Clear Sky Science · en
Evaluating multimodal commercial and open-source large language models for dynamical astronomy: a benchmark study of resonant behavior classification
Why this matters for stargazers and data fans
Astronomers spend a surprising amount of time doing something that looks very down-to-earth: staring at plots and deciding which ones “wiggle,” which ones “drift,” and which ones behave chaotically. These patterns reveal whether asteroids are locked into subtle orbital dances with the planets, shaping how our Solar System evolves over billions of years. This paper asks a timely question: can modern AI systems that understand both text and images step in and make those judgments as reliably as human experts—without any special training?
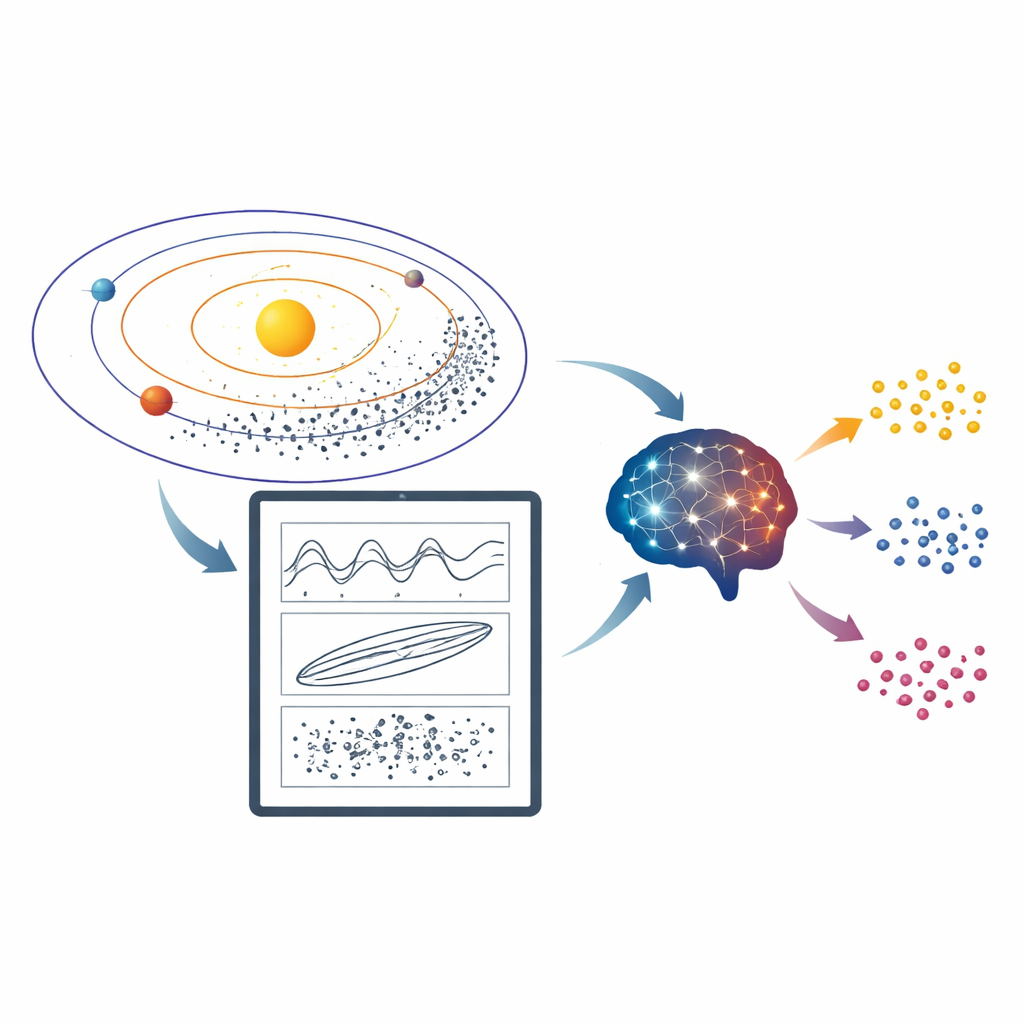
The hidden traffic rules of the Solar System
Many asteroids do not simply circle the Sun in isolation. Their paths are nudged by regular gravitational tugs from planets, a situation known as orbital resonance. When an asteroid’s motion matches that of a planet in a simple rhythm, its orbit can become trapped, excited, or destabilized. Astronomers diagnose this by plotting a quantity called a “resonant angle” over time. If the points on the plot oscillate within a band, the object is in resonance; if they wrap diagonally across the whole vertical range, it is outside resonance; if they switch back and forth, the behavior is more ambiguous or temporary. For clear-cut cases, simple computer rules work well—but in crowded regions of space, such as the main asteroid belt, overlapping influences produce messy, noisy plots that are hard to classify automatically and have traditionally required expert eyes.
From custom algorithms to general-purpose AI
Until recently, researchers relied on two broad strategies. Classical machine-learning models, such as decision trees and neural networks, can be trained to recognize specific kinds of resonance, but each new problem needs its own labeled dataset, tuning, and code. Deterministic methods, based on carefully designed rules and frequency analysis, can perform well when the signal is clean, but they struggle when resonances overlap or appear only temporarily. Both approaches break down precisely where things are most interesting scientifically: in borderline cases with temporary captures, resonance “sticking,” and chaotic motion. By contrast, modern large language models (LLMs) that can inspect images promise something different: zero-shot reasoning. Instead of being trained on thousands of specialized examples, they are given a natural-language instruction and a plot and asked to decide which category best describes the behavior.
Building a fair test for AI eyes
To probe how well these models really do, the authors created a suite of benchmark image sets showing resonant angles for both mean-motion and secular resonances—two key classes of orbital interactions. Each image is a scatter plot of angle versus time compiled from long numerical simulations, and each has been carefully labeled by experts as resonant, non-resonant, transient, or, in the most extreme edge cases, controversial. Four datasets were assembled: a tiny “sanity check” set (RB-TEST), a 50-image pilot set comparable to earlier work (RB-PILOT), a 50-image set packed with ambiguous cases (RB-SMALL), and a large 450-image collection sampling all behaviors (RB-FULL). The authors then fed these images to a wide roster of models: top-tier commercial systems, large open-source models, and small open-source models that can run on a personal computer. Larger models received detailed step-by-step prompts; smaller ones used a simpler, lighter set of rules.
How well the machines did the astronomers’ job
On the easiest tests, many models—commercial and open-source alike—classified every image correctly. On the mid-level RB-PILOT set, leading commercial systems maintained near-perfect scores, while the best open-source models came quite close. The real challenge was RB-SMALL, where many plots show mixtures of behaviors that even experts debate. Here, the best commercial model still reached about 94 percent on a combined score of precision and recall, while the best open-source model reached around 76 percent. The larger RB-FULL set confirmed this pattern: commercial models and top open-source systems both achieved high accuracy when the task was reduced to a simpler yes-or-no decision about resonance, with most mistakes concentrated in tricky transient and sticking regimes. Notably, some smaller models that can run locally still delivered practically useful performance, especially for straightforward two-class labeling.
What this means for future sky surveys
For a non-specialist, the takeaway is that general-purpose AI systems can now look at the same noisy orbital plots that once demanded expert human judgment and reach conclusions that, in many cases, rival or even match traditional tools—without being trained directly on that task. They are not perfect, especially when an asteroid only flirts with resonance rather than committing to it, but they can already shoulder much of the tedious visual inspection needed for large surveys. The benchmark released in this study gives astronomers a standard, reusable way to test new models and choose the right trade-off between cost, openness, and accuracy. As multimodal AI continues to improve, it is likely to become a routine partner in mapping the intricate gravitational choreography of the Solar System.
Citation: Smirnov, E., Carruba, V. Evaluating multimodal commercial and open-source large language models for dynamical astronomy: a benchmark study of resonant behavior classification. Sci Rep 16, 10785 (2026). https://doi.org/10.1038/s41598-026-45926-y
Keywords: orbital resonances, multimodal AI, asteroid dynamics, time series classification, open-source language models