Clear Sky Science · de
Bodenmikrobiom-Vorhersage mit traditionellen Machine-Learning- und Deep-Learning-Modellen
Warum das winzige Leben im Boden wichtig ist
Jeder Teelöffel Erde beherbergt eine wimmelnde Welt aus Bakterien und Pilzen, die still die Lebensmittelproduktion antreiben, Kohlenstoff speichern und Nährstoffe recyceln. Dennoch fällt es uns weiterhin schwer vorherzusagen, welche Mikroben wo leben werden oder wie sie auf Klima- und Landnutzungsänderungen reagieren. Diese Studie stellt eine praktische Frage: Können moderne Computermodelle, die auf einfachen Umweltmessungen wie Temperatur, Niederschlag und Bodenkhemie trainiert sind, zuverlässig die Zusammensetzung dieser verborgenen Gemeinschaften vorhersagen?
Big Data trifft auf die unterirdische Welt
Die Forschenden konzentrierten sich auf das Bodenmikrobiom, die große Gemeinschaft von Mikroorganismen im Boden, und betrachteten es als ein System, das aus seiner Umgebung vorhersagbar sein könnte. Mithilfe zweier großer öffentlicher Datensätze aus globalen Bodenuntersuchungen und vom U.S. National Ecological Observatory Network (NEON) sammelten sie Informationen über bakterielle und pilzliche Gemeinschaften sowie Messwerte wie Boden-pH, Kohlenstoff- und Stickstoffgehalt, Klima und Vegetation. Anstatt jede einzelne Art zu verfolgen, fassten sie Mikroben in breitere Kategorien zusammen: taxonomische Ebenen wie Stamm, Klasse, Ordnung, Familie und Gattung sowie funktionale Gruppen, die beschreiben, was Mikroben tun, etwa den Kohlenstoff- oder Stickstoffkreislauf.
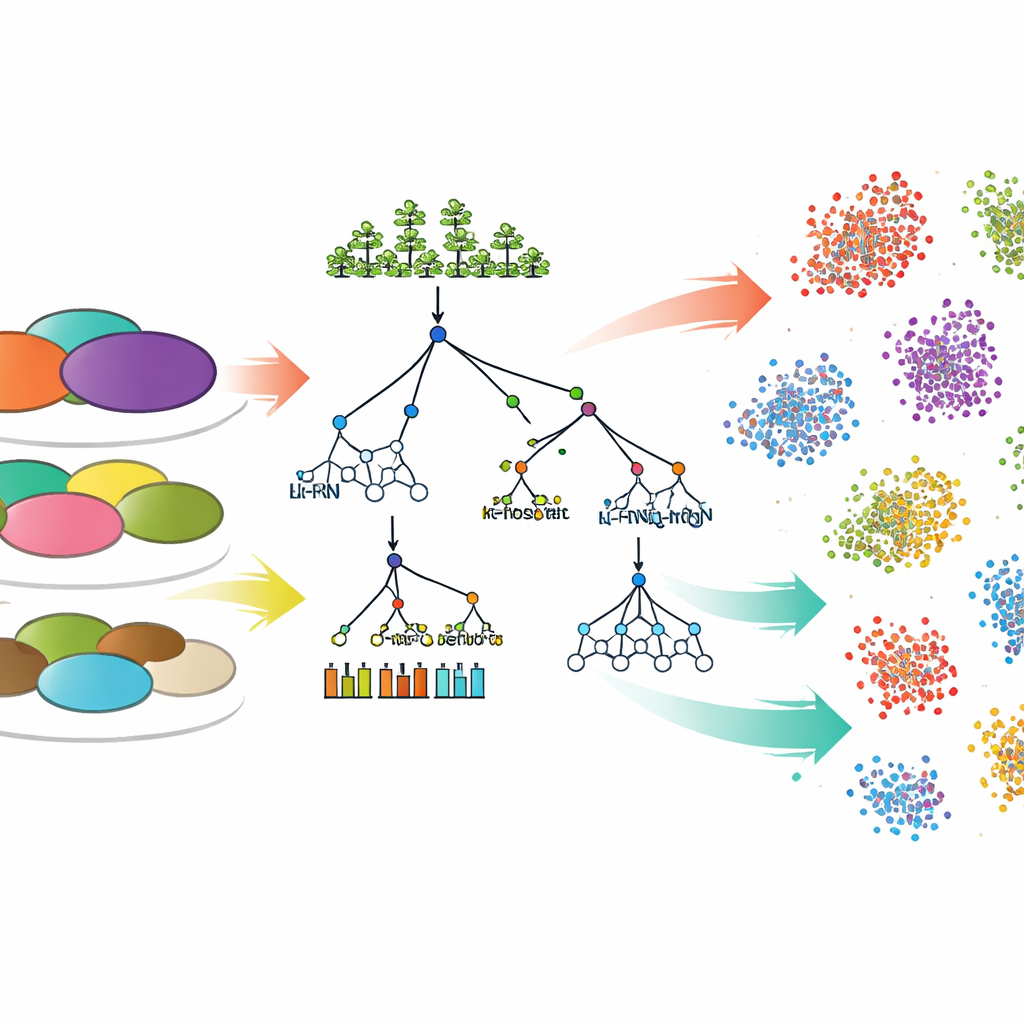
Unterschiedliche Lernansätze testen
Um Umweltmessungen in Vorhersagen der Gemeinschaftszusammensetzung zu übersetzen, verglich das Team sieben Computer-Modellierungsansätze. Sechs davon waren weitverbreitete „traditionelle“ Machine-Learning-Methoden, darunter lineare Regression, Entscheidungsbäume, Random Forests, Gradient Boosting und k-Nearest Neighbors. Das siebte war ein Deep-Learning-Modell namens Multilayer Perceptron, eine Art neuronales Netzwerk. Für jeden Datensatz und jede taxonomische bzw. funktionale Ebene wurden die Modelle auf den Großteil der Proben trainiert und anschließend gebeten, die relativen Häufigkeiten mikrobieller Gruppen in neuen, bisher ungesehenen Bodenproben vorherzusagen. Die Genauigkeit dieser Vorhersagen wurde mit einer Standardstatistik (R²) gemessen, die widerspiegelt, wie viel der realen Variation das Modell erklären kann.
Muster im Boden auf verschiedenen Skalen
Ein klares Muster zeigte sich: Es ist leichter, grobe Gruppierungen von Mikroben vorherzusagen als feine Details. Sowohl bei Bakterien als auch bei Pilzen lieferten die Modelle im Allgemeinen die besten Ergebnisse auf höheren taxonomischen Ebenen wie Stamm und Klasse und wurden weniger genau, je mehr sie versuchten, kleinere Kategorien wie Familie und Gattung zu unterscheiden. Das deutet darauf hin, dass, obwohl die genaue Zusammensetzung eng verwandter Mikroben schwer vorhersehbar ist, die Gesamtstruktur der Gemeinschaft stärker mit der Umgebung verknüpft ist. Eine Ausnahme trat bei bakteriellen Funktionsgruppen in einem Datensatz auf, wo keines der Modelle die Muster gut erfasste — wahrscheinlich, weil die gewählten Funktionskategorien die wahre Komplexität mikrobieller Rollen nicht vollständig widerspiegelten.
Welche Modelle am besten funktionierten und warum
Unter allen getesteten Ansätzen lieferten zwei traditionelle Methoden — Random Forest und k-Nearest Neighbors — durchweg die stärksten Vorhersagen. Random Forests glänzten auf breiteren taxonomischen Ebenen, während k-Nearest Neighbors besonders effektiv auf detaillierteren Ebenen wie Familie und Gattung war. Gradient Boosting erreichte teilweise ähnliche oder bessere Leistungen, insbesondere für pilzliche Funktionsgruppen, aber seine Performance schwankte stärker zwischen den Ebenen. Überraschenderweise übertraf das Deep-Learning-Neuronale Netzwerk diese einfacheren Methoden selten. Die Autorinnen und Autoren führen das größtenteils darauf zurück, dass Deep Learning typischerweise deutlich mehr Trainingsdaten benötigt als die hier verfügbaren wenigen hundert bis einigen tausend Bodenproben. Insgesamt waren bakterielle Gemeinschaften leichter vorherzusagen als pilzliche, und Datensätze mit mehr Proben lieferten bessere Ergebnisse.
Was das für die Bodenpflege bedeutet
Die Studie zeigt, dass Machine Learning schon mit den heutigen, noch unvollkommenen Daten brauchbare Vorhersagen von Bodenmikrobengemeinschaften auf groben Ebenen liefern kann. Das ist ermutigend für Maßnahmen zur Bewirtschaftung von Böden in Landwirtschaft, Renaturierung und Klimaschutz, weil es nahelegt, dass wir mit relativ einfachen Umweltmessungen großräumige Veränderungen der unterirdischen Welt antizipieren können. Zugleich unterstreicht die Schwierigkeit, feinmaßstäbliche Details und bestimmte Funktionsgruppen vorherzusagen, wie viel wir über Bodenorganismen und ihre Rollen noch nicht wissen. Bessere, größere Datensätze und reichere Beschreibungen mikrobieller Funktionen werden nötig sein, bevor Deep Learning und andere fortgeschrittene Werkzeuge ihr volles Potenzial entfalten können, um zu leiten, wie wir den lebenden Boden unter unseren Füßen pflegen.
Zitation: Aouabed, Z., Therrien, V., Bouaoune, M.A. et al. Soil microbiome prediction using traditional machine learning and deep learning models. Sci Rep 16, 11069 (2026). https://doi.org/10.1038/s41598-026-39537-w
Schlüsselwörter: Bodenmikrobiom, Machine Learning, Bakterien und Pilze, Umweltgradienten, Gemeinschaftsvorhersage