Clear Sky Science · de
Effiziente Mehrstrukturen-Segmentierung bei kardialer MRT für die kardiovaskuläre Beurteilung mit begrenzter Annotation durch Integration von Daten- und Netzwerk-Konsistenz
Warum diese Forschung für die Herzgesundheit wichtig ist
Herz-MRT-Aufnahmen können lebenswichtige Details darüber liefern, wie gut das Herz pumpt. Damit diese detaillierten Bilder jedoch zu für Ärzte nutzbaren Zahlen werden, ist meist eine zeitaufwändige manuelle Nachzeichnung durch Expertinnen und Experten erforderlich. Diese Studie stellt eine Methode der künstlichen Intelligenz (KI) vor, die lernen kann, wichtige Herzstrukturen präzise zu umreißen, selbst wenn nur ein kleiner Teil der Scans sorgfältig von Spezialisten beschriftet ist. Durch die effiziente Nutzung der vielen nicht annotierten Scans, die bereits in Krankenhäusern vorliegen, könnte der Ansatz fortgeschrittene Herzanalysen schneller, kostengünstiger und breiter zugänglich machen.
Rohdaten der Herzscans in brauchbare Messwerte verwandeln
Um zu verstehen, wie ein Herz arbeitet, betrachten Kardiologen mehrere Strukturen in MRT-Bildern, einschließlich der Hauptkammern und der Muskelwand. Daraus berechnen sie Volumina, Herzmuskelmasse und die Kontraktionskraft des Herzens – Kennzahlen, die Diagnose, Behandlungsentscheidungen und Langzeitüberwachung bei Erkrankungen wie Herzinsuffizienz und Kardiomyopathie leiten. Heute werden diese Strukturen oft manuell oder mit Software nachgezeichnet, die weiterhin enge Aufsicht benötigt. Die neue Methode zielt darauf ab, diesen Schritt weitgehend zu automatisieren, sodass die Umrisse des linken Ventrikels, des rechten Ventrikels und des umgebenden Herzmuskels für jeden Patienten schnell und konsistent erzeugt werden können.
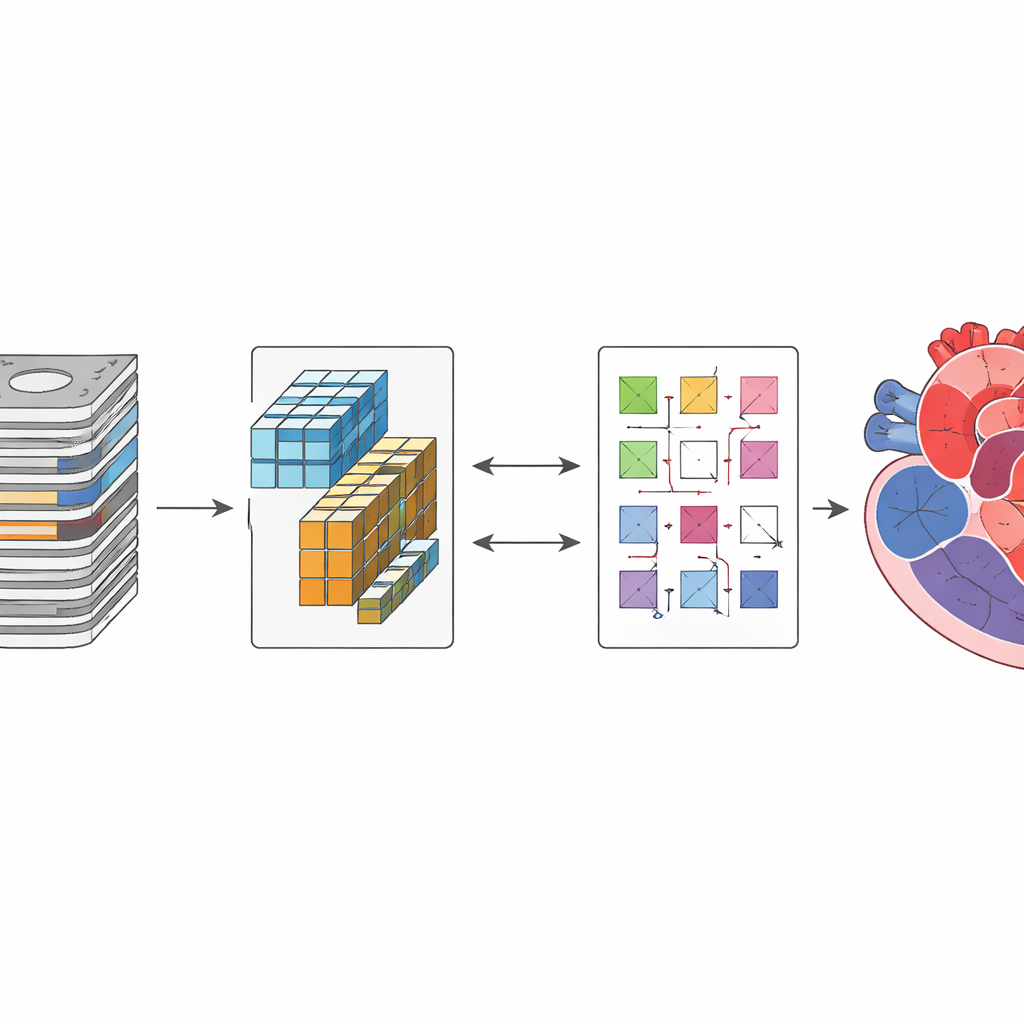
Computern mit wenigen Beispielen beibringen
Ein zentrales Hindernis beim Aufbau zuverlässiger medizinischer KI ist, dass die Modelle in der Regel tausende fachkundig annotierte Beispiele benötigen, und die Annotation eines einzelnen Herzscans kann Stunden dauern. Krankenhäuser verfügen jedoch bereits über große Bestände nicht annotierter Bilder. Die Forschenden begegneten diesem Problem mit einer semi-supervised Lernstrategie, bei der eine kleine Menge gelabelter Scans mit vielen ungelabelten kombiniert wird. Die KI lernt zunächst auf konventionelle Weise aus den gelabelten Bildern. Gleichzeitig wird sie behutsam dazu angeleitet, auf den ungelabelten Scans stabile, selbstkonsistente Vorhersagen zu liefern, sodass auch Bilder ohne Expertenmarkierungen zur Verfeinerung des Modells beitragen. Dieser Ansatz verringert die Abhängigkeit von teurer manueller Arbeit, während er das System zu anatomisch sinnvollen Ergebnissen führt.
Zwei unterschiedliche KI-„Blickwinkel“, die zusammenarbeiten
Das Framework, genannt SemiCoTr, verbindet zwei komplementäre Typen von Bildanalyse-Netzwerken. Eines, basierend auf klassischen Convolutional Neural Networks, ist gut darin, feine lokale Details zu erfassen. Das andere, aufgebaut auf moderner Transformer-Technologie, zeichnet sich dadurch aus, großräumige Beziehungen im gesamten Bild zu erkennen. In SemiCoTr betrachten beide Netzwerke dieselben Bilder und tauschen Informationen aus. Jedes Netzwerk behält eine langsam aktualisierte „Lehrer“-Version, deren Vorhersagen als stabiler Referenzpunkt für die sich schnell verändernde „Schüler“-Version dienen und so Konsistenz über die Zeit erzwingen. Zusätzlich beaufsichtigen sich die beiden Netzwerke gegenseitig: Wenn eines bei einer Struktur auf einem ungelabelten Scan sehr sicher ist, hilft dessen Vorhersage, das andere zu trainieren. Diese gegenseitige Anleitung sowohl auf Daten- als auch auf Netzwerkebene führt zu robusteren und anatomisch kohärenteren Herzumrissen.
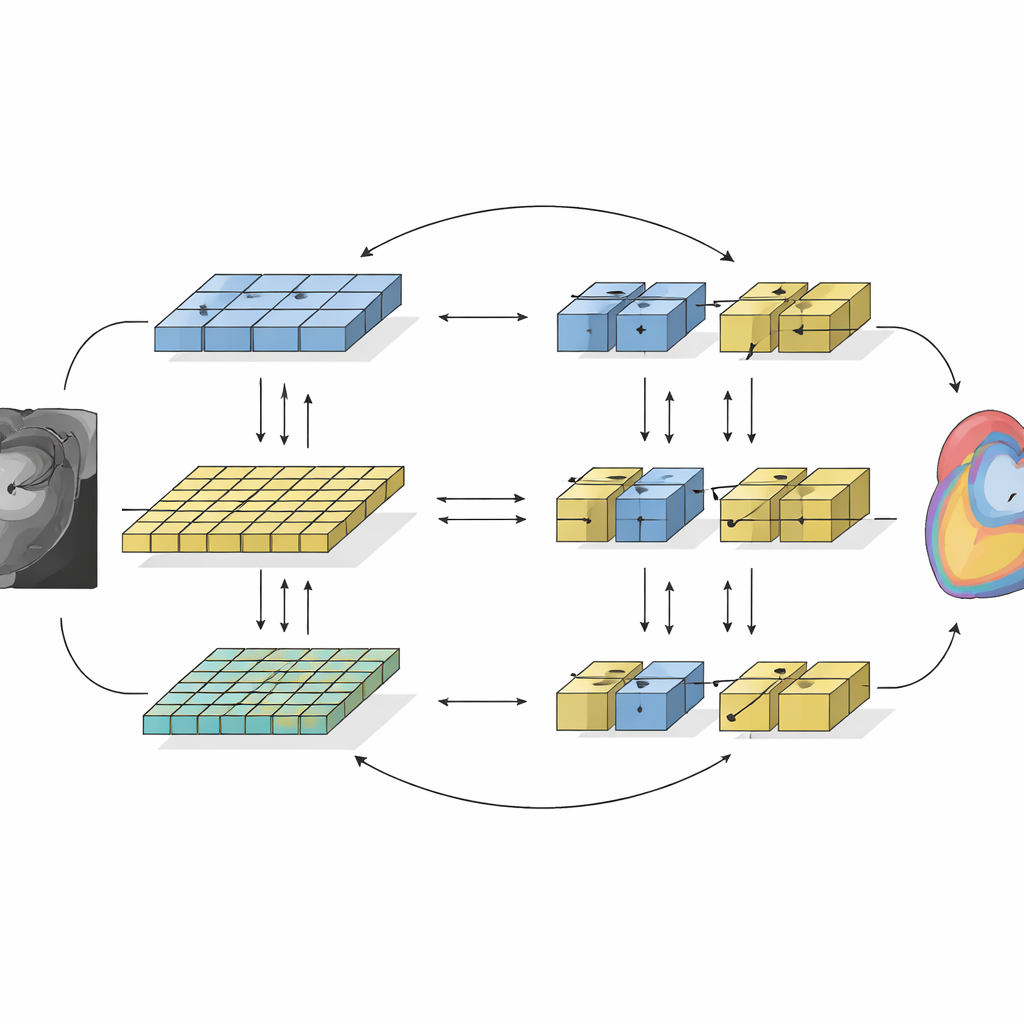
Wie gut funktioniert es tatsächlich?
Das Team testete seine Methode an einem öffentlichen Herz-MRT-Datensatz mit 100 Patientinnen und Patienten, der in der Forschungsgemeinschaft weit verbreitet ist. Sie simulierten ein realistisches Szenario, in dem nur 5–10 % der Scans von Expertinnen und Experten beschriftet waren und behandelten den Rest als ungelabelt. Mit zunehmender Menge an ungelabelten Daten stieg die Genauigkeit der automatischen Segmentierungen stetig und näherte sich der Leistung von Modellen an, die auf vollständig gelabelten Datensätzen trainiert wurden. Im Vergleich zu mehreren führenden semi-supervised Techniken erzielte ihr Ansatz durchgängig höhere Genauigkeit und sauberere Grenzen für alle drei wichtigen Herzstrukturen, blieb dabei jedoch rechnerisch praktikabel im Training. Sorgfältige Experimente zeigten, dass die Verbesserungen sowohl aus dem Multi-Teil-Verlustdesign als auch aus der Kombination der beiden unterschiedlichen Netzwerkgattungen resultierten.
Was das für Patientinnen, Patienten und Kliniken bedeutet
Die Studie zeigt, dass hochwertige Herzmessungen aus der MRT mit deutlich weniger manueller Annotation erzielt werden können, als zuvor für notwendig gehalten. Indem bessere Nutzung der ungelabelten Scans erfolgt, die Krankenhäuser täglich erzeugen, weist SemiCoTr auf skalierbare KI-Werkzeuge hin, die präzise, reproduzierbare Herzbewertungen in vielbeschäftigten klinischen Umgebungen liefern können. Langfristig könnten solche Systeme Ärztinnen und Ärzten helfen, subtile Herzprobleme früher zu erkennen, Behandlungen individueller anzupassen und den Krankheitsverlauf zuverlässiger zu verfolgen – und das alles, ohne die Arbeitsbelastung bereits ausgelasteter Bildgebungsspezialistinnen und -spezialisten zu erhöhen.
Zitation: Guo, S., Zhao, X., Ren, J. et al. Efficient cardiac MRI multi-structure segmentation for cardiovascular assessment with limited annotation by integrating data-level and network-level consistency. npj Digit. Med. 9, 328 (2026). https://doi.org/10.1038/s41746-026-02475-y
Schlüsselwörter: kardiale MRT, medizinische Bildsegmentierung, semi-supervised Learning, Deep Learning, kardiovaskuläre Bildgebung