Clear Sky Science · es
Predicción del microbioma del suelo usando modelos tradicionales de aprendizaje automático y de aprendizaje profundo
Por qué importa la vida minúscula en el suelo
Cada cucharita de suelo alberga un mundo rebosante de bacterias y hongos que, sin hacer ruido, impulsan nuestra producción de alimentos, almacenan carbono y reciclan nutrientes. Aun así, seguimos teniendo dificultades para predecir qué microbios vivirán en un lugar concreto o cómo responderán ante cambios en el clima y en el uso del suelo. Este estudio plantea una pregunta práctica: ¿pueden los modelos informáticos modernos, entrenados con medidas ambientales básicas como temperatura, precipitación y química del suelo, pronosticar de forma fiable la composición de estas comunidades ocultas?
Big data encuentra el mundo subterráneo
Los investigadores se centraron en el microbioma del suelo, la vasta comunidad de microorganismos que vive en la tierra, y lo trataron como un sistema que podría ser predecible a partir de su entorno. Utilizando dos grandes conjuntos de datos públicos procedentes de sondeos globales del suelo y de la Red Nacional de Observatorios Ecológicos de EE. UU. (NEON), reunieron información sobre comunidades bacterianas y fúngicas junto con mediciones como pH del suelo, contenido de carbono y nitrógeno, clima y vegetación. En lugar de seguir cada especie individual, agruparon los microbios en categorías más amplias: niveles taxonómicos como filo, clase, orden, familia y género, y grupos funcionales que describen lo que hacen los microbios, como el ciclo del carbono o del nitrógeno.
Probando distintas formas de aprender de los datos
Para convertir las mediciones ambientales en predicciones de la composición comunitaria, el equipo comparó siete enfoques de modelado informático. Seis eran métodos ampliamente usados de aprendizaje automático “tradicional”, incluidos regresión lineal, árboles de decisión, bosques aleatorios (random forest), gradient boosting y k-vecinos más cercanos. El séptimo fue un modelo de aprendizaje profundo llamado perceptrón multicapa, un tipo de red neuronal. Para cada conjunto de datos y cada nivel taxonómico o funcional, los modelos fueron entrenados con la mayor parte de las muestras y luego se les pidió predecir las abundancias relativas de los grupos microbianos en muestras de suelo nuevas y no vistas. La exactitud de estas predicciones se midió con una estadística estándar (R²) que refleja cuánto de la variación del mundo real puede explicar el modelo.
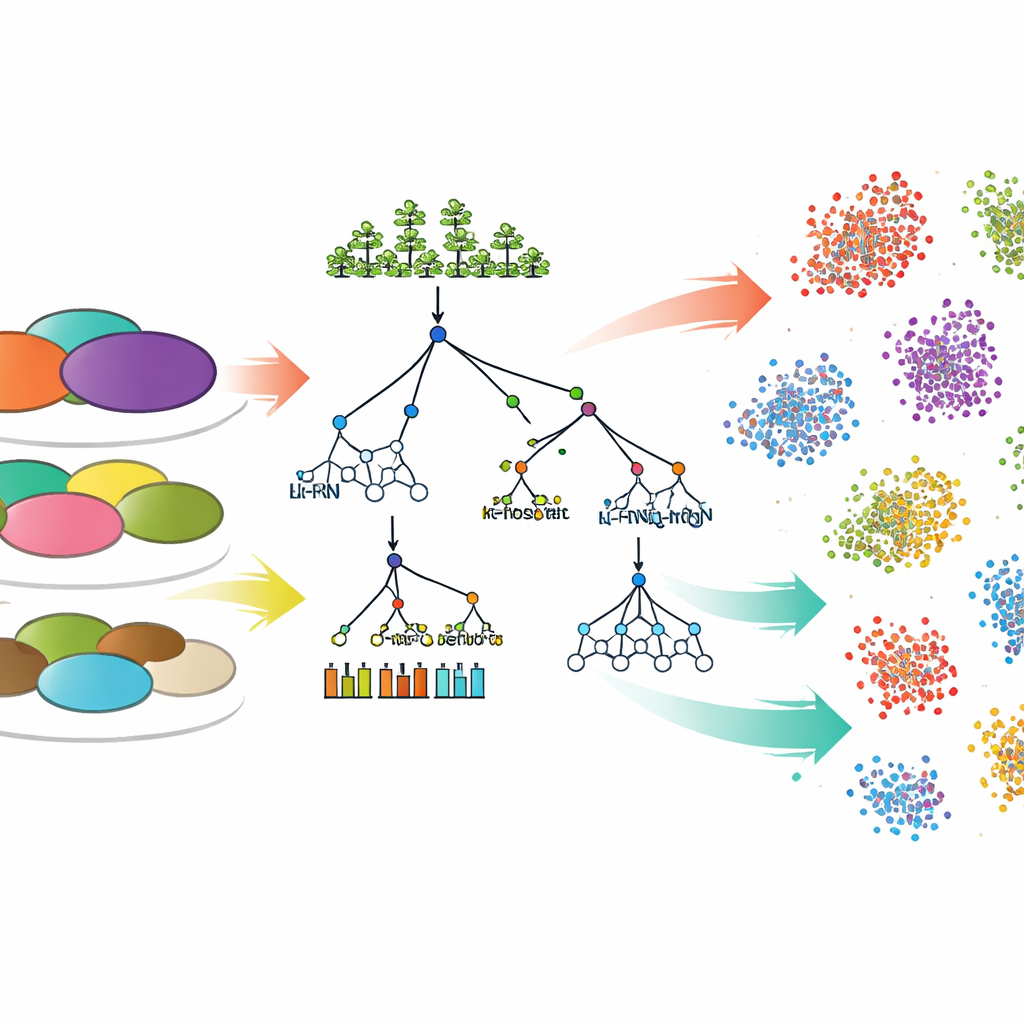
Patrones a distintas escalas en la comunidad del suelo
Surgió un patrón claro: es más fácil predecir agrupaciones amplias de microbios que prever los detalles finos. Tanto para bacterias como para hongos, los modelos generalmente funcionaron mejor en niveles taxonómicos superiores, como filo y clase, y se volvieron menos precisos al intentar distinguir categorías menores como familia y género. Esto sugiere que, aunque la mezcla exacta de microbios estrechamente relacionados puede ser difícil de anticipar, la estructura general de la comunidad está más ligada al ambiente. Apareció una excepción en los grupos funcionales bacterianos de un conjunto de datos, donde ninguno de los modelos captó bien los patrones, probablemente porque las categorías funcionales elegidas no reflejaban totalmente la verdadera complejidad de los roles microbianos.
Qué modelos funcionaron mejor y por qué
Entre todos los enfoques probados, dos métodos tradicionales—bosques aleatorios y k-vecinos más cercanos—ofrecieron de forma consistente las predicciones más sólidas. Los bosques aleatorios destacaron en niveles taxonómicos más amplios, mientras que k-vecinos fue especialmente eficaz en niveles más detallados como familia y género. Gradient boosting a veces igualó o superó a estos modelos, particularmente para grupos funcionales fúngicos, pero su rendimiento varió más entre niveles. Sorprendentemente, la red neuronal de aprendizaje profundo rara vez superó a estos métodos más simples. Los autores sostienen que esto se debe en gran medida a que el aprendizaje profundo suele requerir muchos más datos de entrenamiento que los pocos cientos o un par de miles de muestras de suelo disponibles aquí. En general, las comunidades bacterianas fueron más fáciles de predecir que las fúngicas, y los conjuntos de datos con más muestras arrojaron mejores resultados.
Qué implica esto para la gestión del suelo
El estudio demuestra que, incluso con los datos imperfectos de hoy, el aprendizaje automático ya puede ofrecer previsiones razonablemente buenas de las comunidades microbianas del suelo a niveles amplios. Eso es alentador para los esfuerzos de gestión del suelo en agricultura, restauración y mitigación climática, porque sugiere que podemos usar medidas ambientales relativamente sencillas para anticipar cambios generales en el mundo subterráneo. Al mismo tiempo, la dificultad para predecir detalles a escala fina y ciertos grupos funcionales subraya cuánto nos falta por conocer sobre los organismos del suelo y sus papeles. Serán necesarios conjuntos de datos mejores y más grandes y descripciones más ricas de las funciones microbianas antes de que el aprendizaje profundo y otras herramientas avanzadas puedan alcanzar su pleno potencial para orientar el cuidado del suelo vivo bajo nuestros pies.
Cita: Aouabed, Z., Therrien, V., Bouaoune, M.A. et al. Soil microbiome prediction using traditional machine learning and deep learning models. Sci Rep 16, 11069 (2026). https://doi.org/10.1038/s41598-026-39537-w
Palabras clave: microbioma del suelo, aprendizaje automático, bacterias y hongos, gradientes ambientales, predicción de comunidades