Clear Sky Science · de
Modellierung kopf- und ohrmuschellogungsübertragungsfunktionen mittels Randlementen und Finite-Differenzen mit Volumenpenalisierung
Warum die Form Ihrer Ohren für virtuellen Klang wichtig ist
Wenn Sie Kopfhörer aufsetzen und einen Ton so wahrnehmen, als käme er von hinten oder von oben, nutzt Ihr Gehirn winzige akustische Hinweise, die durch die einzigartige Form Ihres Kopfes und Ihrer Ohren entstehen. Dieser Beitrag untersucht, wie sich diese Hinweise am Computer realistisch nachbilden lassen, ohne für jede Person stundenlange Messungen im Labor durchführen zu müssen. Die Autoren vergleichen zwei fortgeschrittene numerische Verfahren, um zu prüfen, wie gut sie das Biegen, Reflektieren und Beugen von Schall um Kopf und Außenohr nachahmen können.
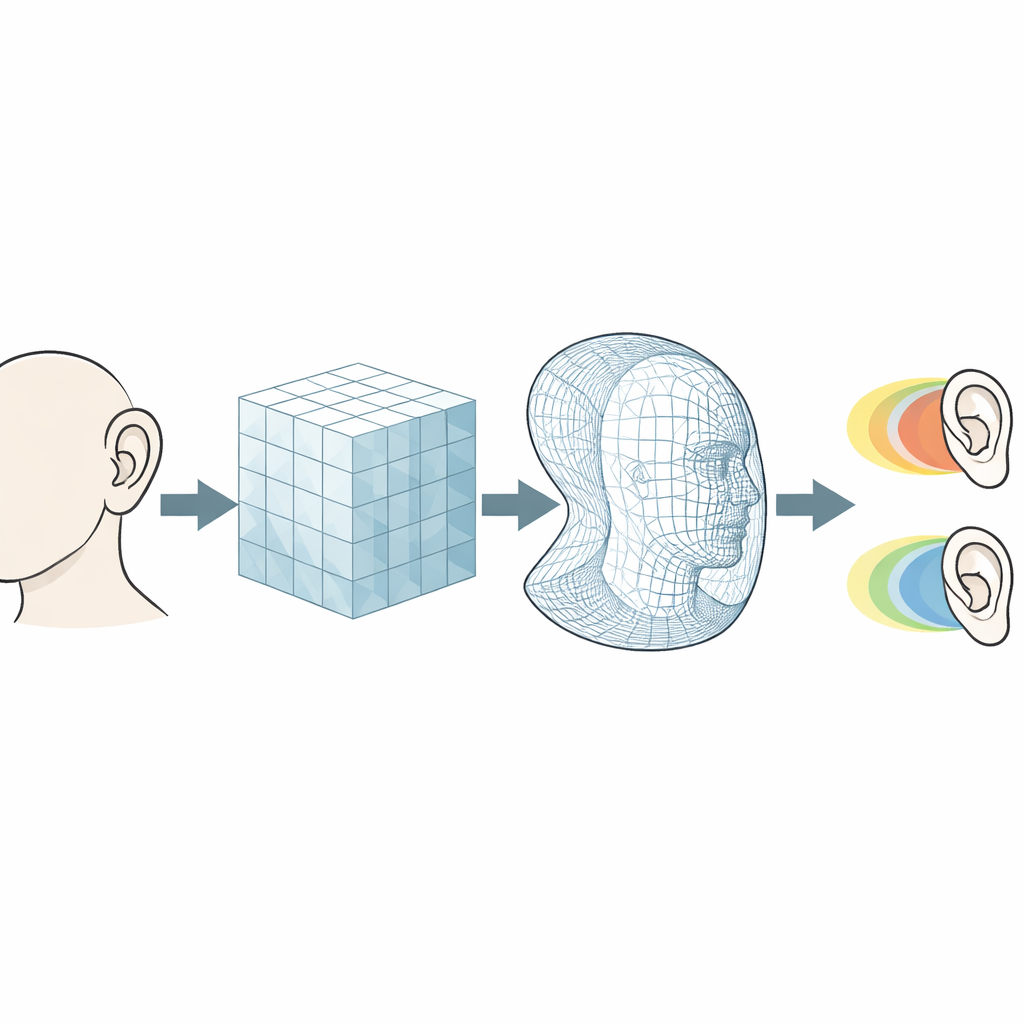
Wie unsere Ohren dreidimensionalen Klang kodieren
Jeder von uns hat einen persönlichen „akustischen Fingerabdruck“, die sogenannte head-related transfer function (HRTF). Wenn Schallwellen auf Rumpf, Kopf und die komplexen Faltungen des Außenohrs treffen, werden bestimmte Frequenzen verstärkt, andere gedämpft. Diese Veränderungen hängen von der Richtung ab: vorne vs. hinten, oben vs. unten, links vs. rechts. Das Gehirn hat gelernt, diese Muster zu lesen, um die Herkunft von Schallquellen zu bestimmen. Für überzeugende virtuelle und erweiterte Realität möchten Audiotechniker HRTFs, die auf jeden Hörer zugeschnitten und sehr dicht im Raum abgetastet sind. Direkte Messungen an realen Personen oder an Messköpfen sind möglich, aber langsam, technisch aufwändig und anfällig für kleine Positionierungsfehler, die das Hörergebnis beeinträchtigen können.
Zwei mathematische Blickwinkel auf dasselbe Hörproblem
Um langwierige Messungen zu vermeiden, simulieren Forscher die Schallausbreitung um hochdetaillierte 3D-Modelle von Kopf und Ohr. Die Studie vergleicht zwei führende Strategien. Die eine, bekannt als Rand-Elemente-Methode, beschreibt nur die Oberfläche von Kopf und Ohr und löst, wie diese Oberfläche Schall streut. Die andere, die Finite-Differenzen-Zeitbereichs-Methode, füllt ein Volumen um den Kopf mit einem Gitter und führt die Schallwellen schrittweise in der Zeit fort. Die volumetrische Methode ist flexibler, kann aber für große Bereiche sehr kostspielig werden. Die Autoren verbessern sie mit einem „Volumen-Penalisierungs“-Trick: Anstatt die Ohroberfläche als treppenförmige Approximation auf dem Gitter darzustellen, mischen sie Luft und festes Material über eine dünne Schicht hinweg glatt, was die Darstellung von Reflexionen und Schatten deutlich verbessert.
Testen der Modelle an einfachen Formen und einem echten Ohr
Bevor die Methoden auf einen vollständigen menschlichen Kopf angewandt werden, validiert das Team sie an sorgfältig kontrollierten Testfällen. Zuerst simulieren sie Beugung von Schall um eine starre Kugel, für die eine exakte Lehrbuchlösung bekannt ist. Beide Methoden folgen dieser Referenz über den hörbaren Frequenzbereich hinweg eng, wobei die Randmethode und fein aufgelöste Gitter in der volumetrischen Methode Abweichungen im Bereich von Bruchteilen eines Dezibels zeigen. Als Nächstes untersuchen sie eine einzige flache Wand, um herauszufinden, wie viele Gitterpunkte in der Übergangsschicht nötig sind, damit reflektierter Schall die korrekten Peaks und Notches aufweist. Aus diesen Tests leiten sie einfache Regeln ab, die Gitterabstand mit der minimal modellierbaren Wanddicke verknüpfen, ohne hörbare Fehler einzuführen. Mit diesen Regeln simulieren sie dann eine hochauflösende 3D-gedruckte Ohrmuschel und vergleichen die Ergebnisse mit präzisen Messungen. Bei ausreichend feinen Gittern unterscheiden sich die simulierten Ohrantworten im Mittel nur um etwa ein Dezibel von den gemessenen — nahe der Schwelle, ab der Kolorierung in Hörtests bemerkbar wird.
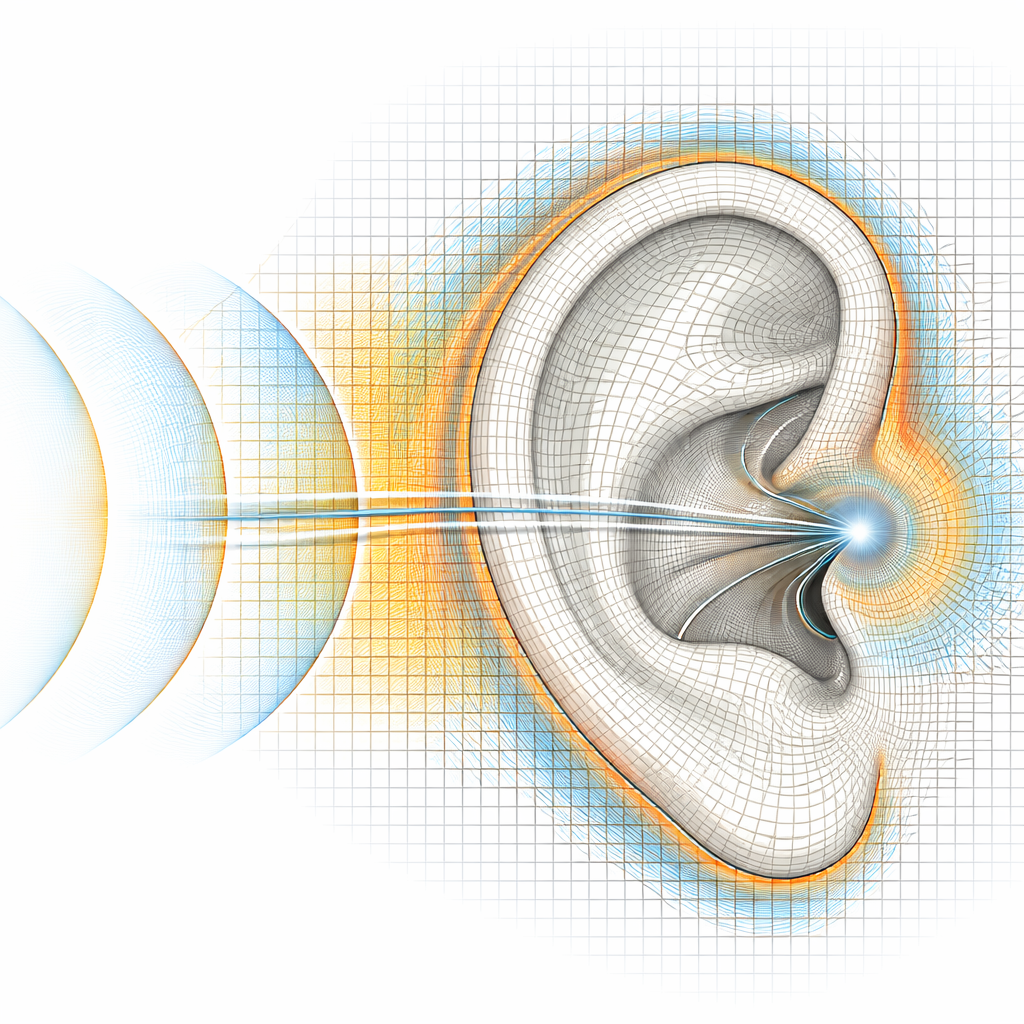
Vom isolierten Ohr zum kompletten Kopf
Als letzter Schritt simulieren die Autoren ein vollständiges Kopfnetz, das in der 3D-Audio-Forschung häufig verwendet wird. Sie berechnen, wie Schall aus vielen horizontalen Richtungen am verschlossenen Gehörgang transformiert wird, und vergleichen die volumetrische Methode mit Penalisierung mit der etablierten Randmethode. Wenn das Gitter fein genug ist, um die dünnsten Teile des Ohrs aufzulösen, stimmen die beiden Ansätze für die meisten Richtungen und Frequenzen sehr gut überein, selbst wenn man ein auditives Modell zur Abschätzung wahrgenommener tonaler Veränderungen anwendet. Grobere Gitter verschieben hingegen die Frequenzen und die Stärke wichtiger Peaks und Notches, die mit Ohrresonanzen und Reflexionen zusammenhängen, und unterstreichen, dass geometrische Detailtreue nicht ohne hörbare Folgen geopfert werden kann.
Was das für zukünftiges virtuelles Audio bedeutet
Für Fernfeld-Szenarien und große Domänen bleibt die randbasierte Methode auf heutiger Hardware effizienter, doch die verbesserte volumetrische Methode bietet wichtige Vorteile. Sie kann natürlich kleine interne Hohlräume, räumlich variierende Materialien und zukünftige Optimierungsaufgaben behandeln, bei denen die Form von Kopfhörern oder Ohren in der Simulation angepasst werden könnte. Die Studie zeigt, dass volumetrische Simulationen mit Volumen-Penalisierung, sofern der Gitterabstand nach den abgeleiteten Richtlinien gewählt wird, analytische Lösungen und gemessene Ohrdaten bis in die Nähe oder innerhalb gerade noch wahrnehmbarer Unterschiede treffen können. Praktisch bringt uns das der Fähigkeit näher, hochrealistische, hörerspezifische 3D-Klangbilder zu berechnen — ohne jedes Ohr im Labor messen zu müssen.
Zitation: Hölter, A.B., Lemke, M., Weinzierl, S. et al. Modeling head- and pinna-related transfer functions using boundary elements and finite differences with volume penalization. npj Acoust. 2, 16 (2026). https://doi.org/10.1038/s44384-026-00052-x
Schlüsselwörter: kopfbezogene Übertragungsfunktionen, 3D-Audio, numerische Akustik, Simulation der Außenohr, Sound für virtuelle Realität