Clear Sky Science · es
Un archivo digital revela cómo una agencia financiadora cooperó con académicos para apoyar el campo incipiente de la genómica
Cómo un archivo oculto moldeó la genética moderna
Hoy en día hablamos con frecuencia de pruebas de ADN, medicina personalizada y descubrimientos que vinculan genes con enfermedades. Detrás de estos avances hay una enorme cantidad de planificación, financiación y coordinación discreta. Este artículo abre una ventana a ese mundo entre bastidores al analizar un archivo digital único del Instituto Nacional de Investigación del Genoma Humano de EE. UU. (NHGRI). Muestra, con un detalle sin precedentes, cómo una agencia pública de financiación trabajó mano a mano con científicos universitarios para convertir la genómica de una idea audaz en un pilar central de la biomedicina moderna. 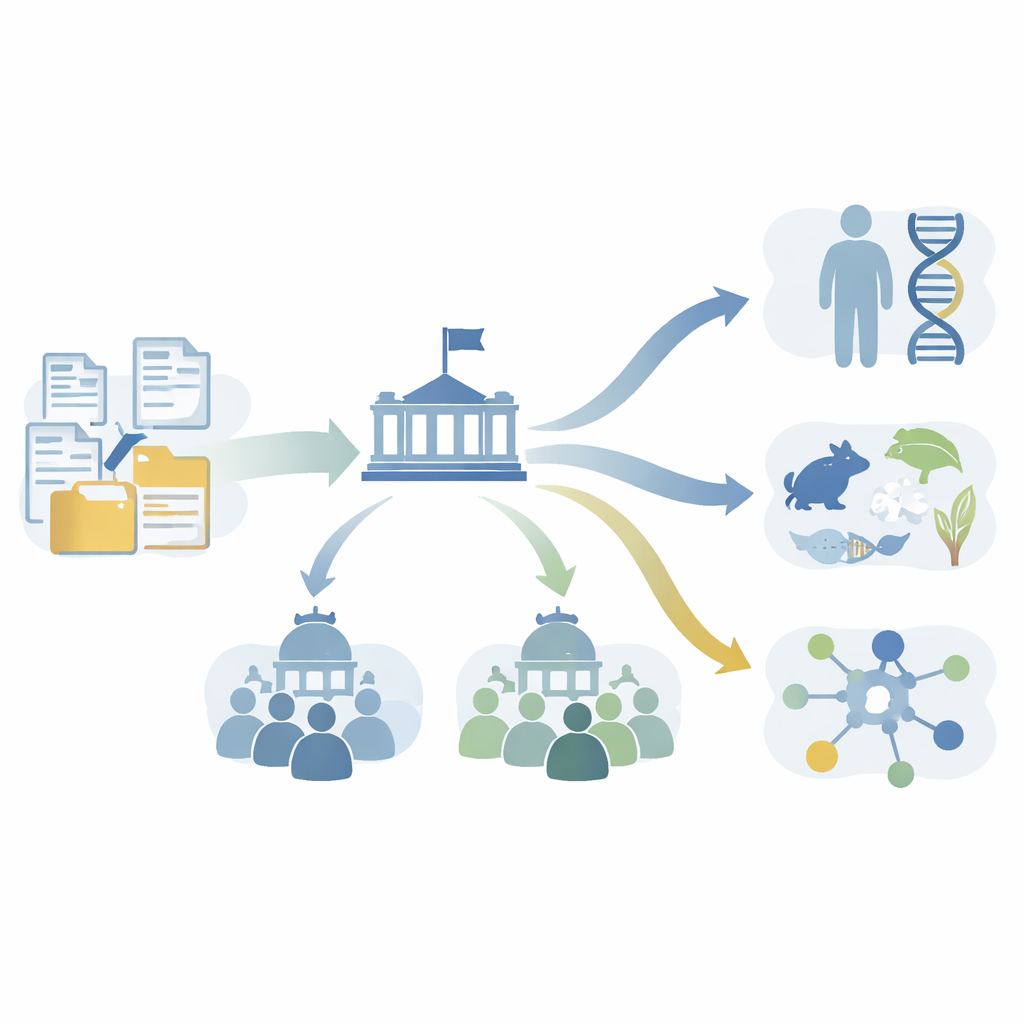
Convertir cajas de papeles en un tesoro digital
La historia comienza con un archivo que podría sonar mundano: más de dos millones de páginas de correos electrónicos, informes, memorandos y actas de reuniones conservadas en el NHGRI. Estos materiales documentan el Proyecto Genoma Humano y las iniciativas de genómica que le sucedieron. Los autores convirtieron un subconjunto cuidadosamente curado, llamado Colección Central, en un recurso totalmente digital. Utilizaron escaneo de alta velocidad, visión por computador para eliminar anotaciones manuscritas y reconocimiento óptico de caracteres para extraer el texto impreso. Luego aplicaron métodos de inteligencia artificial para detectar nombres, organizaciones, términos científicos clave y fechas, a la vez que codificaron o enmascararon datos personales para proteger la privacidad. Esta cadena de procesamiento transformó pilas polvorientas de papel en datos buscables y analizables sobre cómo se construyó realmente la genómica.
Encontrar el nacimiento de una nueva forma de estudiar la enfermedad
Con este tesoro digital en las manos, los investigadores se preguntaron: ¿podrían recuperar los pasos iniciales de grandes ideas científicas antes de que se hicieran famosas? Se centraron en los estudios de asociación del genoma completo (GWAS), hoy una forma estándar de buscar en genomas enteros pequeñas diferencias vinculadas a enfermedades comunes. Los datos bibliométricos muestran que los GWAS han sido una de las técnicas más influyentes en la biomedicina moderna, tanto en citas como en la incorporación de genes previamente desconocidos a la literatura. Al escanear el archivo, los autores encontraron que los GWAS aparecen en documentos del NHGRI años antes de que se publicaran los primeros artículos emblemáticos sobre GWAS. Agendas internas de talleres y documentos de planificación muestran a líderes del NHGRI y expertos externos reconociendo la promesa de los GWAS, debatiendo qué recursos de datos serían necesarios y luego lanzando el Proyecto Internacional HapMap para construir esos recursos. En otras palabras, la agencia y los académicos sentaron conjuntamente las bases para los GWAS antes de que los laboratorios individuales pudieran realizarlos de forma realista.
Tras bambalinas de grandes proyectos internacionales
El archivo también expone la maquinaria social cotidiana de las grandes colaboraciones. Al reconstruir redes a partir de más de 47.000 intercambios de correo electrónico, los autores mapearon quién hablaba con quién durante el Proyecto Genoma Humano y el posterior proyecto HapMap. En lugar de un único centro de mando, hallaron múltiples grupos superpuestos de personal gubernamental y científicos externos. Un pequeño círculo de figuras sénior —apodado el “Kitchen Cabinet” en algunos mensajes— conectaba a líderes internos, consejos asesores y comités directivos internacionales. El análisis de redes sugiere que este grupo a menudo desempeñó roles de intermediario: traduciendo preocupaciones técnicas, preparando asuntos complejos antes de reuniones formales y preservando la continuidad a medida que los proyectos evolucionaban y llegaban nuevos participantes. 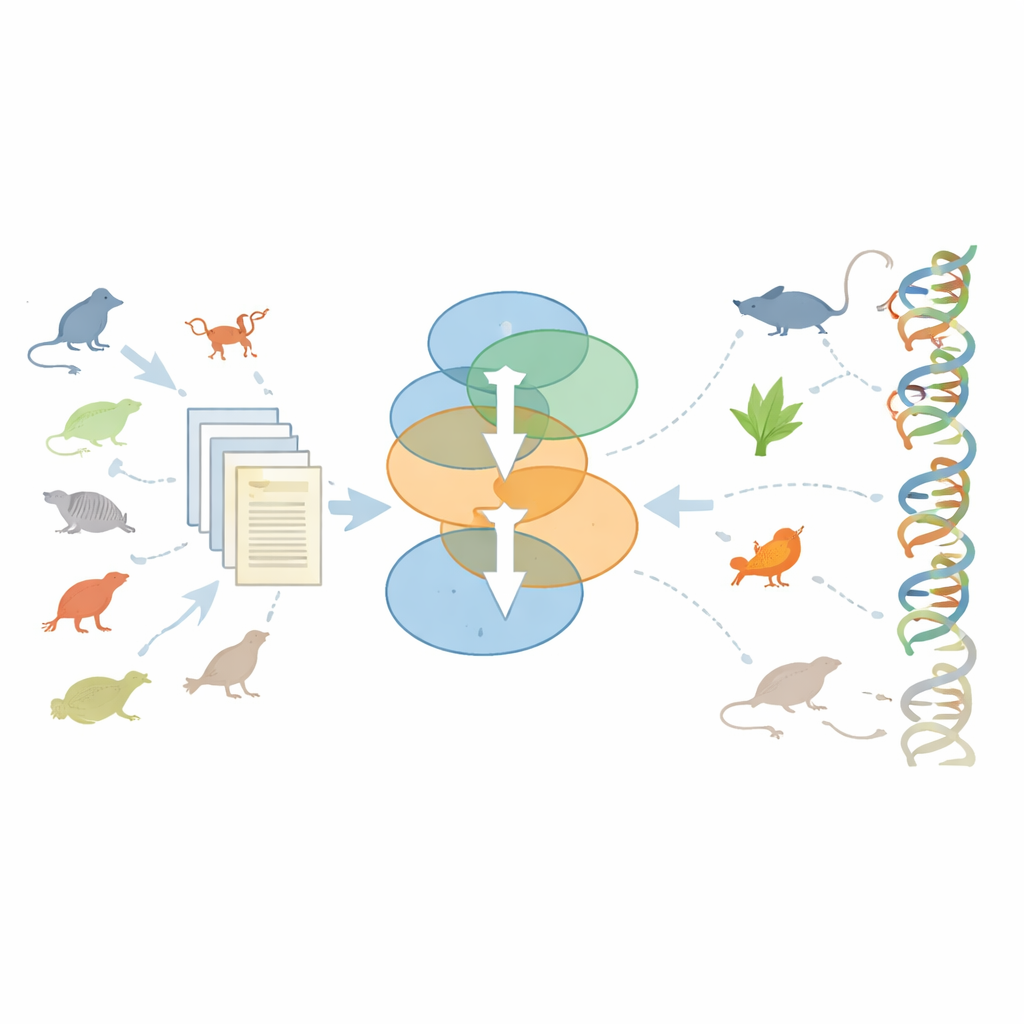
Elegir qué criaturas obtienen su genoma secuenciado
Otra cuestión importante fue cómo el NHGRI y la comunidad investigadora decidieron qué especies no humanas debían secuenciarse tras el Proyecto Genoma Humano. Las propuestas provenían tanto de grupos de trabajo internos como de científicos externos, que argumentaban a favor de animales concretos —desde vertebrados familiares hasta invertebrados poco conocidos. Los autores reconstruyeron manualmente este proceso de selección y luego construyeron modelos de aprendizaje automático para ver si podían imitar las decisiones del consejo asesor usando características como el tamaño de la comunidad investigadora en torno a un organismo, la diversidad y la fuerza persuasiva del lenguaje de la propuesta y hechos biológicos simples, como el tamaño del genoma. Sus modelos predijeron las decisiones de aprobación con alta precisión, lo que indica que estos factores en conjunto capturaban gran parte del razonamiento real. De manera crucial, los organismos aprobados no atrajeron necesariamente más artículos en total posteriormente, pero la investigación sobre ellos se orientó de forma decisiva hacia métodos genómicos una vez que sus genomas estuvieron disponibles.
Por qué esta historia oculta importa hoy
Al entrelazar minería de textos, análisis de redes y rigurosas salvaguardias éticas, el estudio muestra que la innovación en genómica no fue solo obra de genios solitarios o descubrimientos fortuitos. En cambio, el NHGRI actuó como un centro colaborativo que escuchó a expertos externos, ensambló recursos de datos compartidos y respaldó estratégicamente especies y tecnologías capaces de impulsar campos enteros. El archivo digital revela que algunos de los pasos más importantes —como planificar los GWAS o priorizar qué organismos secuenciar— ocurrieron antes de que los números de subvenciones o los recuentos de citas aparecieran en bases de datos públicas. Para el lector general, el mensaje clave es que una financiación pública reflexiva, guiada por el diálogo continuo con los científicos y basada en una gestión responsable de los datos, puede moldear discretamente la dirección de la ciencia durante décadas.
Cita: Hong, S.S., Utz, Z., Hosseini, M. et al. A digital archive reveals how a funding agency cooperated with academics to support the nascent field of genomics. Nat Commun 17, 3621 (2026). https://doi.org/10.1038/s41467-026-71700-9
Palabras clave: genómica, financiación de la investigación, Proyecto Genoma Humano, archivos digitales, secuenciación del genoma