Clear Sky Science · zh
基于 DISC 的人格与胜任力分析的图聚类与预测模型
为何你的职场数据会讲述一个故事
大多数组织都会收集大量关于员工的信息:人格测验结果、技能、岗位角色,甚至自述的压力状况。该研究展示了如何将这些分散的数据编织成一幅员工相互相似性的地图,揭示隐藏的群体以及可能在工作中感到压力的线索。研究以流行的 DISC 人格框架为核心,提出了一个简单却重要的问题:我们能从人格风格报告走多远,以获得关于压力和团队需求的有用数据驱动洞见——以及这些方法的局限在哪里?
从色彩编码到连接模式
研究者从 DISC 出发,这一模型按照一般行为风格将人群分组,例如更具驱动力、以人为中心、稳重或注重细节。在一所大学组织中,195 名员工完成了基于 DISC 的评估,评估还对 17 项与工作相关的技能给出评分,列出突出优点与较弱特质,并记录了他们的压力水平。研究团队没有把这些个人档案视为孤立的分数,而是把每名员工当作网络中的一个节点,两个员工之间的接近程度取决于他们在技能、角色和特质上的相似性。
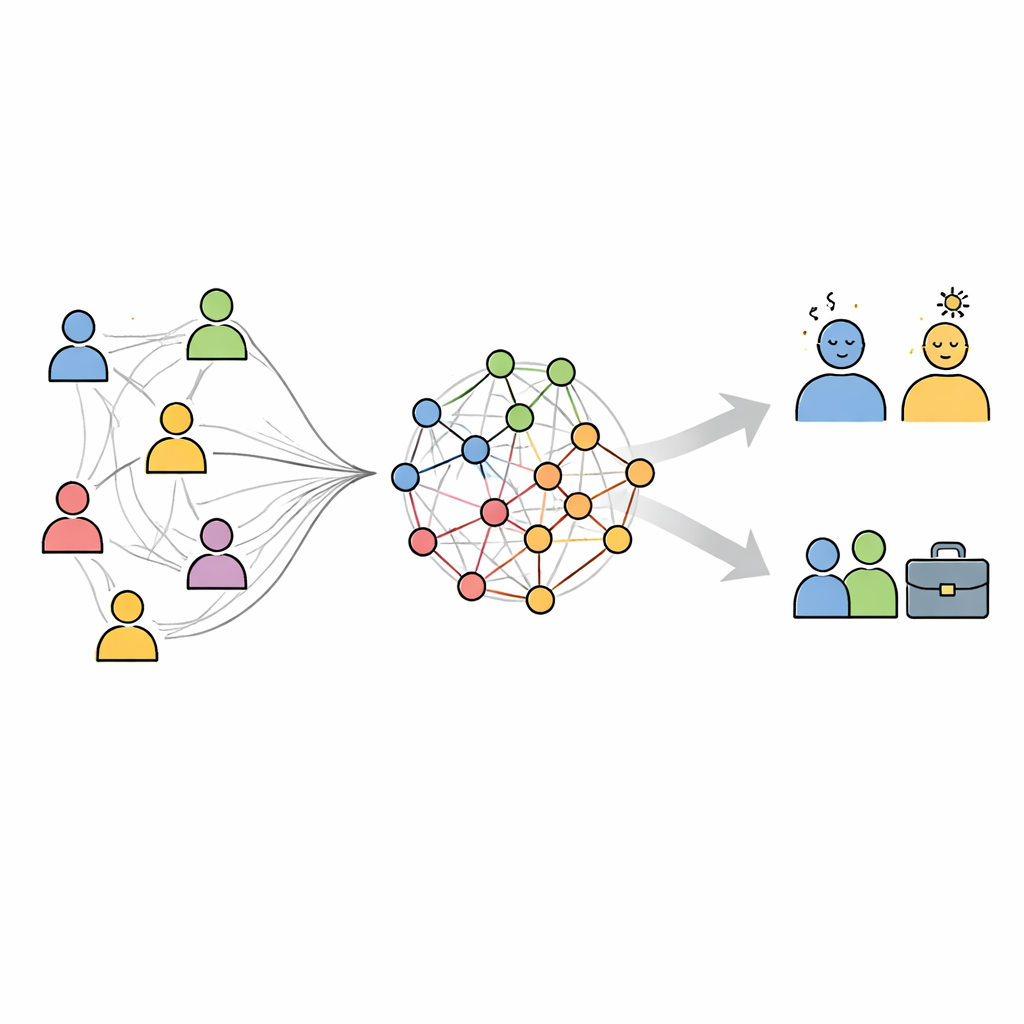
构建“谁像谁”的地图
为绘制该网络,作者结合了三类相似性。他们衡量了人们在技能评分上的相似度、组织信息(如所在部门或任务类型)的一致程度,以及特质描述的重叠程度。这三种要素被融合为每对员工的单一相似度分数。随后每个人都与其最相似的同事相连,形成一张以更粗连线表示更高相似度的网络。社区发现算法在这张网络中搜索自然形成的簇——那些内部连接比与组织其余部分更紧密的人员群体。
隐藏群体及其压力构成
生成的网络远非随机。这一方法发现了六个员工社区,每个社区在 DISC 风格和压力水平上都有各自的混合。有些群体包含大量“组织者”或“分析师”类型,而另一些则更为混杂。研究还发现,这些簇在不同压力水平的分布上存在差异,表明行为风格、技能与角色背景的组合往往一起出现。这为人力资源团队提供了在群体层面考虑干预的途径,例如针对性培训或审视特定簇的工作量,而不是仅仅孤立地关注个体。
尝试从个人档案预测压力
作者随后从绘图转向预测。使用一种常见的机器学习方法——随机森林,他们尝试根据员工的 DISC 类型、技能、特质与组织信息来猜测每位员工的压力类别(低、中、高,或高且明确与工作相关)。模型的表现优于纯随机猜测,但不如一种非常简单的策略——始终预测多数类(即低压)。换言之,人格与胜任力数据中确实包含一些信号,但决定压力的许多因素似乎位于其他地方——例如变化的截止日期、个人生活事件或未被一次性问卷捕捉到的团队关系变动。

真正驱动工作压力的因素
尽管有局限,预测模型仍突显出一些耐人寻味的模式。与销售目标和客户关系相关的技能评分是在算法区分不同压力水平时最重要的输入之一。这与常见经验相符:以结果和客户接触为核心的角色通常伴随额外压力。研究还进行了另一项“预测”胜任力组标签的练习,取得了近乎完美的分数——但这里的目标标签本质上是基于与输入相同的信息构建的,这是信息泄露的典型案例,在论文中看起来很亮眼,但并不具备泛化性。
这对个人与团队的重要性
对普通读者而言,关键信息是:人格与技能测试不仅能把你放进一个整齐的字母框;经过谨慎组合,它们可以揭示你在更广泛职场结构中的位置。与此同时,研究也提醒我们不要过于自信:压力并非可以从人格图谱中可靠地读出。相似性网络图或许能帮助组织发现有意义的群体并思考团队培训或平衡问题,但关于员工福祉的重大决策仍需更丰富、持续的信息,最重要的是直接的人际沟通。
引用: Samanta, S., Allahviranloo, T., Mrsic, L. et al. Graph clustering and prediction models for DISC-based personality and competency analysis. Sci Rep 16, 10186 (2026). https://doi.org/10.1038/s41598-026-41013-4
关键词: 职场压力, 人格评估, 团队动态, 组织分析, 员工胜任力