Clear Sky Science · en
POLAR-DETR: Polarized occlusion-aware local-global attention real-time detection transformer for total laboratory automation
Smarter Robots for Crowded Medical Labs
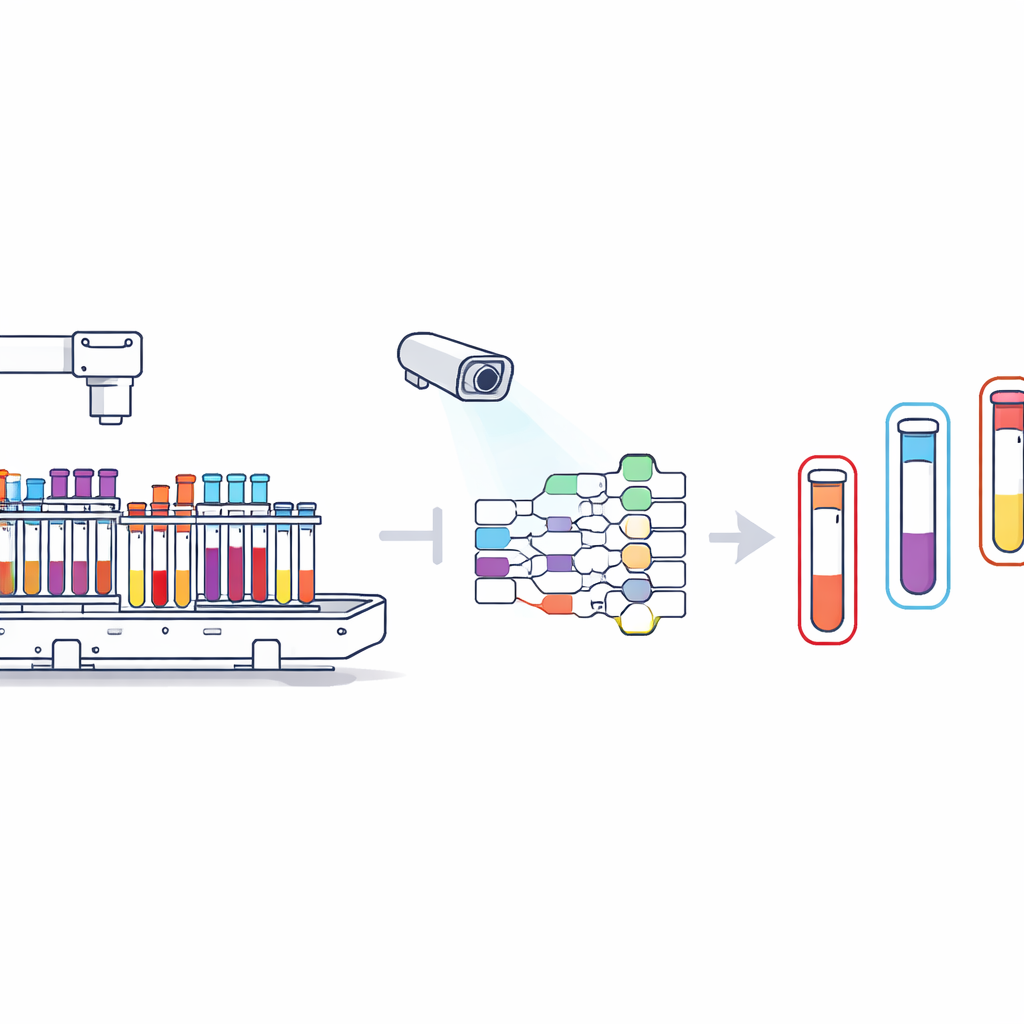
Behind every blood test is a busy production line where racks of tubes zip past scanners and robots. As hospitals push toward fully automated laboratories, these lines must identify thousands of tightly packed, look‑alike tubes in real time, even when they overlap or hide one another. This paper introduces POLAR‑DETR, a new vision system designed to help lab robots see reliably in this cluttered, cramped world, paving the way for faster, safer, and more accurate testing.
Why Seeing Test Tubes Is Hard
Modern laboratories increasingly use machines to move and sort samples, but the space around these lines is limited. Instead of long conveyor belts, labs are turning to compact robotic systems that rely heavily on cameras. These cameras must pick out every tube, rack, and carrier in scenes where objects are small, tightly packed, and often partially hidden. Popular fast detectors used in other industries, like the YOLO family of algorithms, begin to struggle under these conditions. They depend on an extra decision step to filter overlapping predictions and can miss tiny or occluded objects, leading to errors that are unacceptable when dealing with medical samples.
A New Vision Engine for the Lab
Building on recent advances in transformer‑based vision models, the authors design POLAR‑DETR specifically for medical production lines. Instead of a chain of hand‑tuned steps, it uses an end‑to‑end design that directly turns camera images into tube locations and types in one pass, avoiding the usual extra filtering stage. At its core is a new feature encoder that pays special attention to how objects relate in space and how they block one another. By reshaping how the model scans each image, the encoder helps it focus on the right regions, preserving fine details of small tubes while still understanding the broader scene. This makes the system more resilient when tubes overlap, cluster together, or vary greatly in size.
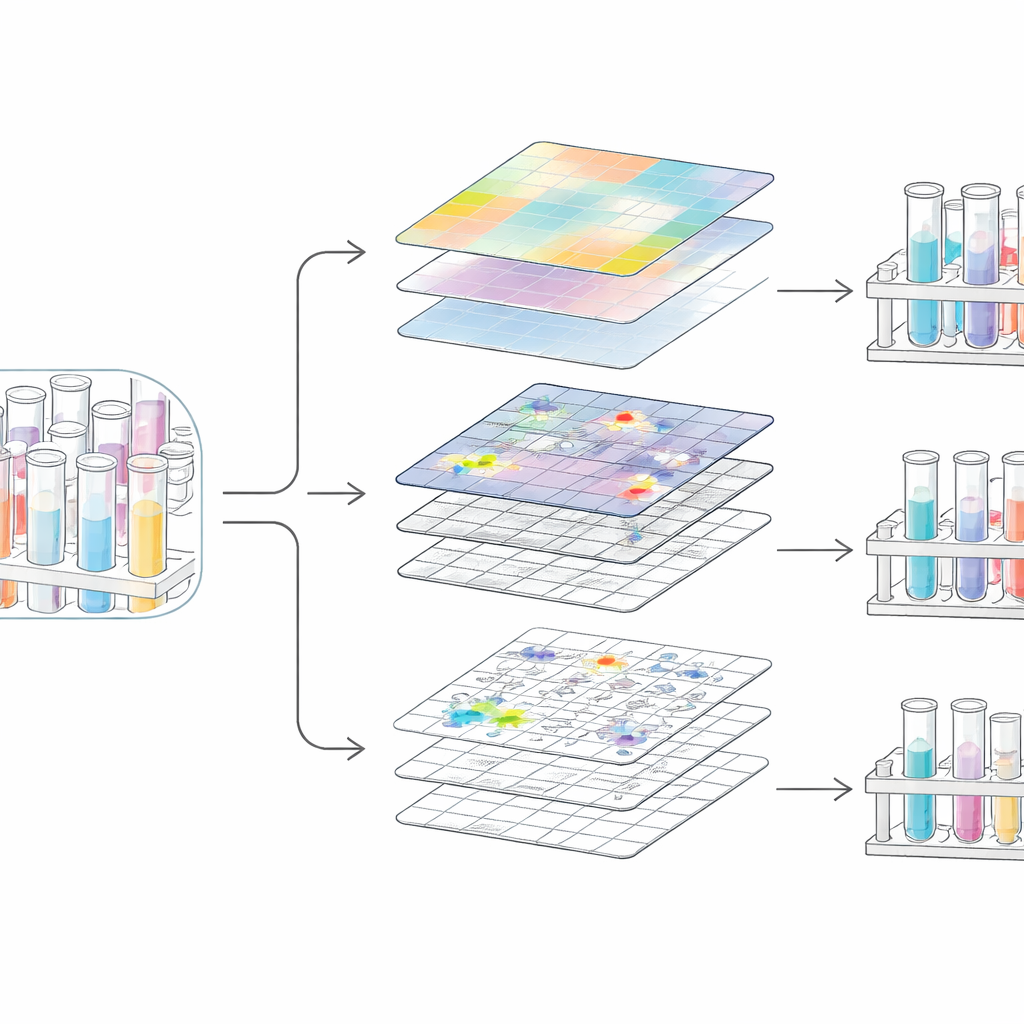
Blending Details and Big Picture
To understand crowded scenes, a vision system must balance the tiny details at tube edges with the overall layout of racks and carriers. POLAR‑DETR tackles this with two complementary fusion modules. One module links information across multiple scales and positions, treating groups of image regions as flexible relationships rather than simple grids. This helps the system recognize, for example, that a faint tube edge likely belongs to a group of neighboring tubes rather than to the background. A second module explicitly splits processing into a "local" branch that sharpens textures and boundaries, and a "global" branch that tracks long‑range patterns. The results from both are then recombined, yielding clearer object boundaries and fewer mix‑ups between tubes and surrounding equipment.
Trimming the Network for Real‑World Speed
High‑accuracy vision models can be heavy and slow, which is a problem on industrial machines that may run around the clock. The authors introduce a pruning strategy that analyzes how strongly each internal pathway affects the model’s output. Pathways that contribute little are removed in an informed way, rather than at random or by simple size rules. This selective trimming cuts the number of parameters by about one fifth and the computation by nearly one quarter, yet the model actually becomes more accurate. On their medical production line dataset, POLAR‑DETR reaches 70% average precision while running at about 68 frames per second, fast enough for real‑time robotic use.
Building a Realistic Testbed
To judge whether POLAR‑DETR truly works in practice, the team assembled a new dataset from an operational medical production line. Using consumer‑grade cameras under varying lighting, they captured thousands of high‑resolution images of racks, carriers, and several tube types, including capped, uncapped, and different test categories. Experts labeled more than eighty thousand individual objects. They then expanded the training data with controlled rotations, crops, brightness changes, synthetic noise, and mosaic combinations, mimicking real‑world shifts in orientation, lighting, and clutter. This dataset not only stresses the model with dense, small, and occluded tubes, but also provides a public benchmark for other researchers working on lab automation.
What This Means for Future Labs
In plain terms, POLAR‑DETR is a sharper pair of eyes for automated laboratories. By carefully redesigning how a vision system pays attention to crowded scenes and then slimming it down for speed, the authors achieve both higher accuracy and lower computational cost than many existing approaches. The system spots more tubes, makes fewer mistakes in busy backgrounds, and keeps up with the pace of industrial hardware. As labs continue to automate, approaches like this could make specimen handling more reliable and flexible, ultimately contributing to faster test results and more robust healthcare workflows.
Citation: Zu, Y., Li, S. & Zhang, L. POLAR-DETR: Polarized occlusion-aware local-global attention real-time detection transformer for total laboratory automation. Sci Rep 16, 11949 (2026). https://doi.org/10.1038/s41598-026-42038-5
Keywords: laboratory automation, object detection, medical production line, computer vision, transformer models