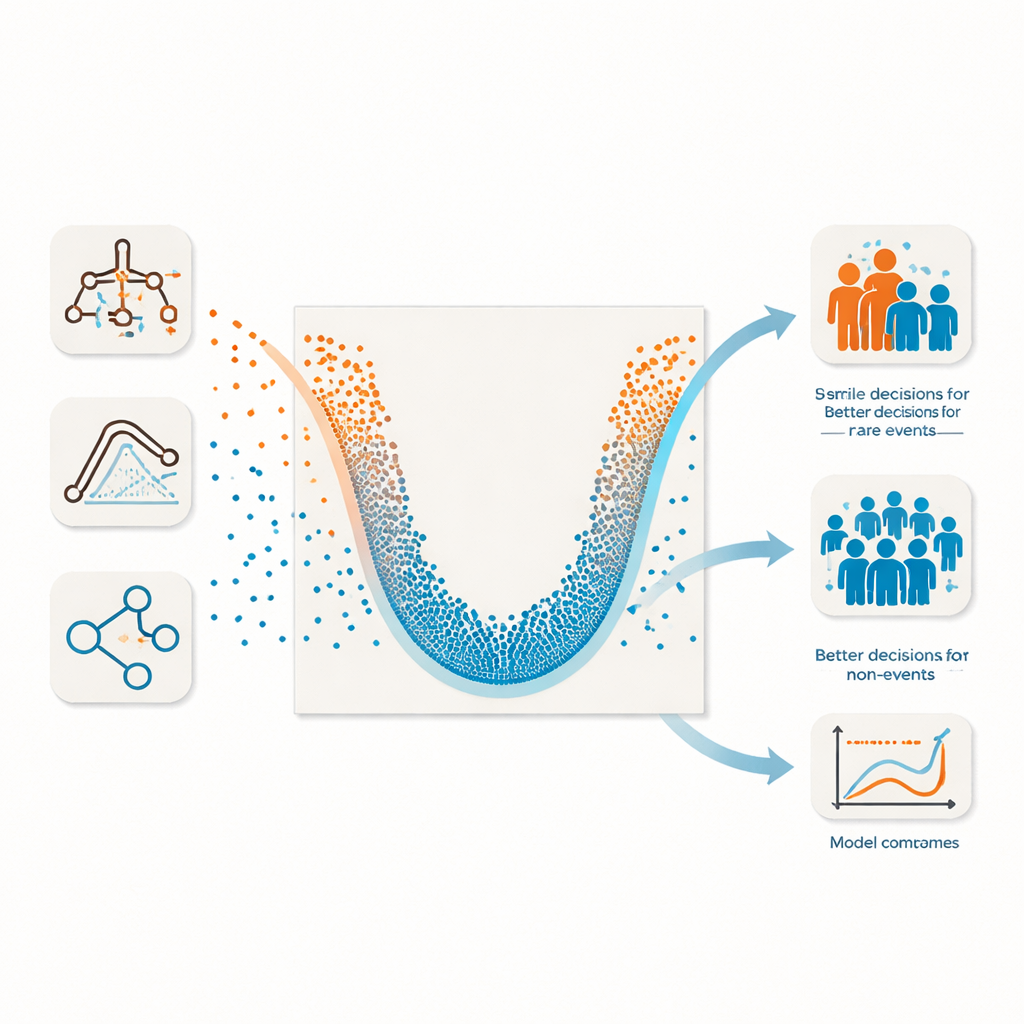
Eine neue „smile‑förmige“ Sicht auf Modellstärke
Die Autorinnen und Autoren führen ihre frühere U‑Form‑Visualisierung zu einer vollständigen Methode namens U‑smile Likelihood Evaluation aus. Im Kern steht ein neuer Score, das relative Likelihood‑Verhältnis, das vergleicht, wie viel wahrscheinlicher die Daten unter einem gegebenen Modell sind als unter einem einfachen Referenzmodell ohne nützliche Information. Dieser Score ist naturgemäß schwellenwertfrei: Er nutzt die rohen vorhergesagten Wahrscheinlichkeiten, statt den Anwender zu zwingen, eine Schwelle zu wählen. Entscheidend ist, dass er in separate Teile für die Ereignis‑ und Nicht‑Ereignisgruppen zerlegt wird. In einer U‑förmigen Darstellung zeigen farbige Punkte Verbesserungen für jede Gruppe: Ein tiefes, symmetrisches „Lächeln“ bedeutet, das Modell hilft beiden Gruppen; eine einseitige Form offenbart, wenn nur eine Gruppe profitiert. Die Punktgröße spiegelt wider, wie viele Personen betroffen sind, und die Linienstil zeigt an, ob die Verbesserung statistisch belastbar ist.
Wie sich die Methode bei ausgeglichenen und verzerrten Daten verhält
Um ihren Ansatz zu testen, erzeugten die Forschenden mehrere synthetische Datensätze, die verschiedene reale Herausforderungen nachahmen: schwache und starke Signale sowie stark unausgewogene Situationen, in denen nur einer von zehn Fällen ein Ereignis ist. Sie analysierten außerdem einen bekannten Herzkrankheitsdatensatz. Für jede Einstellung bauten sie Modelle schrittweise auf, indem sie je einen Prädiktor hinzufügten — entweder nach traditionellen ROC‑basierten Regeln oder nach den neuen U‑smile‑Kriterien. In ausgeglichenen Situationen wählten alle Methoden ähnliche Prädiktoren und erreichten nahezu identische Leistung, was darauf hindeutet, dass U‑smile mindestens so gut ist wie bestehende Praktiken, wenn die Daten gutmütig sind. Die echten Unterschiede zeigten sich bei Ungleichgewichten: Dort verbesserte die U‑smile‑geleitete Auswahl die Erkennung der Minderheitsklasse um bis zu 16 % in der Precision‑Recall‑Fläche und 21 % im F1‑Score verglichen mit ROC‑geleiteter Auswahl, während die Leistung für die Mehrheitsklasse stark blieb.

Zusehen, was jeder Prädiktor tatsächlich beiträgt
Weil U‑smile‑Plots nach jedem Modellschritt gezeichnet werden können, dienen sie zugleich als visuelles Logbuch des Modellwachstums. In den unausgeglichenen Beispielen verbesserten frühe Prädiktoren vor allem die Erkennung von Ereignisfällen und erzeugten ein schiefes Lächeln. Spätere Prädiktoren stellten das Gleichgewicht wieder her und vertieften sowie symmetrierten die Kurve. Separate Varianten der Methode können bewusst entweder Ereignisse oder Nicht‑Ereignisse favorisieren, sodass Nutzende Modelle an spezifische Ziele anpassen können — zum Beispiel die maximale Erkennung seltener Krankheiten, während eine andere Version das Vermeiden unnötiger Alarme betont. Die Autorinnen und Autoren wandten die Methode auch auf Random‑Forest‑Modelle an, die ganz anders als klassische logistische Regression arbeiten, und stellten fest, dass dieselben U‑förmigen Muster weiterhin klare Einsichten liefern, was zeigt, dass der Ansatz über viele Algorithmus‑Typen hinweg funktioniert.
Was das für echte Risikoentscheidungen bedeutet
Kurz gesagt bietet die Studie eine klarere, ehrlichere Art zu fragen: „Wem hilft dieses Modell wirklich?“ Statt einer einzigen schmeichelhaften Zahl zeigt U‑smile Likelihood Evaluation auf einen Blick, ob ein Modell tatsächlich die Erkennung seltener, aber wichtiger Ereignisse verbessert, wie sehr es häufige Fälle begünstigt und welche hinzugefügten Prädiktoren diese Veränderungen antreiben. In Bereichen wie Medizin, Sport, Finanzen und Arbeitssicherheit — wo das Verpassen eines seltenen Ereignisses weit schwerwiegender sein kann als ein gelegentlicher Fehlalarm — kann diese Klasse‑für‑Klasse‑Perspektive zu besserem Modelldesign und transparenterer Kommunikation über Risiken führen.
Zitation: Więckowska, B., Guzik, P. Usmile likelihood evaluation provides robust threshold free assessment of binary classification models for balanced and imbalanced datasets. Sci Rep 16, 10000 (2026). https://doi.org/10.1038/s41598-026-40545-z
Schlüsselwörter: binäre Klassifikation, unausgeglichene Daten, Modellevaluation, Wahrscheinlichkeitsverhältnis, erklärbares maschinelles Lernen