Clear Sky Science · de
Genomeweite Feinabstimmung verbessert die Identifikation kausaler Varianten
Warum das Auffinden echter genetischer Signale wichtig ist
Viele häufige Merkmale — von Körpergröße und Körpergewicht bis zu Schizophrenie und Morbus Crohn — werden von Tausenden winziger DNA-Veränderungen beeinflusst, die über unser Genom verteilt sind. Moderne Studien können Bereiche der DNA ausmachen, die mit einem Merkmal verknüpft sind, doch oft nicht, welche konkreten Veränderungen in diesen Bereichen tatsächlich die Ursache sind. Dieses Papier stellt eine neue Methode vor, mit der das gesamte Genom gleichzeitig durchsucht werden kann, um die wahrscheinlichsten kausalen Veränderungen zu identifizieren und Forschern zu helfen, von groben „Nachbarschaften“ des Interesses zu präzisen „Hausnummern“ in unserer DNA zu gelangen.
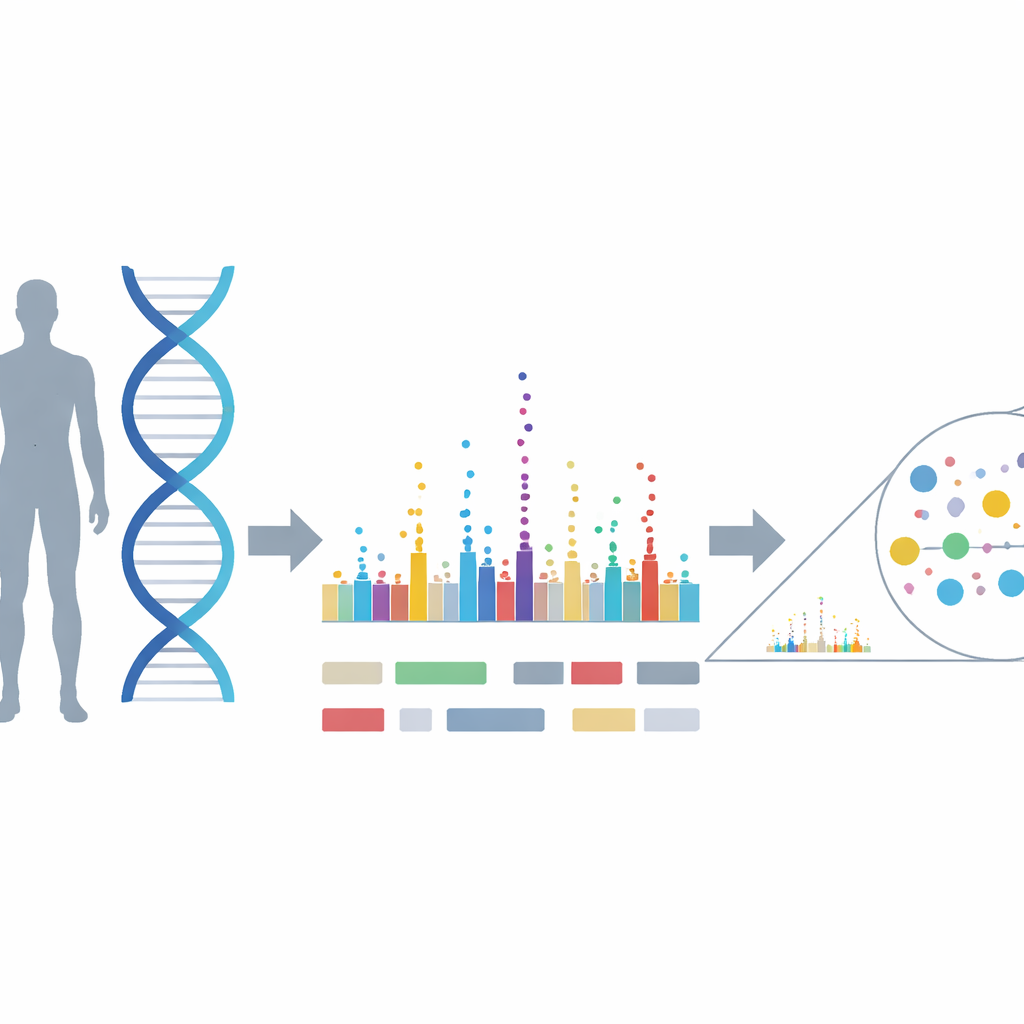
Von groben Karten zu präzisen Orten
Standardmäßige genomweite Assoziationsstudien (GWAS) suchen nach statistischen Verknüpfungen zwischen Millionen von DNA-Markern und einem Merkmal und erzeugen ein skyline-ähnliches Diagramm von Spitzen über die Chromosomen. Jede Spitze markiert eine Nachbarschaft, in der mehrere nahe beieinanderliegende Marker alle mit dem Merkmal verknüpft erscheinen, weil sie tendenziell zusammen vererbt werden. Das macht es schwer zu erkennen, welcher Marker — oder welche Kombination von Markern — tatsächlich verantwortlich ist. Traditionelle Fine-Mapping-Methoden zoomen jeweils nur auf eine Region, meist nur auf die höchsten Spitzen, und analysieren diese Fenster separat. Diese Strategie lässt viele echte, aber schwächere Signale außer Acht, gerät in verwobenen DNA-Regionen ins Straucheln und gibt wenig Orientierung dafür, wie groß zukünftige Studien sein müssen, um mehr kausale Veränderungen aufzudecken.
Ein genomweiter Ansatz zur Präzisierung von Varianten
Die Autoren stellen einen "genomweiten Fine-Mapping"-Ansatz vor, der alle häufigen DNA-Marker im Genom gleichzeitig analysiert. Ihr zentrales Werkzeug, SBayesRC genannt, verwendet ein bayesianisches Mischmodell: Anstatt anzunehmen, jeder Marker sei entweder wichtig oder nicht, erlaubt es, dass Marker in mehrere Effektgrößenkategorien fallen, von null bis groß. Entscheidend ist, dass es Informationen aus funktionellen genomischen Daten einbezieht — etwa ob ein Marker in einem Gen, einer regulatorischen Region oder einer konservierten DNA-Strecke liegt — und so die Wahrscheinlichkeit biologisch plausibler Kandidaten erhöht. Indem alle Marker gemeinsam angepasst und aus diesen Annotationen gelernt wird, kann die Methode genauer abschätzen, welche Veränderungen wahrscheinlich kausal sind und wie groß ihre Effekte sind.
Leistungsprüfung in Simulationen und realen Merkmalen
Durch umfangreiche Computersimulationen, die auf echten menschlichen genetischen Daten basieren, verglich das Team ihren genomweiten Ansatz mit weit verbreiteten regionenweisen Werkzeugen. Sie zeigten, dass SBayesRC besser kalibrierte Wahrscheinlichkeiten für jeden Marker liefert, einen größeren Anteil der echten kausalen Veränderungen erfasst und weniger Marker in seinen „crediblen Sets“ benötigt — den kleinen Gruppen von Kandidaten, die am wahrscheinlichsten die kausale Variante enthalten. Bei Anwendung auf reale Daten aus dem UK Biobank sowie großen Studien zu psychiatrischen und immunologischen Erkrankungen identifizierte die Methode Varianten, die in unabhängigen Stichproben häufiger repliziert wurden und Merkmale genauer vorhersagten, selbst über verschiedene Abstammungsgruppen hinweg. Sie fand zudem systematisch wichtige Varianten außerhalb der Regionen, die den traditionellen strengen GWAS-Signifikanzschwellen genügen, und enthüllte Signale, die Standardanalysen übersehen würden.
Einblick, wie viel Erblichkeit wir erfassen können
Weil SBayesRC die gesamte genetische Architektur schätzt — die Zahl kausaler Varianten und wie deren Effekte verteilt sind — kann es zur Prognose genutzt werden. Die Autoren entwickelten einen Power-Rechner, der vorhersagt, wie viele kausale Varianten bei einer gegebenen zukünftigen Stichprobengröße voraussichtlich lokalisiert werden können und welchen Anteil der genetischen Einflussnahme eines Merkmals (seiner SNP-basierten Heritabilität) diese Varianten erklären sollten. Damit schätzen sie, dass Studien mit rund zwei Millionen Teilnehmern typischerweise Varianten feinabstimmen könnten, die mehr als die Hälfte der gemeinsamen genetischen Komponente vieler Merkmale erklären. Sie zeigen auch, dass einige Merkmale, etwa Blutbildwerte, leichter zu fine-mappen sind als stark polygenetische Merkmale wie kognitive Fähigkeiten, die möglicherweise noch größere Stichproben erfordern.
Konkrete Beispiele kausaler Varianten
Die Autoren heben konkrete DNA-Veränderungen hervor, um den Nutzen der Methode zu veranschaulichen. In der bekannten FTO-Region, die mit Adipositas verknüpft ist, priorisiert der genomweite Fine-Mapping-Ansatz korrekt eine Variante, die zuvor in Laborstudien nachgewiesen wurde und die Fettstoffwechsel beeinflusst, unterstützt durch Konservierungssignale über Artengrenzen hinweg. Bei Schizophrenie stuft die Methode seltene, aber funktionell überzeugende Veränderungen in Genen ein, die an der Struktur und Signalgebung von Gehirnzellen beteiligt sind, einschließlich Varianten in ACTR1B und SLC39A8, die starke Unterstützung durch Protein- und Zelltypdaten haben. Bei Morbus Crohn findet sie zusätzliche wahrscheinliche kausale Varianten, die unter den klassischen GWAS-Schwellen liegen, aber biologisch sinnvoll sind, wenn umliegende Marker gemeinsam berücksichtigt werden.
Was das für zukünftige genetische Studien bedeutet
Insgesamt zeigt die Studie, dass die gleichzeitige Analyse des gesamten Genoms bei gleichzeitiger Integration funktioneller Hinweise unsere Sicht darauf schärfen kann, welche DNA-Veränderungen für komplexe Merkmale wirklich relevant sind. Anstatt GWAS als Liste breiter Regionen zu behandeln, verwandelt dieser Ansatz sie in eine hochauflösende Karte und offenbart, welche Varianten eine weitergehende experimentelle Prüfung und Arzneimittelentwicklung verdienen. Indem er außerdem prognostiziert, wie viel mehr mit wachsender Stichprobengröße gelernt werden kann, liefert die Arbeit eine Roadmap für die Planung zukünftiger genetischer Studien, die uns näher an das Verstehen und letztlich an das Eingreifen in die Biologie häufiger Erkrankungen bringt.
Zitation: Wu, Y., Zheng, Z., Thibaut, L. et al. Genome-wide fine-mapping improves identification of causal variants. Nat Genet 58, 940–951 (2026). https://doi.org/10.1038/s41588-026-02549-3
Schlüsselwörter: genomeweite Feinabstimmung, kausale genetische Varianten, komplexe Merkmale, funktionelle genomische Annotationen, GWAS-Methoden